From: Lynn Wheeler <lynn@garlic.com> Subject: DUMP Reader Date: 01 Jan, 2026 Blog: FacebookEarly in days of REX, before being renamed REXX and released to customers, I wanted to show that REX wasn't just another pretty scripting language. I chose rewriting IPCS (online dump analyzer done in huge amount of assembler) ... working half time over a few weeks w/objective to have ten times the function and ten times the performance (slight of hand & hacks for interpreted REX faster than assembler) ... I finished early so added automated scripts that looked for most common failure signatures.
I then thought it could be released to customers (in place of IPCS), but for what ever reason it wasn't ... even though nearly every internal datacenters and customer support PSRs were using it. Eventually I got permission to give presentations at customer user group meetings on how I implemented it ... and within a few months customer implementations started to appear.
Later the 3092 (3090 service processor, started out 4331 running modified version of VM370R6, all service screens done in CMS IOS3270 ... before release, the 4331 was upgraded to a pair of 4361s) solicited to ship with the service processor.
dumprx posts
https://www.garlic.com/~lynn/submain.html#dumprx
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: 43 Years Of TCP/IP Newsgroups: alt.folklore.computers Date: Thu, 01 Jan 2026 15:27:07 -1000Peter Flass <Peter@Iron-Spring.com> writes:
I was on Chessin's XTP TAB 2nd part of the 80s and there were some gov/mil (including SAFENET2) so we took it to X3S3.3 ... but eventually got told that ISO had rule they could only standardize stuff that conformed to OSI Model.
XTP didn't because 1) supported internetworking which didn't exist in OSI, 2) bypassed network/transport interface, 3) went directly to LAN/MAC interface which doesn't exist in OSI.
there was joke that while (internet) IETF had rule to proceed in standards process, there needed to be two interoperable implementations, while ISO didn't even require a standard be implementable.
co-worker at the science center was responsible for the 60s CP67-based science centers wide-area network that morphs into the corporate internal network (larger than arpanet/internet from just about the beginning until sometime mid/late 80s, about the time it was forced to convert to SNA/VTAM).
comment by one of the 1969 GML inventors at the science center
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
...
newspaper article about some of Edson's Internet & TCP/IP IBM battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed, Internet &
TCP/IP) references from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
IBM internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
XTP/HSP posts
https://www.garlic.com/~lynn/subnetwork.html#xtphsp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: 43 Years Of TCP/IP Newsgroups: alt.folklore.computers Date: Thu, 01 Jan 2026 15:36:39 -1000Lawrence D'Oliveiro <ldo@nz.invalid> writes:
For a time I reported to same executive as person responsible for AWP164 (which had some peer-to-peer) that morphs into (AS/400) APPN. I told him that he should come over to work on real networking (TCP/IP) because the SNA forces would never appreciate him.
When AS/400 went to announce APPN, the SNA forces vetoed it and there was delay to carefully rewrite the announcement letter to not imply any relationship between APPN & SNA. It wasn't until much later that documents were rewritten to imply that somehow APPN came under the SNA umbrella.
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: 43 Years Of TCP/IP Newsgroups: alt.folklore.computers Date: Fri, 02 Jan 2026 08:27:29 -1000Lynn Wheeler <lynn@garlic.com> writes:
late 80s, a senior disk engineer got a talk scheduled at internal, world-wide, annual communication group conference, supposedly on 3174 performance. However, his opening was that the communication group was going to be responsible for the demise of the disk division. The disk division was seeing drop in disk sales with data fleeing mainframe datacenters to more distributed computing friendly platforms. The disk division had come up with a number of solutions, but they were constantly being vetoed by the communication group (with their corporate ownership of everything that crossed the datacenter walls) trying to protect their dumb terminal paradigm. Senior disk software executive partial countermeasure was investing in distributed computing startups that would use IBM disks (he would periodically ask us to drop in on his investments to see if we could offer any assistance).
The communication group's stranglehold on mainframe datacenters wasn't
just disks and a couple years later, IBM has one of the largest losses
in the history of US companies ... and was being reorganized into the
13 "baby blues" (take-off on the "baby bells" breakup a decade
earlier) in preperation for breaking up IBM.
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
other trivia: in the early 80s, I was funded for HSDT project, T1 and
faster computer links (both terrestrial and satellite) and battles
with SNA group (60s, IBM had 2701 supporting T1, 70s with SNA/VTAM and
issues, links were capped at 56kbit ... and I had to mostly resort to
non-IBM hardware). Also was working with NSF director and was suppose
to get $20M to interconnect the NSF Supercomputer centers. Then
congress cuts the budget, some other things happened and eventually
there was RFP released (in part based on what we already had
running). NSF 28Mar1986 Preliminary Announcement (from old archived
a.f.c post):
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers Program
to provide Supercomputer cycles; the New Technologies Program to foster
new supercomputer software and hardware developments; and the Networking
Program to build a National Supercomputer Access Network - NSFnet.
... snip ...
... IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet. Note RFP had called for T1 links, however winning bid put in 440kbit/sec links ... then to make it look something like T1, they put in T1 trunks with telco multiplexors running multiple 440kbit/sec links over T1 trunks.
When director left NSF, he went over to K (H?) street lobby group (council on competitiveness) and we would try and periodically drop in on him
demise of disk division and communication group stranglehold posts
https://www.garlic.com/~lynn/subnetwork.html#emulation
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: 43 Years Of TCP/IP Newsgroups: alt.folklore.computers Date: Fri, 02 Jan 2026 13:27:04 -1000Al Kossow <aek@bitsavers.org> writes:
TCP had minimum 7 packet exchange and XTP defined a reliable transaction with minimum of 3 packet exchange. Issue was that TCP/IP was part of kernel distribution requiring physical media (and typically some expertise for complete system change/upgrade; browsers and webservers were self contained load&go).
XTP also defined things like trailer protocol where interface hardware could do CRC as packet flowing through and do the append/check ... helping minimize packet fiddling (as well as other pieces of protocol offloading, Chessin also liked to draw analogies with SGI graphic card process pipelining). Problem was that there were lots of push back (part of claim at the time HTTPS prevailing over IPSEC) for any kernel change prereq.
topic drift ... 1988, HA/6000 was approved, initially for NYTimes to
migrate their newspaper system off DEC VAXCluster to RS/6000. I rename
it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive Hester tells Ellison that we would have 16-system clusters by mid92 and 128-system clusters by ye92. Mid Jan92, convince IBM FSD to bid HA/CMP for gov. supercomputers. Late Jan92, cluster scale-up is transferred for announce as IBM Supercomputer (for technical/scientific *ONLY*) and we are told we can't do clusters with anything that involve more than four systems (we leave IBM a few months later).
Partially blamed FSD going up to the IBM Kingston supercomputer group
to tell them they were adopting HA/CMP for gov. bids (of course
somebody was going to have to do it eventually). A couple weeks later,
17feb1992, Computerworld news ... IBM establishes laboratory to
develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Not long after leaving IBM, was brought in as consulatnt to small client/server startup, two former Oracle people (that had worked on HA/CMP and were in the Ellison/Hester meeting) are there responsible for something called "commerce server" and they want to do payment transactions. The startup had also invented this stuff they called "SSL" they want to use, it is now frequently called "e-commerce". I had responsibility between web servers and payment networks, including the payment gateways.
One of the problems with HTTP&HTTPS were transactions built on top of TCP ... implementation that sort of assumed long lived sessions (made it easier to install on top kernel TCP/IP protocol stack). As webserver workload ramped up, web servers were starting to spend 95+% of CPU running FINWAIT list. NETSCAPE was increasing number of servers and trying to spread the workload. Eventually NETSCAPE installs a large multiprocessor server from SEQUENT (that had also redone DYNIX FINWAIT processing to eliminate that non-linear increase in CPU overhead).
XTP had provided for piggy-back transaction processing to keep packet
exchange overhead to minimum ... and I showed HTTPS over XTP in the
minimum 3-packet exchange (existing HTTPS had to 1st establish TCP
session, then establish HTTPS, then the transaction, then shutdown
session).
https://en.wikipedia.org/wiki/Xpress_Transport_Protocol
other trivia: I then did a talk on "Why Internet Isn't Business Critical Dataprocessing" based on documentation, processes and software I had to do for e-commerce, which (IETF RFC editor) Postel sponsored at ISI/USC.
more trivia: when 1st started doing TCP/IP over high-speed satellite links, established dynamic adaptive rate-based pacing implementation ... which I also got written into the XTP spec.
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
XTP/HSP posts
https://www.garlic.com/~lynn/subnetwork.html#xtphsp
posts mentioning dynamic adaptive rate-based pacing
https://www.garlic.com/~lynn/2025c.html#46 IBM Germany and 370/125
https://www.garlic.com/~lynn/2025b.html#114 ROLM, HSDT
https://www.garlic.com/~lynn/2025b.html#81 IBM 3081
https://www.garlic.com/~lynn/2025b.html#18 IBM VM/CMS Mainframe
https://www.garlic.com/~lynn/2025.html#114 IBM 370 Virtual Memory
https://www.garlic.com/~lynn/2025.html#36 IBM ATM Protocol?
https://www.garlic.com/~lynn/2025.html#35 IBM ATM Protocol?
https://www.garlic.com/~lynn/2024f.html#116 NASA Shuttle & SBS
https://www.garlic.com/~lynn/2024e.html#28 VMNETMAP
https://www.garlic.com/~lynn/2024d.html#71 ARPANET & IBM Internal Network
https://www.garlic.com/~lynn/2024c.html#58 IBM Mainframe, TCP/IP, Token-ring, Ethernet
https://www.garlic.com/~lynn/2023f.html#16 Internet
https://www.garlic.com/~lynn/2023b.html#53 Ethernet (& CAT5)
https://www.garlic.com/~lynn/2022f.html#27 IBM "nine-net"
https://www.garlic.com/~lynn/2022e.html#27 IBM "nine-net"
https://www.garlic.com/~lynn/2022d.html#73 WAIS. Z39.50
https://www.garlic.com/~lynn/2022d.html#29 Network Congestion
https://www.garlic.com/~lynn/2022c.html#80 Peer-Coupled Shared Data
https://www.garlic.com/~lynn/2022c.html#22 Telum & z16
https://www.garlic.com/~lynn/2021k.html#110 Network Systems
https://www.garlic.com/~lynn/2021j.html#16 IBM SNA ARB
https://www.garlic.com/~lynn/2021i.html#71 IBM MYTE
https://www.garlic.com/~lynn/2021h.html#49 Dynamic Adaptive Resource Management
https://www.garlic.com/~lynn/2021c.html#83 IBM SNA/VTAM (& HSDT)
https://www.garlic.com/~lynn/2018b.html#16 Important US technology companies sold to foreigners
https://www.garlic.com/~lynn/2017d.html#28 ARM Cortex A53 64 bit
https://www.garlic.com/~lynn/2013n.html#31 SNA vs TCP/IP
https://www.garlic.com/~lynn/2008l.html#64 Blinkylights
https://www.garlic.com/~lynn/2008e.html#28 MAINFRAME Training with IBM Certification and JOB GUARANTEE
https://www.garlic.com/~lynn/2006g.html#18 TOD Clock the same as the BIOS clock in PCs?
https://www.garlic.com/~lynn/2006d.html#21 IBM 610 workstation computer
https://www.garlic.com/~lynn/2005q.html#22 tcp-ip concept
https://www.garlic.com/~lynn/2005g.html#4 Successful remote AES key extraction
https://www.garlic.com/~lynn/2004k.html#29 CDC STAR-100
https://www.garlic.com/~lynn/2004k.html#13 FAST TCP makes dialup faster than broadband?
https://www.garlic.com/~lynn/2004k.html#12 FAST TCP makes dialup faster than broadband?
https://www.garlic.com/~lynn/93.html#29 Log Structured filesystems -- think twice
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: PROFS and other CMS applications Date: 03 Jan, 2026 Blog: FacebookSome of the MIT CTSS/7094 people
Others went to the IBM cambridge science center on the 4th floor, modified 360/40 with virtual memory hardware and did CP/40, which morphs into CP/67 when 360/67 standard with virtual memory becomes available ... also invented GML (letters after inventors last names) in 1969 (after a decade it morphs into ISO standard SGML and after another decade morphs into HTML at CERN). In early 70s, after decision to add virtual memory to all 370s, some of CSC splits off and takes over the IBM Boston Programming Center on the 3rd flr, for the VM370 development group.
MIT CTSS RUNOFF
https://en.wikipedia.org/wiki/TYPSET_and_RUNOFF
had been ported to CP67/CMS as SCRIPT (later GML tag processing added
to SCRIPT) ... later release renamed DCF. there was also form email on
MIT CTSS
https://multicians.org/thvv/mail-history.html
Edson
https://en.wikipedia.org/wiki/Edson_Hendricks
responsible for the science center wide-area network (VNET/RSCS) which
morphs into the IBM internal corporate network (larger than
arpanet/internet from the beginning until sometime mid/late 80s about
the time it was forced to convert to SNA/VTAM), technology also used
for the corporate sponsored univ BITNET (& EARN in Europe). Comment by
one of the CSC inventors of GML
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
newspaper article about some of Edson's IBM TCP/IP battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed) references
from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
PROFS group had been collecting some internal apps for wrapping 3270 menus around, one of which was very early version of VMSG for the email client. When the VMSG author tried to offer them a much enhanced version, they tried to have him separated from the company. The whole thing quieted down when he demonstrated his initials was in every PROFS email (in non-displayed field). After that he only shared his source with me and one other person.
When I graduated and joined science center, one of my hobbies was enhanced production operating systems for internal datacenters and the online sales&marketing support HONE systems was one of the first and long time customers (1st CP67 later VM370). One of my 1st non-US IBM trips in early 70s was HONE asked me to do CP67 install in La Defense, Paris in the early 70s (and at the time, it took a little investigation on how to access my email back in the states).
Late 70s & early 80s I was blamed for online computer conferencing on
the internal network. It really took off the spring of 1981 when I
distributed a trip report to visit Jim Gray at Tandem (had left SJR
fall1980). Only about 300 directly participated but claims that 25,000
were reading. From IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
Six copies of 300 page extraction from the memos were printed and put in Tandem 3ring binders and sent to each member of the executive committee, along with executive summary and executive summary of the executive summary (folklore is 5of6 corporate executive committee wanted to fire me).
Then there was some number of internal IBM task forces, official sanctioned IBM software (VMTOOLS) and approved FORUMS with official moderators. There was researcher hired to study how I communicated, spent nine months in the back of my office, took notes on face-to-face, telephone, etc converstations, got copies of all my incoming and outgoing email, and logs of all instant messages. The material was also used for conference talks and papers, books and Stanford Phd, joint between language and computer AI (Winograd was advisor on computer side).
Pisa Scientific Center did "SPM" for CP/67, which was later imported to (internal) VM/370 ... and use implemented in RSCS/VNET (even version shipped to customers) ... sort of superset of the combination of VM/370 VMCF, IUCV, & SMSG (in the product). Circa 1980, a CMS 3270, mult-user, client/server spacewar was implemented and since supported by RSCS/VNET, user clients could play from anywhere in the world on the internal network. Almost immediately robot players appeared beating human players (faster response time) and server was modified to increase power use non-linear when responses starting dropping below human response time.
At the time my VM370 for internal datacenters were getting .11sec interactive response. Players with 3272/3277 had .086sec hardware response for aggregate .196sec ... which would have advantage over users on systems that had quarter second system response and/or 3278s which had .3-.5sec hardware response (combination could be .55-.75sec).
trivia: Kildall worked on (virtual machine) IBM CP/67 at npg
https://en.wikipedia.org/wiki/Naval_Postgraduate_School
before developing CP/M (name take-off on CP/67).
https://en.wikipedia.org/wiki/CP/M
which spawns Seattle Computer Products
https://en.wikipedia.org/wiki/Seattle_Computer_Products
which spawns MS/DOS
https://en.wikipedia.org/wiki/MS-DOS
IBM Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
BITNET (& EARN) posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: PROFS and other CMS applications Date: 04 Jan, 2026 Blog: Facebookre:
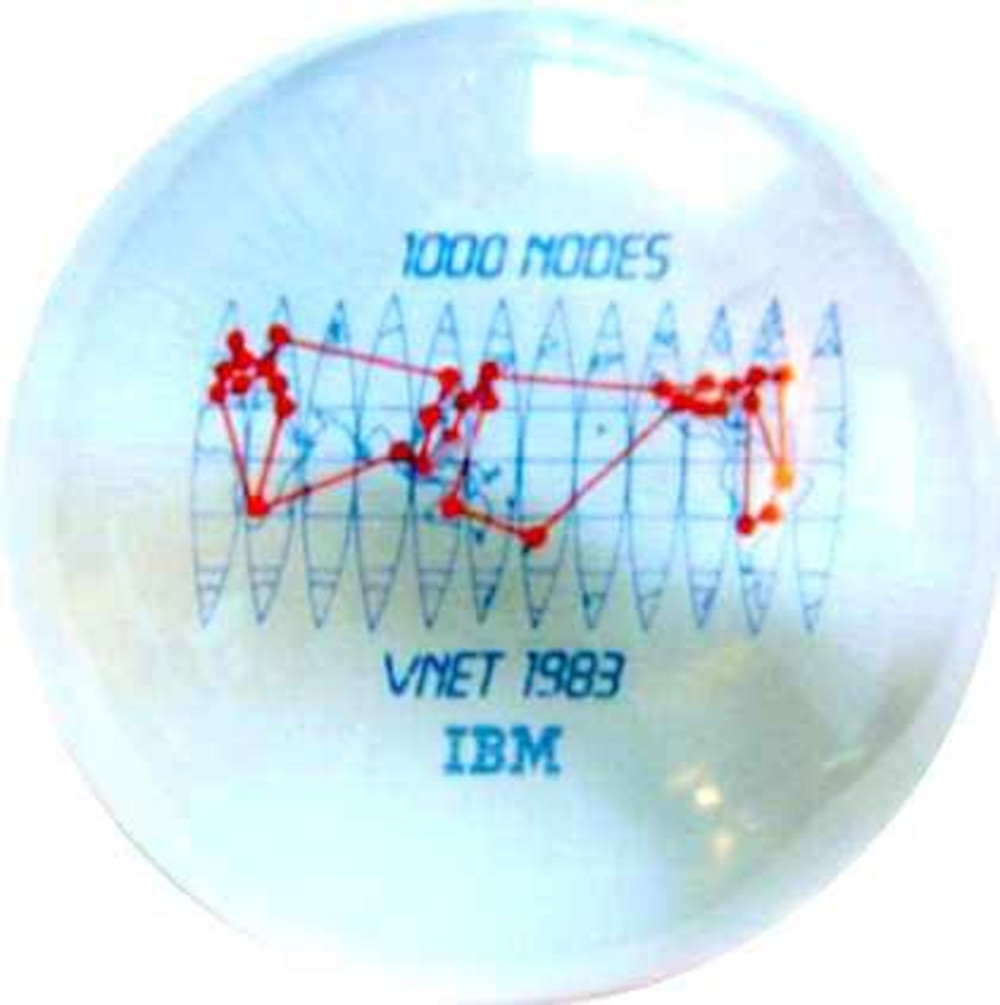
As science center CP67-based (RSCS/VNET) wide-area network started to morph into the internal corporate network, there had to be a HASP/JES2 NJE emulation driver to start to connect in the HASP(/JES2)-based systems ... which were limited to the edge of the internal network (behind CP67 and then VM370 systems). Part of the issue was RSCS/VNET had nice clean layered implmentation (which NJE didn't). The other part was that the HASP/JES2 NJE implementation (originally had "TUCC" in cols 68-71) used spare entries in the HASP 255 entry pseudo device table (typically 160-180) for network node definitions ... and by the time of VS2/MVS, the corporate network was already past 255 nodes, NJE trashing any traffic where either the origin or destination wasn't in its local table (later NJE was updated for max 999 nodes, but it was after the internal network had already passed 1000). The other reason for keeping MVS/JES2 on boundary nodes (and behind RSCS/VNET) was because JES2 traffic between systems at different version had habit of crashing the MVS system (requiring manual re-IPL) ... some of this was header had network and job fields intermixed. A body of RSCS/VNET NJE emulation code grew-up that was aware of different JES2 version field layout and could re-organize the header record to be acceptable to the directly receiving JES2 system (there is the infamous case of updated San Jose MVS/JES2 systems crashing Hursely MVS/JES2 systems, blamed on the Hursley RSCS/VNET group because they hadn't obtained the lastest updates to re-organize JES2 fields beween San Jose and Hursley).
The Arpanet 1Jan1983 cut-over from IMP/Host protocol to
internetworking (TCP/IP), there were approx 100 IMP network nodes and
255 hosts, at a time when the internal network was about to pass
1000. Old archived post with a list of world-wide corporate locations
that added one or more network nodes during 1983
https://www.garlic.com/~lynn/2006k.html#8
and IBM 1983 1000th node globe:
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
HASP/JES NJE/NJI posts
https://www.garlic.com/~lynn/submain.html#hasp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Cluster Supercomputer Tsunami Date: 05 Jan, 2026 Blog: FacebookSecond half of 70s, transfer to SJR and get to wander IBM (and non-IBM) datacenters in silicon valley, including disk bldg14/engineering and bldg15/product test across the street. They were running 7x24 prescheduled stand-alone mainframe testing and said that they had recently tried MVS, but it had 15min MTBF (in that environment) requiring manual re-ipl. I offer to rewrite I/O supervisor, making it bullet-proof and never fail, allowing any amount of on-demand concurrent testing, greatly improving productivity. Bldg15 gets 1st engineering 3033 outside POK processor engineering for channel disk I/O tesing. Then 1978 got engineering 4341. Jan1979 branch office hears about 4341 and cons me into doing benchmark for national lab looking at getting 70 for compute farm (sort of leading edge of the coming cluster supercomputing tsunami).
Decade later, 1988 get HA/6000 project, originally for NYTimes so they
could migrate their newspaper system ("ATEX") off DEC VAXCluster to
RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also port LLNL & NCAR supercomputer
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, informix that had DEC VAXCluster
support in same source base as unix; I do a distributed lock
manager/DLM with VAXCluster API and lots of scale-up improvements).
Early Jan1992, meeting with Oracle CEO, IBM AWD executive Hester tells
Ellison that we would have 16-system clusters mid92 and 128-system
clusters ye92. Mid-jan1992, convinced IBM FSD to bid HA/CMP for
gov. supercomputers. Late-jan1992, HA/CMP is transferred for announce
as IBM Supercomputer (for technical/scientific *ONLY*), and we were
told couldn't work on clusters with more than 4-systems (we leave IBM
a few months later). A couple weeks after cluster scale-up transfer,
17feb1992, Computerworld news ... IBM establishes laboratory to
develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
a few recent posts mentioning 4341 supercomputer leading edge tsunami
& ha/cmp
https://www.garlic.com/~lynn/2025e.html#112 The Rise Of The Internet
https://www.garlic.com/~lynn/2025e.html#44 IBM SQL/Relational
https://www.garlic.com/~lynn/2025e.html#35 Linux Clusters
https://www.garlic.com/~lynn/2025e.html#1 Mainframe skills
https://www.garlic.com/~lynn/2025d.html#98 IBM Supercomputer
https://www.garlic.com/~lynn/2025d.html#68 VM/CMS: Concepts and Facilities
https://www.garlic.com/~lynn/2025c.html#98 5-CPU 370/125
https://www.garlic.com/~lynn/2025c.html#40 IBM & DEC DBMS
https://www.garlic.com/~lynn/2025c.html#15 Cluster Supercomputing
https://www.garlic.com/~lynn/2025b.html#72 Cluster Supercomputing
https://www.garlic.com/~lynn/2025b.html#32 Forget About Cloud Computing. On-Premises Is All the Rage Again
https://www.garlic.com/~lynn/2025b.html#26 IBM 3880, 3380, Data-streaming
https://www.garlic.com/~lynn/2025b.html#22 IBM San Jose and Santa Teresa Lab
https://www.garlic.com/~lynn/2024g.html#76 Creative Ways To Say How Old You Are
https://www.garlic.com/~lynn/2021j.html#52 ESnet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Downfall Date: 06 Jan, 2026 Blog: Facebook1972, Learson tried (and failed) to block bureaucrats, careerists, and MBAs from destroying Watson culture/legacy, pg160-163, 30yrs of management briefings 1958-1988
Future System project 1st half 70s, imploded, from: Computer Wars: The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
FS completely different from 370 and going to completely replace it
(during FS, internal politics was killing off 370 efforts, limited new
370 is credited with giving 370 system clone makers their market
foothold). One of the final nails in the FS coffin was analysis by the
IBM Houston Science Center that if 370/195 apps were redone for FS
machine made out of the fastest available hardware technology, they
would have throughput of 370/145 (about 30 times slowdown)
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
trivia: I continued to work on 360&370 all during FS, periodically ridiculing what they were doing (drawing analogy with long playing cult film down at central sq; which wasn't exactly career enhancing activity)
Late 70s & early 80s I was blamed for online computer conferencing on
the internal network. It really took off the spring of 1981 when I
distributed a trip report to visit Jim Gray at Tandem (had left SJR
fall1980). Only about 300 directly participated but claims that 25,000
were reading. From IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
Six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore is 5of6 corporate executive
committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the company
is rapidly heading for disaster. Furthermore, people fear that this
movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their management
and with the way things are going in IBM. To an increasing extent,
people are reacting to this by leaving IBM. Most of the contributors
to the present discussion would prefer to stay with IBM and see the
problems rectified. However, there is increasing skepticism that
correction is possible or likely, given the apparent lack of
commitment by management to take action
• There is a widespread perception that IBM management has failed to
understand how to manage technical people and high-technology
development in an extremely competitive
... snip ...
About the same time, I was introduced to John Boyd in the early 80s and would sponsor his briefings at IBM
https://en.wikipedia.org/wiki/John_Boyd_(military_strategist)
https://en.wikipedia.org/wiki/Energy%E2%80%93maneuverability_theory
https://en.wikipedia.org/wiki/OODA_loop
https://www.usmcu.edu/Outreach/Marine-Corps-University-Press/Books-by-topic/MCUP-Titles-A-Z/A-New-Conception-of-War/
https://thetacticalprofessor.net/2018/04/27/updated-version-of-boyds-aerial-attack-study/
John Boyd - USAF The Fighter Pilot Who Changed the Art of Air Warfare
http://www.aviation-history.com/airmen/boyd.htm
Boyd then used E-M as a design tool. Until E-M came along, fighter
aircraft had been designed to fly fast in a straight line or fly high
to reach enemy bombers. The F-X, which became the F-15, was the first
Air Force fighter ever designed with maneuvering specifications. Boyd
was the father of the F-15, the F-16, and the F-18.
... snip ...
In 89/90, the Marine Corps Commandant leverages Boyd for makeover of
the corps (at a time when IBM was desperately in need of a
makeover). Then IBM has one of the largest losses in the history of US
companies and was being reorganized into the 13 "baby blues" in
preparation for breaking up the company (take-off on "baby bell"
breakup decade earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
John Boyd posts and web URLs
https://www.garlic.com/~lynn/subboyd.html
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
IBM CEO & former AMXEX president
https://www.garlic.com/~lynn/submisc.html#gerstner
Pension posts
https://www.garlic.com/~lynn/submisc.html#pension
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Terminals Date: 06 Jan, 2026 Blog: Facebookibm home 2741 Mar1970 until replaced by 300baud cdi miniterm summer 1977 & IBM tieline, replaced by 1200baud 3101, then ordered ibm/pc (in employee program although it took so long to arrive, that ibm/pc street price had dropped below employee price) ... special IBM 2400 baud hardware encrypting modem card.
at work got 3277 when they were available (replacing 2741). big uproar when 3278s appeared about the time published studies that quarter second response improved productivity. 3277/3272 had .086 hardware response. For 3278, a lot of terminal electronics were moved back into 3274 (reducing 3278 manufacturing cost) ... significantly driving up coax protocol chatter and 3278/3274 hardware response becomes .3-.5sec (depending amount of data). Letters to the 3278 product administrator got response that 3278 wasn't intended for interactive computing, but data entry (aka electronic keypunch). Later IBM/PC 3277 emulation card had 4-5 times the upload/download throughput of 3278 emulation card.
One of my hobbies after joining IBM was enhanced production operating systems for internal datacenters (one of the first and long time customers dating back to CP67 and 2741 was the online sales and marketing support HONE systems ... eventually clones cropping up all over the world) and at the time 3278 appeared, my systems were showing .11sec trivial interactive system response. 3277 hardware .086sec + system .11sec = .196sec response, easily meeting quarter sec ... while 3278s would require a time machine to send system responses back in time.
also 1980, IBM STL (since renamed SVL) was bursting at the seams and 300 people from IMS group were moving to offsite bldg with dataprocessing back to STL datacenter. They had tried "remote" 3270 support and found the human factors totally unacceptable. I got con'ed into doing channel-extender support so channel-attached 3270 controllers could be placed at the off-site bldg ... resulting in no perceptible human factors difference between off-site and inside STL. An unintended consequence was mainframe system throughput increased 10-15%. STL system configurations had large number of 3270 controllers spread all across channels shared with 3830/3330 disks ... and significant 3270 controller channel busy overhead was effectively (for same amount 3270 I/O) being masked by the channel extender (resulting in improved disk throughput). Then there was consideration to use channel extenders for all 3270 controllers (even those located inside STL).
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
channel-extender posts
https://www.garlic.com/~lynn/submisc.html#channel.extender
some posts mentioning response, 3272/3277, 3274/3278
https://www.garlic.com/~lynn/2021j.html#74 IBM 3278
https://www.garlic.com/~lynn/2021i.html#69 IBM MYTE
https://www.garlic.com/~lynn/2012p.html#1 3270 response & channel throughput
https://www.garlic.com/~lynn/2012.html#13 From Who originated the phrase "user-friendly"?
https://www.garlic.com/~lynn/2010b.html#31 Happy DEC-10 Day
https://www.garlic.com/~lynn/2009q.html#72 Now is time for banks to replace core system according to Accenture
https://www.garlic.com/~lynn/2009q.html#53 The 50th Anniversary of the Legendary IBM 1401
https://www.garlic.com/~lynn/2009e.html#19 Architectural Diversity
https://www.garlic.com/~lynn/2006s.html#42 Ranking of non-IBM mainframe builders?
https://www.garlic.com/~lynn/2005r.html#15 Intel strikes back with a parallel x86 design
https://www.garlic.com/~lynn/2005r.html#12 Intel strikes back with a parallel x86 design
https://www.garlic.com/~lynn/2001m.html#19 3270 protocol
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: 4341, cluster supercomputing, distributed computing Date: 07 Jan, 2026 Blog: FacebookFuture System 1st half of the 70s ... completely different from 370 and going to completely replace it (internal politics during FS was killing off 370 efforts, and lack of new 370s is credited with giving clone 370 makers their market foothold).
Future System project 1st half 70s, imploded, from: Computer Wars: The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
When FS finally implodes, there is mad rush to get stuff back into 370
product pipelines including kicking off quick&dirty 3033&3081
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
Endicott cons me into help with virgil/tully (138/148) ECPS microcode
assist ... archived post with copy of initial analysis
https://www.garlic.com/~lynn/94.html#21
Endicott also wanted to preinstall VM370 on every 138/148 shipped, but corporate vetoed that ... in part because head of POK was in the process of convincing corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA (Endicott eventually acquires the VM370 product mission but had to recreate a development group from scratch).
I also get talked into working on 16-CPU 370, and we con the 3033 processor engineers into working on it in their spare time (a lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (existing MVS documentation was that simple 2-CPU support only got 1.2-1.5 times the throughput of 1-CPU; POK doesn't ship a 16-CPU system until after the turn of the century). The head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, heads down and no distractions.
I transfer out of SJR on the west coast and got to wander IBM (and non-IBM) datacenters in silicon valley, including disk bldg14/engineering and bldg15/product test, across the street. They were running 7x24, prescheduled stand alone mainframe testing. They said they had tried MVS, but it had 15min MTBF (in that environment) requiring manual re-ipl. I offer to rewrite I/O supervisor, making it bullet-proof and never fail, allowing any amount of ondemand, concurrent testing ... greatly improving productivity.
Bldg15 gets first engineeering 3033 (outside POK engineering) for I/O testing ... which only takes percent or two of CPU, so we scrounge up a 3830 controller and string of 3330 disks for private online service. Then 1978, bldg15 get engineering 4341 (w/ECPS) ... and with some microcode tweaks was also able to do 3mbyte/sec, data streaming channel testing. Jan1979, branch office hears about it and cons me into doing benchmark for national lab looking at getting 70 for compute farm (sort of the leading edge of the coming cluster supercomputing tsunami).
trivia-1: In the morph of CP67->VM370, lots of stuff was simplified and/or dropped (includuing shared-memory, tightly-coupled, multiprocessor support). Then w/VM370R2-base, I start adding lots of stuff back in for my internal CSC/VM. Then for CSC/VM VM370R3-base, I add multiprocessor support back in, initially for online sales&marketing consolidated US HONE, so they can upgrade their 158&168s to 2-CPU (getting twice the throughput of single CPU systems). Note: when FACEBOOK 1st moves into silicon valley, it was new bldg built next door to former consolidated US HONE datacenter.
trivia-2: Communication group was fighting release of mainframe TCP/IP; when they lost, change strategy and said they had corporate ownership of everything crossing datacenter walls, it had to be released through them. What shipped got aggregate 44kbytes using nearly whole 3090 CPU. I then add RFC1044 support and in some testing at Cray Research between Cray and 4341 got sustained 4341 channel throughput using only modest 4341 CPU (something like 500 times improvement in bytes moved per instruction execute).
trivia-3: in the 1st half 80s, there were large corporations ordering hundreds of VM/4341 at a time for deploying out in departmental areas (sort of the leading edge of the coming departmental computing tsunami) ... inside IBM, departmental conference rooms became scarce as so many were converted to VM/4341 rooms. MVS started lusting after the market. The problem was (datacenter) 3380s were only new CKD and the only mid-range, non-datacenter, were FBA. Eventually 3370s were modified for CKD emulation as 3375. It didn't do them much good, departmental computing was looking at scores of systems per support person, while MVS still required scores of support people per system.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
RFC1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
DASD, CKD, FBA, multi-track search posts
https://www.garlic.com/~lynn/submain.html#dasd
vm/4341, cluster supercomuting, distributed computing posts
https://www.garlic.com/~lynn/2025d.html#53 Computing Clusters
https://www.garlic.com/~lynn/2025d.html#11 IBM 4341
https://www.garlic.com/~lynn/2025c.html#77 IBM 4341
https://www.garlic.com/~lynn/2025c.html#40 IBM & DEC DBMS
https://www.garlic.com/~lynn/2025c.html#15 Cluster Supercomputing
https://www.garlic.com/~lynn/2025b.html#44 IBM 70s & 80s
https://www.garlic.com/~lynn/2025b.html#8 The joy of FORTRAN
https://www.garlic.com/~lynn/2025.html#105 Giant Steps for IBM?
https://www.garlic.com/~lynn/2025.html#38 Multics vs Unix
https://www.garlic.com/~lynn/2024g.html#81 IBM 4300 and 3370FBA
https://www.garlic.com/~lynn/2024g.html#55 Compute Farm and Distributed Computing Tsunami
https://www.garlic.com/~lynn/2024f.html#70 The joy of FORTH (not)
https://www.garlic.com/~lynn/2024e.html#129 IBM 4300
https://www.garlic.com/~lynn/2024e.html#46 Netscape
https://www.garlic.com/~lynn/2024e.html#16 50 years ago, CP/M started the microcomputer revolution
https://www.garlic.com/~lynn/2024d.html#15 Mid-Range Market
https://www.garlic.com/~lynn/2024c.html#107 architectural goals, Byte Addressability And Beyond
https://www.garlic.com/~lynn/2024.html#64 IBM 4300s
https://www.garlic.com/~lynn/2023g.html#107 Cluster and Distributed Computing
https://www.garlic.com/~lynn/2023g.html#61 PDS Directory Multi-track Search
https://www.garlic.com/~lynn/2023g.html#15 Vintage IBM 4300
https://www.garlic.com/~lynn/2023e.html#80 microcomputers, minicomputers, mainframes, supercomputers
https://www.garlic.com/~lynn/2023d.html#102 Typing, Keyboards, Computers
https://www.garlic.com/~lynn/2023c.html#46 IBM DASD
https://www.garlic.com/~lynn/2023b.html#78 IBM 158-3 (& 4341)
https://www.garlic.com/~lynn/2023.html#74 IBM 4341
https://www.garlic.com/~lynn/2023.html#71 IBM 4341
https://www.garlic.com/~lynn/2022f.html#92 CDC6600, Cray, Thornton
https://www.garlic.com/~lynn/2022e.html#67 SHARE LSRAD Report
https://www.garlic.com/~lynn/2022d.html#66 VM/370 Turns 50 2Aug2022
https://www.garlic.com/~lynn/2022c.html#5 4361/3092
https://www.garlic.com/~lynn/2022b.html#16 Channel I/O
https://www.garlic.com/~lynn/2022.html#124 TCP/IP and Mid-range market
https://www.garlic.com/~lynn/2022.html#15 Mainframe I/O
https://www.garlic.com/~lynn/2021c.html#63 Distributed Computing
https://www.garlic.com/~lynn/2021c.html#47 MAINFRAME (4341) History
https://www.garlic.com/~lynn/2021b.html#55 In the 1970s, Email Was Special
https://www.garlic.com/~lynn/2021b.html#24 IBM Recruiting
https://www.garlic.com/~lynn/2019e.html#27 PC Market
https://www.garlic.com/~lynn/2019c.html#42 mainframe hacking "success stories"?
https://www.garlic.com/~lynn/2019c.html#35 Transition to cloud computing
https://www.garlic.com/~lynn/2018b.html#104 AW: mainframe distribution
https://www.garlic.com/~lynn/2018.html#24 1963 Timesharing: A Solution to Computer Bottlenecks
https://www.garlic.com/~lynn/2017i.html#62 64 bit addressing into the future
https://www.garlic.com/~lynn/2016h.html#48 Why Can't You Buy z Mainframe Services from Amazon Cloud Services?
https://www.garlic.com/~lynn/2016h.html#44 Resurrected! Paul Allen's tech team brings 50-year-old supercomputer back from the dead
https://www.garlic.com/~lynn/2016h.html#29 Erich Bloch, IBM pioneer who later led National Science Foundation, dies at 91
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: 4341, cluster supercomputing, distributed computing Date: 08 Jan, 2026 Blog: Facebookre:
Amdahl won the battle to make ACS, 360-compatible ... then ACS/360 was
killed (folklore executives felt it would advance the state of art too
fast and IBM would loose control of the market) and Amdahl leaves IBM.
https://people.computing.clemson.edu/~mark/acs_end.html
above mentions some ACS/360 features that show up more than 20yrs
later in the 90s with ES/9000
Then FS (with its killing off 370 efforts) ... one of the last nails in the FS coffin was IBM Houston Scientific Center analysis was if 370/195 applications were redone for FS machine made out of the fastest available hardware, they would have throughput of 370/145 (about 30 times slowdown).
Quick&dirty 303x started out with channel director as 158 engine with just the integrated channel director microcode and no 370 microcode. A 3031 was two 158 engines, one with just 370 microcode and the other just integrated channel microcode. 3032 was 168-3 reconfigured for channel director external channels (i.e. 158 engine and integrated channel microcode). 3033 started out 168 logic remapped to 20% faster chips.
3081 was some warmed over FS technology and started out multiprocessor only. First 3081D was two processor and aggregate MIPS less than Amdahl 1-CPU system. They double the CPU cache sizes, bringing 2-CPU 3081K aggregate MIPs up to about the same as Amdahl 1-CPU ... although even with same aggregate MIPS, MVS 3081 2-CPU systems only had .6-.75 times throughput of Amdahl 1-CPU (because of MVS large multiprocessor overhead).
ECPS trivia: Very early 80s, I got permission to give presentations at user group meetings on details of ECPS implementation ... and after meetings, Amdahl people would grill me for more information. They said that they were doing microcode (virtual machine) hypervisor (multiple domain) using MACROCODE (370 like instructions running in microcode mode, MACROCODE original done to respond to the plethpra of trivial 3033 microcode required for MVS to run). IBM was then finding IBM customers were slow migrating from MVS to MVS/XA .... but much better on Amdahl machines because they could run MVS and MVS/XA concurrently on the same machine (IBM doesn't respond with LPAR until nearly decade later on 3090).
POK had problem that after they killed VM370 (at least for high-end) they didn't have anything equivalent. They had done a limited VMTOOL virtual machine for MVS/XA testing (but never intended for production) ... it also required the SIE microcode instruction (for 370/XA) to move in/out of virtual machine mode ... but because of limited 3081 microcode space, it had to be paged in/out ... further limiting its usefulness for production. Eventually IBM did hack on VMTOOL as VM/MA & VM/SF (for limited concurrent testing of MVS & MVS/XA). Much of 370/XA was to compensate for problems and short comings with MVS (for instance, my redo of I/O supervisor had about 1/20th the MVS pathlength for channel redrive, aka after end interrupt, restart channel with queued request)
future system posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory, multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
jan1979 national lab (cdc6600) rain/rain4 fortran benchmark
https://www.garlic.com/~lynn/2000d.html#0
a few recent posts mentioning amdahl, macrocode, hypervisor, multiple
domain, ecps, lpar
https://www.garlic.com/~lynn/2025e.html#67 Mainframe to PC
https://www.garlic.com/~lynn/2025d.html#110 IBM System Meter
https://www.garlic.com/~lynn/2025d.html#61 Amdahl Leaves IBM
https://www.garlic.com/~lynn/2025b.html#118 IBM 168 And Other History
https://www.garlic.com/~lynn/2025b.html#46 POK High-End and Endicott Mid-range
https://www.garlic.com/~lynn/2025.html#19 Virtual Machine History
https://www.garlic.com/~lynn/2024f.html#30 IBM 370 Virtual memory
https://www.garlic.com/~lynn/2024d.html#113 ... some 3090 and a little 3081
https://www.garlic.com/~lynn/2024c.html#17 IBM Millicode
https://www.garlic.com/~lynn/2024b.html#68 IBM Hardware Stories
https://www.garlic.com/~lynn/2024.html#63 VM Microcode Assist
https://www.garlic.com/~lynn/2023g.html#78 MVT, MVS, MVS/XA & Posix support
https://www.garlic.com/~lynn/2023g.html#48 Vintage Mainframe
https://www.garlic.com/~lynn/2023f.html#104 MVS versus VM370, PROFS and HONE
https://www.garlic.com/~lynn/2023e.html#74 microcomputers, minicomputers, mainframes, supercomputers
https://www.garlic.com/~lynn/2023e.html#51 VM370/CMS Shared Segments
https://www.garlic.com/~lynn/2023d.html#10 IBM MVS RAS
https://www.garlic.com/~lynn/2023d.html#0 Some 3033 (and other) Trivia
https://www.garlic.com/~lynn/2023c.html#61 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2023.html#55 z/VM 50th - Part 6, long winded zm story (before z/vm)
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Virtual Machine and Virtual Memory Date: 10 Jan, 2026 Blog: FacebookSome of the MIT CTSS/7094 went to the 5th flr for MULTICS. Others went to the IBM Cambridge Science Center on the 4th flr. They did virtual machines (wanted a 360/50 to modify with hardware virtual memory, but all the extra 50s were going to FAA/ATC and so had to settle for a 360/40 to modify and did CP40/CMS. Then when 360/67 standard with virtual memory became available, CP40/CMS morphs into CP67/CMS (official IBM system for 360/67 was TSS/360 ... at the time TSS/360 was decommitted, there were 1200 people in the TSS/360 organization and 12 people in the CP67/CMS group).
Early last decade I was asked to track down decision to add virtual memory to all 370s. I found staff to executive making decision. Basically MVT storage management was so bad that region sizes were being specified four times larger than used ... and frequently a standard 1mbyte 370/165 only ran four regions concurrently (insufficient to keep system busy and justified). Running MVT in 16mbyte virtual address space (VS2/SVS) allowed number of regions to be increase by factor of four times (capped at 15 because 4bit storage protect keys) with little or no paging (similar to running MVT in a CP67 16mbyte virtual machine).
I would periodically drop by Ludlow doing initial VS2/SVS (on 360/67 pending engineering 370 with virtual memory). I little bit of code to build virtual memory tables and simple page fault, page replacement, page i/o). Big problem was (same as CP67 w/virtual machines), the channel programs being passed had virtual addresses (and channels require real addresses) and copies of the channel program had to be made, replacing virtual addresses with real. He borrows CP67 CCWTRANS for crafting into EXCP/SVC0.
Note in the 70s, I was pontificating that systems were getting faster than disks were getting faster. Early 80s, I wrote tome that since 360 announced, disk relative system throughput had decline by order of magnitude (disks got 3-5 times faster, systems got 40-50 faster). Disk division executive then assigned the division performance group to refute my statements. A couple weeks later, they came back and showed I had slightly understated the problem. They then respin the analysis for a SHARE presentation (16Aug1984, SHARE 63, B874) on how to configure disks for improved system throughput.
Mid-70s to get passed the 15 region cap as systems getting larger, the switch is to VS2/MVS, giving private 16mbyte virtual address space to each region. However, OS/360 heritage is heavily pointer passing APIs. As a result an 8mbyte image of MVS kernel is mapped into every private 16mbyte virtual address space (leaving 8mbyte). Also MVS subsystems were also moved into their own private 16mbyte virtual address space. Now for subsystems API to access & return information, a common segment area ("CSA") is mapped into every 16mbyte virtual address space (leaving 7mbytes for regions). However requirement for CSA space is somewhat proportional to number of subsystems and concurrent regions ... and CSA quickly explodes to multiple segments common system area (still "CSA") and by 3033 it was frequently running 5-6mbytes (leaving 2-3mbytes for each region, but threatening to becomes 8mbytes, leaving zero). This is major factor VS2/MVS desperate rush to get to 370/XA ("811" for Nov1978 architecture & specification document dates).
With 3081 and availability of 370/XA and MVS/XA, customers weren't moving to MVS/XA as planned. Worse is Amdahl customers were doing better job migrating. 3081x originally was only going to be multiprocessor only and 3081D 2-CPU had lower aggregate MIPS than single processor Amdahl. IBM doubles the 3081 processor cache sizes for 3081K 2-CPU with about same aggregate MIPS as 1-CPU Amdahl. Aggregating things was MVS documentation had high MVS 2-CPU multiprocessor overhead only gets 1.2-1.5 times throughput of a single CPU (making 2-CPU 3081K, even with same aggregate MIPS, only has .6-.75 throughput of Amdahl single CPU).
worse, is head of POK had previously convinced corporate to kill VM370
product, shutdown the development group, and transfer all the people
to POK for MVS/XA (Endicott eventually saves the VM370 product for the
mid-range). Amdahl had previously done Multiple Domain/HYPERVISOR
(virtual machine MACROCODE) able to run MVS & MVS/XA
concurrently on same machine. a couple recent posts
https://www.garlic.com/~lynn/2026.html#11 4341, cluster supercomputing, distributed computing
https://www.garlic.com/~lynn/2025c.html#49 IBM And Amdahl Mainframe
https://www.garlic.com/~lynn/2025b.html#118 IBM 168 And Other History
recent posts mentioning IBM Burlington 7mbyte MVS issue
https://www.garlic.com/~lynn/2025e.html#114 Comsat
https://www.garlic.com/~lynn/2025d.html#91 IBM VM370 And Pascal
https://www.garlic.com/~lynn/2025d.html#68 VM/CMS: Concepts and Facilities
https://www.garlic.com/~lynn/2025d.html#51 Computing Clusters
https://www.garlic.com/~lynn/2025.html#130 Online Social Media
https://www.garlic.com/~lynn/2025.html#104 Mainframe dumps and debugging
Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM CSC, SJR, System/R, QBE Date: 11 Jan, 2026 Blog: FacebookWhen I first graduated and joined Cambridge Scientific Center, one of my hobbies was enhanced production operating systems for internal dataceters and one of the first (and long time) was the online branch office HONE systems. Branch office training for SEs had been part of large SE group on-site at customer location. 23Jun1969 unbundling announcement started to charge for (application) software (managed to make case that kernel software should still be free), SE services, maint., etc. However they couldn't figure out how not to charge for trainee SEs on-site at customer. As a result HONE spawned, multiple (virtual machine) CP67/CMS datacenters around the US providing online access to trainee SEs at branches, running guest operating systems in virtual machines. Scientific Center had also ported APL\360 to CMS for CMS\APL (redoing 16kbyte swapped workspaces for large demand page virtual memory operation and added APIs for system services like fille I/O, enabling real world applications) and HONE started providing online APL-based sales&marketing support applications (which came to dominate all HONE use, with guest operating system use withered away) ... came to be the largest use of APL in the world as HONE datacenters spawned all over the world (I was requested to do the 1st couple, Paris and Tokyo).
When I transferred from Cambridge Scientific Center to San Jose
Research (west coast ... about the same time all the US HONE
datacenters were consolidated up in Palo Alto), I worked with Jim Gray
and Vera Watson on System/R; original SQL/relational. It was initially
developed on VM370 370/145. Then with the corporation preoccupied with
the next great DBMS, EAGLE ... was able to do tech transfer (under the
radar) to Endicott for SQL/DS. Later after "EAGLE" implodes, there was
a request for how fast could System/R be ported to MVS (eventually
released as DB2, originally for decision/support only)
Date: 03/10/80 18:36:35
From: Jim Gray
Peter DeJong of Yorktown Computer Science
Father of QBE
Arch-enemy of System/R
Will be speaking on Tuesday (today) at 2:30-3:30 in 2C-244
On: System For Business Automation (SBA) which is a conceptual model
for an electronic office system. Peter has lots of good ideas on how
to send forms around to people, how to use abstract data types to
conquer the office automation problem. He also has some ideas on how
to implement triggers which are key to SBA.
... snip ... top of post, old email index
One of the science center members did an APL-based analytical system model ... which was made available on HONE as the Performance Predictor. SEs could enter customer's system configuration and workload activity data and ask questions about what happens when changes are made to configuration or workload.
Turn of century was brought into a financial outsourcing mainframe datacenter (that handled all processing for half of all credit card accounts in the US) .... had greater than 40 max configured mainframes (@$30M, none older than 18months, constant rolling upgrades) all running the same 450k statement cobol app (number of mainframes needed to finish settlement in the overnight batch window). I did some performance analysis optimization using some science center technology from the 70s, found 14% overall better throughput performance. They also had another consultant that had acquired a descendant of the Performance Predictor (in the 90s when IBM was barely being saved from breakup and was unloading all sort of stuff), ran it through an APL->C translator and was using it for performance consulting and found another 7% throughput improvement (21% aggregate improvement, >$200M savings)
previous archived post with same QBE email
https://www.garlic.com/~lynn/2002e.html#email800310
System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
Cambridge Science Cener posts
https://www.garlic.com/~lynn/subtopic.html#545tech
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
posts mentioning unbundling
https://www.garlic.com/~lynn/submain.html#unbundle
some recent posts mentioning HONE performance predictor
https://www.garlic.com/~lynn/2025e.html#64 IBM Module Prefixes
https://www.garlic.com/~lynn/2025e.html#27 Opel
https://www.garlic.com/~lynn/2025c.html#19 APL and HONE
https://www.garlic.com/~lynn/2025b.html#68 IBM 23Jun1969 Unbundling and HONE
https://www.garlic.com/~lynn/2024f.html#52 IBM Unbundling, Software Source and Priced
https://www.garlic.com/~lynn/2024d.html#9 Benchmarking and Testing
https://www.garlic.com/~lynn/2024c.html#6 Testing
https://www.garlic.com/~lynn/2024b.html#72 Vintage Internet and Vintage APL
https://www.garlic.com/~lynn/2024b.html#31 HONE, Performance Predictor, and Configurators
https://www.garlic.com/~lynn/2024b.html#18 IBM 5100
https://www.garlic.com/~lynn/2024.html#112 IBM User Group SHARE
https://www.garlic.com/~lynn/2024.html#78 Mainframe Performance Optimization
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Webservers and Browsers Date: 12 Jan, 2026 Blog: Facebook... random trivia, 1st webserver in the US was on SLAC's VM system
other trivia;
1988, HA/6000 was approved, initially for NYTimes to migrate their
newspaper system off DEC VAXCluster to RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid Jan92, convince IBM FSD to bid
HA/CMP for gov. supercomputers. Late Jan92, cluster scale-up is
transferred for announce as IBM Supercomputer (for
technical/scientific *ONLY*) and we are told we can't do clusters with
anything that involve more than four systems (we leave IBM a few
months later). Partially blamed FSD going up to the IBM Kingston
supercomputer group to tell them they were adopting HA/CMP for
gov. bids (of course somebody was going to have to do it
eventually). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Not long after leaving IBM, was brought in as consultant to small client/server startup, two former Oracle people (that had worked on HA/CMP and were in the Ellison/Hester meeting) are there responsible for something call "commerce server" and they want to do payment transactions. The startup had also invented this stuff they called "SSL" they want to use, it is now frequently called "e-commerce". I had responsibility for everything between web servers and payment networks, including the payment gateways. One of the problems with HTTP&HTTPS were transactions built on top of TCP ... implementation that sort of assumed long lived sessions. As webserver workload ramped up, web servers were starting to spend 95+% of CPU running FINWAIT list. NETSCAPE was increasing number of servers and trying to spread the workload. Eventually NETSCAPE installs a large multiprocessor server from SEQUENT (that had also redone DYNIX FINWAIT processing to eliminate that non-linear increase in CPU overhead).
I then did a talk on "Why Internet Isn't Business Critical" dataprocessing based on documentation, processes and software I had to do for e-commerce, which (IETF RFC editor) Postel sponsored at ISI/USC.
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
e-commerce payment network gateway posts
https://www.garlic.com/~lynn/subnetwork.html#gateway
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 360s, Unbundling, 370s, Future System Date: 15 Jan, 2026 Blog: FacebookBefore I graduated, was hired into small group in Boeing CFO office to help with the formation of Boeing Computer Service (consolidate all dataprocessing into independent business unit). I thought Renton datacenter possibly largest in the world, 360/65s arriving faster than they could be installed. Lots of politics between Renton director and CFO, who only had 360/30 up at Boeing field for payroll (although they enlarge the room to install a 360/67 for me to play with).
When I graduate, instead of staying with Boeing CFO, I join the IBM
Cambridge Scientific Center ... and shortly later was asked to help
with adding multithreading to 370/195. Amdahl won battle to make ACS,
360 compatible ... but then ACS/360 was killed (folklore, executives
were concerned that it would advance state-of-art too fast and IBM
would loose control of the market) and Amdahl leaves IBM to start his
own clone mainframe company. Some discussion of multithreading here:
https://people.computing.clemson.edu/~mark/acs_end.html
370/195 was pipelined and out-of-order execution ... but conditional branches drained the pipeline ... and most code only ran at half throughput. Adding multithreading, implementing two I-streams (simulating two CPUs) ... each running at half throughput ... possibly keep the 195 fully busy. Then with the decision to add virtual memory to all 370s, it was decided that it would be too hard adding virtual memory to 195 ... and all new 195 work was canceled. It turns out it wouldn't have actually done that much good, anyway. MVT up through MVS documentation had 2-CPU operation only getting 1.2-1.5 times the throughput of single CPU systems (or in 195 case, .6-.75 of fully busy, because of heavy multiprocessor overhead)
After IBM started adding virtual memory to all 370s, the "Future
System" started, completely different and to replace all 370s
... internal politics was killing off 370 activity and lack of new 370
during FS is credited with giving clone 370 makers (including Amdahl)
their market foothold. Then with FS implosion there is mad rush to get
stuff back into the 370 product pipelines, including kicking off
quick&dirty 3033 & 3081. One of the last nails in the FS coffin was
IBM Houston Scientific Center analysis that if 370/195 applications
were redone for FS machine made out of the faster technology
available, they would have throughput of 370/145 (about 30 times
slowdown).
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
from: Computer Wars: The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and
*MAKE NO WAVES* under Opel and Akers. It's claimed that
thereafter, IBM lived in the shadow of defeat ... But because of the
heavy investment of face by the top management, F/S took years to
kill, although its wrong headedness was obvious from the very
outset. "For the first time, during F/S, outspoken criticism became
politically dangerous," recalls a former top executive
... snip ...
I also get talked into working on 16-CPU 370, and we con the 3033 processor engineers into working on it in their spare time (a lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (existing MVS documentation was that simple 2-CPU support only got 1.2-1.5 times the throughput of 1-CPU; POK doesn't ship a 16-CPU system until after the turn of the century). The head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, heads down and no distractions.
3081 was going to be multiprocessor only and initial 3081D aggregate MIPS was less than Amdhal single processor. IBM then doubles processor cache size for 3081K and brings aggregate MIPs up to about the same as Amdahl single processor (however MVS 3081K multiprocessor only had about .6-.75 throughput of Amdahl single processor).
trivia: After I graduated and joined science center, one of my hobbies was enhanced production operating systems for internal datacenters and one of the 1st (and long time) customers was HONE. Branch office training for SEs had been part of large SE group on-site at customer location. 23Jun1969 unbundling announcement started to charge for (application) software (managed to make case that kernel software should still be free), SE services, maint., etc. However they couldn't figure out how not to charge for trainee SEs on-site at customer. As a result HONE spawned, multiple (virtual machine) CP67/CMS datacenters around the US providing online access to trainee SEs at branches, running guest operating systems in virtual machines. Scientific Center had also ported APL\360 to CMS for CMS\APL (redoing 16kbyte swapped workspaces for large demand page virtual memory operation and added APIs for system services like fille I/O, enabling real world applications) and HONE started providing online APL-based sales&marketing support applications (which came to dominate all HONE use, with guest operating system use withered away) ... came to be the largest use of APL in the world as HONE datacenters spawned all over the world (I was requested to do the 1st couple, Paris and Tokyo ... yen was about 330/dollar).
With adding virtual memory to all 370s, there was also effort to morph CP67->VM370 where they simplified or dropped a lot of stuff (including multiprocessor support). 1974, I then start adding a bunch of stuff back into VM370R2-base for my initial internal CSC/VM. Then for VM370R3-base CSC/VM, I add multiprocessor support back in, initially for HONE so they could add a 2nd CPU to all their 158s and 168s (CSC/VM 2-CPU was getting twice throughput of single CPU systems). This was something of a problem for head of POK, with the MVS overhead and getting such poor multiprocessor operation ... and he was also in the process of convincing corporate to kill the VM370 product, shutdown the development group, and transfer the people to POK for MVS/XA (Endicott eventual acquired the VM370 product mission for the mid-range, but had to recreate a development group from scratch).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
23Jun1969 unbundling posts
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Mainframe and non-mainframe technology Date: 16 Jan, 2026 Blog: Facebook1988, the IBM branch office asked if I could help LLNL (national lab) with standardization of some serial they were working with, which quickly becomes fibre-channel standard ("FCS", including some stuff I had done in 1980, initially 1gbit transfer, full-duplex, aggregate 200mbyte/sec). Then IBM mainframe release some serial (when it was already obsolete) as ESCON, initially 10mbyte/sec, upgrading to 17mbyte/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight protocol that drastically cuts native throughput, eventually ships as FICON. Around 2010 was a max configured z196 public "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON).
Max configured Z196 MIPS had 50BIPS industry standard benchmark
(number of program iterations compared to industry benchmark MIPS/BIPS
referenced platform) and list at $30M ($600,000/BIP). By comparison
IBM had base list price of $1815 for E5-2600 server blade benchmark at
500BIPS (same industry standard benchmark number of program
iterations). Cloud operations assembling their own E5-2600 server
blades would be more like (IBM base list $1815/3) $605
($1.21/BIP). Note IBM docs has SAPs (system assist processors that do
actual I/O) CPU be kept to 70% ... or 1.5M IOPS) ... also no CKD DASD
have been made for decades (just simulated on industry fixed-block
devices).
max configured z196: 50BIPS, 80cores, 625MIPS/core
E5-2600 server blade: 500BIPS, 16cores, 31BIPS/core
Large cloud operation would have score or more megadatacenters, each
with half million or more E5-2500 server blades and enormous
automation (70-80 staff/megadatacenter). Not long after "Peak I/O",
industry press had articles that server component vendors were
shipping half their product directly to large cloud operation ... and
shortly later, IBM sells off its server blade business.
trivia-1: My (future) wife was in Gburg JES group and one of the
catchers for ASP/JES3 and was con'ed into going to POK, responsible
for loosely-coupled architecture (Peer-coupled Shared Data). She
didn't remain long, 1) lots of battles with the communication group
trying to force her into using SNA/VTAM for loosely-coupled operation,
2) little uptake (until much later with SYSPLEX and Parallel SYSPLEX),
except IMS hot-standby. She has story asking Vern Watts who he asks
permission for to do hot-standby; he replies, nobody, will just tell
them when its all done.
https://www.vcwatts.org/ibm_story.html
Note after Future System imploded, I got asked to help with 16-CPU 370 and we con the 3033 processor engineers into helping in their spare time (lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operatin system ("MVS") had (effective) 16-CPU support (at the time MVS docs had 2-CPU multiprocessor systems only getting 1.2-1.5 throughput of single CPU, POK doesn't ship 16-CPU system until after turn of century) and head of POK invites some of us to never visit POK again and directs 3033 processor engineers, heads down and no distractions.
One of my hobbies after joining IBM was enhanced production operating systemms for internal datacenters (and the internal online sales&marketing HONE systems was one of the 1st and long-time customer). In the morph of CP67->VM370, lots of stuff was simplified or dropped (like multiprocessor support). In 1974, I start adding bunch of stuff back into a VM370R2-base for my CSC/VM. Then I add multiprocessor support back into a VM370R3-base CSC/VM, originally for HONE so they could upgrade with 2nd CPU for their 158 & 168 systems (getting twice throughput of single CPU systems).
Also 1988, HA/6000 was approved initially for NYTimes to migrate their
newspaper system off DEC VAXCluster to RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
IBM S/88 (relogo'ed Stratus) Product Administrator started taking us around to their customers and also had me write a section for the corporate continuous availability document (it gets pulled when both AS400/Rochester and mainframe/POK complain they couldn't meet requirements). Had coined disaster survivability and geographic survivability (as counter to disaster/recovery) when out marketing HA/CMP. One of the visits to 1-800 bellcore development showed that S/88 would use a century of downtime in one software upgrade, while HA/CMP had a couple extra "nines" (compared to S/88).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid Jan92, convince IBM FSD to bid
HA/CMP for gov. supercomputers. Late Jan92, cluster scale-up is
transferred for announce as IBM Supercomputer (for
technical/scientific *ONLY*) and we are told we can't do clusters with
anything that involve more than four systems (we leave IBM a few
months later). Partially blamed FSD going up to the IBM Kingston
supercomputer group to tell them they were adopting HA/CMP for
gov. bids (of course somebody was going to have to do it
eventually). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would eat the mainframe in the commercial
market. 1993 benchmarks (number of program iterations compared to the
MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, 51MIPS/CPU
RS6000/990 : (1-CPU) 126MIPS, 16-systems: 2BIPS, 128-systems: 16BIPS
One of the executives we reported to, goes over to head up
Somerset/AIM (apple, ibm, motorola) to do single chip Power/PC (with
Motorola 88K bus enabling multiprocessor operation) Then, mid-90s, i86
chip makers do hardware layer that translate i86 instructions into
RISC micro-ops for actual execution (largely negating throughput
difference between RISC and i86); 1999 industry benchmark:
IBM PowerPC 440: 1,000MIPS
Pentium3: 2,054MIPS (twice PowerPC 440)
... trivia-2: One quote is that (cache miss) memory latency, when
measured in count of processor cycles, is about the same as disk
latency at 360-announce, when measured in count of 60s processor
cycles (memory is the new disk). Early RISC developed memory latency
compensation; out-of-order execution, branch prediction, speculative
execution, multithreading, etc (analogy to 60s multiprogramming)
... trivia-3; part of head of POK's issues was also after "Future
System" implosion:
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
he was in the process of convincing corporate to kill the VM370 product, shutdown the development group, and transfer all the people to POK for MVS/XA (Endicott eventually manages to acquire the VM/370 product mission for the midrange ... but had to recreate a development group from scratch). Then POK executives were going around internal datacenters trying to strong arm to move off VM/370 to MVS. POK tried it on HONE ... and they got a whole lot of push back and eventually had to come back and explain to HONE, that HONE had totally misunderstand what was being said.
FCS and/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
Megadatacenter posts
https://www.garlic.com/~lynn/submisc.html#megadatacenter
Mainframe loosely-coupled, shared data architecture posts
https://www.garlic.com/~lynn/submain.html#shareddata
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Wild Ducks Date: 16 Jan, 2026 Blog: FacebookNote that the IBM century/100yrs celebration, one of the 100 videos was on wild ducks, ... but it was customer wild ducks... all references to employee wild ducks has been expunged. 1972, Learson tried (and failed) to block bureaucrats, careerists, and MBAs from destroying Watson culture/legacy:
How to Stuff a Wild Duck
https://www.si.edu/object/chndm_1981-29-438
Future System project 1st half 70s, imploded from: Computer Wars:
The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
--- FS completely different from 370 and going to completely replace
it (during FS, internal politics was killing off 370 efforts, limited
new 370 is credited with giving 370 system clone makers their market
foothold). One of the final nails in the FS coffin was analysis by the
IBM Houston Science Center that if 370/195 apps were redone for FS
machine made out of the fastest available hardware technology, they
would have throughput of 370/145 (about 30 times slowdown)
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
trivia: I continued to work on 360&370 all during FS, periodically ridiculing what they were doing (drawing analogy with long playing cult film down at central sq; which wasn't exactly career enhancing activity)
Late 70s & early 80s I was blamed for online computer conferencing on
the internal network. It really took off the spring of 1981 when I
distributed a trip report to visit Jim Gray at Tandem (had left SJR
fall1980). Only about 300 directly participated but claims that 25,000
were reading. From IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
--- six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore is 5of6 corporate executive
committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the company
is rapidly heading for disaster. Furthermore, people fear that this
movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their management
and with the way things are going in IBM. To an increasing extent,
people are reacting to this by leaving IBM. Most of the contributors
to the present discussion would prefer to stay with IBM and see the
problems rectified. However, there is increasing skepticism that
correction is possible or likely, given the apparent lack of
commitment by management to take action
• There is a widespread perception that IBM management has failed to
understand how to manage technical people and high-technology
development in an extremely competitive
--- about the same time in the early 80s, I was introduced to John
Boyd and would sponsor his briefings at IBM
https://en.wikipedia.org/wiki/John_Boyd_(military_strategist)
https://en.wikipedia.org/wiki/Energy%E2%80%93maneuverability_theory
https://en.wikipedia.org/wiki/OODA_loop
https://www.usmcu.edu/Outreach/Marine-Corps-University-Press/Books-by-topic/MCUP-Titles-A-Z/A-New-Conception-of-War/
https://thetacticalprofessor.net/2018/04/27/updated-version-of-boyds-aerial-attack-study/
John Boyd - USAF The Fighter Pilot Who Changed the Art of Air Warfare
http://www.aviation-history.com/airmen/boyd.htm
Boyd then used E-M as a design tool. Until E-M came along, fighter
aircraft had been designed to fly fast in a straight line or fly high
to reach enemy bombers. The F-X, which became the F-15, was the first
Air Force fighter ever designed with maneuvering specifications. Boyd
was the father of the F-15, the F-16, and the F-18.
... snip ...
--- Boyd version of wild ducks:
"There are two career paths in front of you, and you have to choose
which path you will follow. One path leads to promotions, titles, and
positions of distinction.... The other path leads to doing things that
are truly significant for the Air Force, but the rewards will quite
often be a kick in the stomach because you may have to cross swords
with the party line on occasion. You can't go down both paths, you
have to choose. Do you want to be a man of distinction or do you want
to do things that really influence the shape of the Air Force? To be
or to do, that is the question."
--- in 89/90, the Marine Corps Commandant leverages Boyd for makeover
of the corps (at a time when IBM was desperately in need of a
makeover). Then IBM has one of the largest losses in the history of US
companies and was being reorganized into the 13 "baby blues" in
preparation for breaking up the company (take-off on "baby bell"
breakup decade earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
This century, we continued to have Boyd conferences at Qauntico MCU
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
John Boyd posts and web URLs
https://www.garlic.com/~lynn/subboyd.html
some recent wild duck posts
https://www.garlic.com/~lynn/2025d.html#49 Destruction of Middle Class
https://www.garlic.com/~lynn/2025d.html#48 IBM Vietnam
https://www.garlic.com/~lynn/2025d.html#31 Public Facebook Mainframe Group
https://www.garlic.com/~lynn/2025d.html#25 IBM Management
https://www.garlic.com/~lynn/2025d.html#9 IBM ES/9000
https://www.garlic.com/~lynn/2025c.html#83 IBM HONE
https://www.garlic.com/~lynn/2025c.html#64 IBM Vintage Mainframe
https://www.garlic.com/~lynn/2025c.html#60 IBM Innovation
https://www.garlic.com/~lynn/2025c.html#55 Univ, 360/67, OS/360, Boeing, Boyd
https://www.garlic.com/~lynn/2025c.html#51 IBM Basic Beliefs
https://www.garlic.com/~lynn/2025c.html#48 IBM Technology
https://www.garlic.com/~lynn/2025b.html#106 IBM 23Jun1969 Unbundling and HONE
https://www.garlic.com/~lynn/2025b.html#102 IBM AdStar
https://www.garlic.com/~lynn/2025b.html#93 IBM AdStar
https://www.garlic.com/~lynn/2025b.html#75 Armonk, IBM Headquarters
https://www.garlic.com/~lynn/2025b.html#57 IBM Downturn, Downfall, Breakup
https://www.garlic.com/~lynn/2025b.html#56 POK High-End and Endicott Mid-range
https://www.garlic.com/~lynn/2025b.html#45 Business Planning
https://www.garlic.com/~lynn/2025b.html#42 IBM 70s & 80s
https://www.garlic.com/~lynn/2025b.html#30 Some Career Highlights
https://www.garlic.com/~lynn/2025b.html#1 Large Datacenters
https://www.garlic.com/~lynn/2025.html#123 PowerPoint snakes
https://www.garlic.com/~lynn/2025.html#122 Clone 370 System Makers
https://www.garlic.com/~lynn/2025.html#115 2301 Fixed-Head Drum
https://www.garlic.com/~lynn/2025.html#105 Giant Steps for IBM?
https://www.garlic.com/~lynn/2025.html#98 IBM Tom Watson Jr Talks to Employees on 1960's decade of success and the 1970s
https://www.garlic.com/~lynn/2025.html#93 Public Facebook Mainframe Group
https://www.garlic.com/~lynn/2025.html#84 IBM Special Company 1989
https://www.garlic.com/~lynn/2025.html#71 VM370/CMS, VMFPLC
https://www.garlic.com/~lynn/2025.html#55 IBM Management Briefings and Dictionary of Computing
https://www.garlic.com/~lynn/2025.html#34 The Greatest Capitalist Who Ever Lived: Tom Watson Jr. and the Epic Story of How IBM Created the Digital Age
https://www.garlic.com/~lynn/2025.html#14 Dataprocessing Innovation
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM FAA/ATC Date: 21 Jan, 2026 Blog: Facebook... didn't deal with Joe in IBM, but after leaving IBM, we did a project with Fox & Template
1988, HA/6000 was approved initially for NYTimes to migrate their
newspaper system off DEC VAXCluster to RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
IBM S/88 (relogo'ed Stratus) Product Administrator started taking us around to their customers and also had me write a section for the corporate continuous availability document (it gets pulled when both AS400/Rochester and mainframe/POK complain they couldn't meet requirements). Had coined disaster survivability and geographic survivability (as counter to disaster/recovery) when out marketing HA/CMP. One of the visits to 1-800 bellcore development showed that S/88 would use a century of downtime in one software upgrade, while HA/CMP had a couple extra "nines" (compared to S/88).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive Hester tells Ellison that we would have 16-system clusters by mid92 and 128-system clusters by ye92.
We had been spending some amount of time with TA to FSD President, who was working 1st shift as TA and 2nd shift writing ADA code for the latest FAA program that also involved RS/6000s. Early specs claimed (hardware) redundancy&recovery was so complete that didn't need software contingency (then part way through they realized there could be business process failures and design had to be revamped). Mid Jan92, he helps convince IBM FSD to bid HA/CMP for gov. supercomputers.
Late Jan92, cluster scale-up is transferred for announce as IBM
Supercomputer (for technical/scientific *ONLY*) and we are told we
can't do clusters with anything that involve more than four systems
(we leave IBM a few months later). A couple weeks later, 17feb1992,
Computerworld news ... IBM establishes laboratory to develop parallel
systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Online Apps, Network, Email Date: 21 Jan, 2026 Blog: FacebookMIT 7094/CTSS had online email. Then some of the people go to the 5th for MULTICS and others go to the IBM Cambridge Scientific Center on 4th flr and do virtual machines (initially want 360/50 to modify with virtual memory, but all the extras were going to FAA/ATC and have to settle for a 360/40 and do virtual machine CP40/CMS ... and some number of CTSS apps are replicated for CMS. CP40/CMS morphs into CP67/CMS when 360/67 standard becomes available. Co-worker was responsible for CP67-based wide-area network ... mentioned by one of the CSC members inventing GML (later morphs into SGML & HTML) in 1969:
Science Centers wide-area network then morphs into the internal corporate network (larger than arpanet/internet from just about the beginning until sometime mid/late 80s ... about the time it was forced to convert to SNA/VTAM) ... technology also used for the corporate sponsored univ BITNET.
Edson
https://en.wikipedia.org/wiki/Edson_Hendricks
In June 1975, MIT Professor Jerry Saltzer accompanied Hendricks to
DARPA, where Hendricks described his innovations to the principal
scientist, Dr. Vinton Cerf. Later that year in September 15-19 of 75,
Cerf and Hendricks were the only two delegates from the United States,
to attend a workshop on Data Communications at the International
Institute for Applied Systems Analysis, 2361 Laxenburg Austria where
again, Hendricks spoke publicly about his innovative design which
paved the way to the Internet as we know it today.
... snip ...
newspaper article about some of Edson's Internet & TCP/IP IBM battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed, Internet &
TCP/IP) references from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
Along the way, PROFS group is collecting CMS apps for wrapping 3270 menu screens around and collects a very early version of VMSG for their email client. When the VMSG author tries to offer them a much enhanced VMSG, they try to get him separated from the company. The whole thing quiets down when the VMSG author demonstrates his initials in an non-displayed PROFS field. After that he only shares his source with me and one other person.
IBM Cambridge Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
Internal Network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
BITNET (&/or EARN) posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
some recent archived posts mentioning VMSG & PROFS email client
https://www.garlic.com/~lynn/2026.html#5 PROFS and other CMS applications
https://www.garlic.com/~lynn/2025e.html#103 IBM CSC, HONE
https://www.garlic.com/~lynn/2025d.html#109 Internal Network, Profs and VMSG
https://www.garlic.com/~lynn/2025d.html#43 IBM OS/2 & M'soft
https://www.garlic.com/~lynn/2025d.html#32 IBM Internal Apps, Retain, HONE, CCDN, ITPS, Network
https://www.garlic.com/~lynn/2025c.html#113 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#6 Interactive Response
https://www.garlic.com/~lynn/2025b.html#60 IBM Retain and other online
https://www.garlic.com/~lynn/2025.html#90 Online Social Media
https://www.garlic.com/~lynn/2024f.html#91 IBM Email and PROFS
https://www.garlic.com/~lynn/2024f.html#44 PROFS & VMSG
https://www.garlic.com/~lynn/2024e.html#99 PROFS, SCRIPT, GML, Internal Network
https://www.garlic.com/~lynn/2024e.html#48 PROFS
https://www.garlic.com/~lynn/2024e.html#27 VMNETMAP
https://www.garlic.com/~lynn/2024b.html#109 IBM->SMTP/822 conversion
https://www.garlic.com/~lynn/2024b.html#69 3270s For Management
https://www.garlic.com/~lynn/2023g.html#49 REXX (DUMRX, 3092, VMSG, Parasite/Story)
https://www.garlic.com/~lynn/2023f.html#71 Vintage Mainframe PROFS
https://www.garlic.com/~lynn/2023f.html#46 Vintage IBM Mainframes & Minicomputers
https://www.garlic.com/~lynn/2023c.html#78 IBM TLA
https://www.garlic.com/~lynn/2023c.html#42 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2023c.html#32 30 years ago, one decision altered the course of our connected world
https://www.garlic.com/~lynn/2023c.html#5 IBM Downfall
https://www.garlic.com/~lynn/2023.html#97 Online Computer Conferencing
https://www.garlic.com/~lynn/2023.html#62 IBM (FE) Retain
https://www.garlic.com/~lynn/2023.html#18 PROFS trivia
https://www.garlic.com/~lynn/2022b.html#29 IBM Cloud to offer Z-series mainframes for first time - albeit for test and dev
https://www.garlic.com/~lynn/2022b.html#2 Dataprocessing Career
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Credit Card Fraud Surcharge Date: 24 Jan, 2026 Blog: FacebookCC had fraud surcharge supposedly proportional to the associated fraud (w/internet being one of the highest). Turn of the century there was three "safe" transactions developed (one was mine) proposed to the major online merchants accounting for something like 90% of transactions ... with high acceptance assuming that they would eliminate the fraud surcharge. However, many of financial institutions, fraud surcharge represented 40%-60% of their bottom line ... and they proposed instead of eliminating the fraud surcharge ... they would add a "safe" surcharge on top of the fraud surcharge and it fell apart ... major cognitive dissonance (bank logic was that the "safe" surcharge would be less than the merchant cost of the actual fraud being eliminated).
I presented at '98 NIST security
https://csrc.nist.gov/pubs/conference/1998/10/08/proceedings-of-the-21st-nissc-1998/final
... joking that I was taking a $500 milspec chip, cost reducing by
nearly three orders of magnitude while increasing
integrity&security. Then was also asked to present in the
assurance session at IDF trusted computing track ... gone 404, but
lives on it wayback machine.
https://web.archive.org/web/20011109072807/http://www.intel94.com/idf/spr2001/sessiondescription.asp?id=stp%2bs13
wayback of CC industry "Yes Card" chip presentation ... which could
result in higher fraud than magstripe (last paragraph). I didn't make
it to Cartes 2002, so the people that did the study/presentation came
by my office to drop off copy,
https://web.archive.org/web/20030417083810/http://www.smartcard.co.uk/resources/articles/cartes2002.html
wayback of UK Safeway/IBM pilot of the "Yes Card"
https://web.archive.org/web/20061106193736/http://www-03.ibm.com/industries/financialservices/doc/content/solution/1026217103.html
Yes Card posts
https://www.garlic.com/~lynn/subintegrity.html#yescard
assurance posts
https://www.garlic.com/~lynn/subintegrity.html#assurance
fraud posts
https://www.garlic.com/~lynn/subintegrity.html#fraud
X9.59, Identity, Authentication, and Privacy posts
https://www.garlic.com/~lynn/subpubkey.html#privacy
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Downfall Date: 25 Jan, 2026 Blog: Facebook1972, Learson tried (and failed) to block bureaucrats, careerists, and MBAs from destroying Watson culture/legacy:
--- pg160-163, 30yrs of management briefings 1958-1988
https://bitsavers.org/pdf/ibm/generalInfo/IBM_Thirty_Years_of_Mangement_Briefings_1958-1988.pdf
How to Stuff a Wild Duck
https://www.si.edu/object/chndm_1981-29-438
Future System project 1st half 70s, imploded; from: Computer Wars:
The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
--- FS completely different from 370 and going to completely replace it
(during FS, internal politics was killing off 370 efforts, limited new
370 is credited with giving 370 system clone makers their market
foothold). One of the final nails in the FS coffin was analysis by the
IBM Houston Science Center that if 370/195 apps were redone for FS
machine made out of the fastest available hardware technology, they
would have throughput of 370/145 (about 30 times slowdown)
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
trivia: I continued to work on 360&370 all during FS, periodically ridiculing what they were doing (drawing analogy with long playing cult film down at central sq; which wasn't exactly career enhancing activity)
--- Late 70s & early 80s I was blamed for online computer conferencing on
the internal network. It really took off the spring of 1981 when I
distributed a trip report to visit Jim Gray at Tandem (he had left SJR
fall1980). Only about 300 directly participated but claims that 25,000
were reading. From IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
--- six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore was 5of6 corporate
executive committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the company is
rapidly heading for disaster. Furthermore, people fear that this
movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their management
and with the way things are going in IBM. To an increasing extent,
people are reacting to this by leaving IBM. Most of the contributors
to the present discussion would prefer to stay with IBM and see the
problems rectified. However, there is increasing skepticism that
correction is possible or likely, given the apparent lack of
commitment by management to take action
• There is a widespread perception that IBM management has failed to
understand how to manage technical people and high-technology
development in an extremely competitive environment
... snip ...
--- about the same time in the early 80s, I was introduced to John Boyd
and would sponsor his briefings at IBM
https://en.wikipedia.org/wiki/John_Boyd_(military_strategist)
https://en.wikipedia.org/wiki/Energy%E2%80%93maneuverability_theory
https://en.wikipedia.org/wiki/OODA_loop
https://www.usmcu.edu/Outreach/Marine-Corps-University-Press/Books-by-topic/MCUP-Titles-A-Z/A-New-Conception-of-War/
https://thetacticalprofessor.net/2018/04/27/updated-version-of-boyds-aerial-attack-study/
John Boyd - USAF The Fighter Pilot Who Changed the Art of Air Warfare
http://www.aviation-history.com/airmen/boyd.htm
Boyd then used E-M as a design tool. Until E-M came along, fighter
aircraft had been designed to fly fast in a straight line or fly high
to reach enemy bombers. The F-X, which became the F-15, was the first
Air Force fighter ever designed with maneuvering specifications. Boyd
was the father of the F-15, the F-16, and the F-18.
... snip ...
--- Boyd version of wild ducks:
"There are two career paths in front of you, and you have to choose
which path you will follow. One path leads to promotions, titles, and
positions of distinction.... The other path leads to doing things that
are truly significant for the Air Force, but the rewards will quite
often be a kick in the stomach because you may have to cross swords
with the party line on occasion. You can't go down both paths, you
have to choose. Do you want to be a man of distinction or do you want
to do things that really influence the shape of the Air Force? To be
or to do, that is the question."
... snip ...
--- IBM communication group was fighting off release of mainframe TCP/IP support. When they lost, they said it had to be released through them (because they had corporate ownership of everything that crossed datacenter walls). What shipped got aggregate 44kbytes/sec using nearly whole 3090 CPU. I then add RFC 1044 support and in some tuning tests at Cray Research between Cray and 4341, got sustained 4341 channel throughput using only modest amount of 4341 CPU (something like 500 times improvement in bytes moved per instruction executed).
--- IBM AWD (workstation division) did PC/RT and their own cards (AT/bus), including 4mbit T/R card. For RS/6000 (microchannel), they were told they couldn't do their own cards, but had to use (communication group heavily performance kneecapped) PS2 microchannel cards; an example: the PC/RT 4mbit T/R had higher card throughput than the PS2 16mbit T/R microchannel card (joke that PC/RT 4mbit T/R server would have higher throughput than RS/6000 16mbit T/R server. Also $69 10mbit Ethernet cards had significant higher throughput than the $800 (PS2 microchannel) 16mbit T/R cards.
--- Late 80s, a senior disk engineer got a talk scheduled at world-wide, annual, internal communication group conference, supposedly on 3174 performance ... but open the talk with statement that the communication group was going to be responsible for the demise of the disk division. The disk division was seeing drop in disk sales with data fleeing mainframe datacenters to more distributed computing friendly platforms. The disk division had come up with a number of solutions, but they were constantly being vetoed by the communication group (with their corporate ownership of everything that crossed the datacenter walls) trying to protect their dumb terminal paradigm. Senior disk software executive partial countermeasure was investing in distributed computing startups that would use IBM disks (he would periodically ask us to drop in on his investments to see if we could offer any assistance). The communication group stranglehold on mainframe datacenters wasn't just disks and a couple years later, IBM has one of the largest losses in the history of US companies
--- in 89/90, the Marine Corps Commandant leverages Boyd for makeover of
the corps; at a time when IBM was desperately in need of a makeover
and was reorganized into the 13 "baby blues" in preparation for
breaking up the company (take-off on "baby bell" breakup decade
earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
--- turn of the century IBM mainframe (hardware) was a few percent of revenue and dropping. Early last decade ago, IBM financials had mainframe hardware a couple percent of IBM revenue (and still dropping), but the IBM mainframe group was 25% of IBM revenue (and 40% of profit), nearly all software and services.
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
Future system posts
https://www.garlic.com/~lynn/submain.html#futuresys
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
demise of disk division and communication group stranglehold posts
https://www.garlic.com/~lynn/subnetwork.html#emulation
IBM CEO & former AMXEX president
https://www.garlic.com/~lynn/submisc.html#gerstner
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
IBM internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
RFC 1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
John Boyd posts and web URLs
https://www.garlic.com/~lynn/subboyd.html
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: Acoustic couplers Newsgroups: alt.folklore.computers Date: Sun, 25 Jan 2026 09:55:22 -1000danny burstein <dannyb@panix.com> writes:
IBM CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support including automagic
terminal type (changing terminal type port scanner). Univ. had a bunch
of ASCII/TTY terminals and I add ASCII terminal support to CP/67
integrated with automagic terminal type. I then want to have a single
dial-in number for all terminals ("hunt group"). Didn't quite work,
while IBM controller could change terminal type port scanner, they had
hard wire port speed. This kicks off univ program, build a channel
interface board for Interdata/3 programmed to emulate IBM controller
(but with automatic line speed). It was later upgraded to Interdata/4
for channel interface and cluster of Interdata/3s for ports. Interdata
and later Perkin/Elmer sells as clone IBM controller and four of us get
written up for some part of IBM controller clone business.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
acoustic couplers for tty & 2741 terminal dial-in, 2nd half of the 60s.
IBM CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
IBM plug-compatible/clone controllers
https://www.garlic.com/~lynn/submain.html#360pcm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: High Availability Date: 25 Jan, 2026 Blog: FacebookLater half 70s, I transfer out to SJR on the west coast, I worked with Jim Gray and Vera Watson on the original SQL/Relational, "System/R" (developed on 370/145). Was able to do technology transfer to Endicott ("under the radar" while the company preoccupied with next great DBMS, "EAGLE") for SQL/DS. Then Jim leaves for Tandem, fall 1980. Later "EAGLE" implodes, there is request about how fast can System/R be ported to MVS, which is eventually released as DB2 (originally for decision support *ONLY*).
Late 70s & early 80s I was blamed for online computer conferencing on
the internal network. It really took off the spring of 1981 when I
distributed a trip report to visit Jim Gray at Tandem. Only about 300
directly participated but claims that 25,000 were reading. From
IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a
fresh of breath air (sic). That's another Tandem Memos. A phrase to
worry middle management. It refers to the computer-based conference
(widely distributed in 1981) in which many technical personnel
expressed dissatisfaction with the tools available to them at that
time, and also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
--- six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore was 5of6 corporate
executive committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the
company is rapidly heading for disaster. Furthermore, people fear that
this movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their
management and with the way things are going in IBM. To an increasing
extent, people are reacting to this by leaving IBM. Most of the
contributors to the present discussion would prefer to stay with IBM
and see the problems rectified. However, there is increasing
skepticism that correction is possible or likely, given the apparent
lack of commitment by management to take action
• There is a widespread perception that IBM management has failed
to understand how to manage technical people and high-technology
development in an extremely competitive environment
... snip ....
early version of gray's service availability
https://www.garlic.com/~lynn/grayft84.pdf
and
https://pages.cs.wisc.edu/~remzi/Classes/739/Fall2018/Papers/gray85-easy.pdf
1988, Nick Donofria approves HA/6000, originally for NYTimes to move
their newspaper system (ATEX) off DEC VAXCluster. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LLNL, LANL, NCAR, etc) and commercial cluster scale-up with
RDBMS vendors (Oracle, Sybase, Ingres, Informix that had VAXcluster
support in same source base with Unix; I do distributed lock
manager with VAXCluster semantics to ease ports). Then the S/88
product administrator (relogo'ed Stratus) starts taking us around to
their customers and gets me to write a section for the
corporate continuous availability strategy document (it gets
pulled when both Rochester/as400 and POK/mainframe, complain they
can't meet the objectives). Had coined disaster survivability
and geographic survivability (as counter to disaster/recovery)
when out marketing HA/CMP. One of the visits to 1-800 bellcore
development showed that S/88 would use a century of downtime in one
software upgrade, while HA/CMP had a couple extra "nines" (compared to
S/88). Work is also underway to port LLNL supercomputer filesystem
(LINCS) to HA/CMP and working with NCAR spinoff (Mesa Archive) to
platform on HA/CMP.
Early Jan92, there was meeting with Oracle CEO and IBM/AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid-jan92, I update FSD on HA/CMP
work with national labs and FSD decides to go with HA/CMP for federal
supercomputers. By end of Jan, we are told that cluster scale-up is
being transferred to Kingston for announce as IBM Supercomputer
(technical/scientific *ONLY*) and we aren't allowed to work with
anything that has more than four systems (we leave IBM a few months
later). A couple weeks later, 17feb1992, Computerworld news ... IBM
establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 benchmarks (number of program iterations
compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, 51MIPS/CPU
RS6000/990 : (1-CPU) 126MIPS, 16-systems: 2BIPS, 128-systems: 16BIPS
Jan1999, Compaq/Tandem/Atalla sponsored secure transaction conference
https://en.wikipedia.org/wiki/Utimaco_Atalla
for me at Tandem, write up by one of the participants
https://www.garlic.com/~lynn/aepay3.htm#riskm
Also the same month I was asked to help prevent the coming economic mess (we failed), they briefed me that some investment bankers had walked away "clean" from the 80s S&L crisis, were then running Internet IPO mills (invest few million, hype, IPO for a couple billion, needed to fail to leave field clear for next round) and predicted next to get into securitized mortgages. Then in Jan2009, I was asked to webize the 1930s Pecora/Senate hearings (had been scanned fall2008) with lots of URLs showing analogies between what happen then and what happened this time (comment that congress might have appetite for doing something). I worked on it for a couple months and then get a call saying it won't be needed after all (something about capital hill had been totally buried under enormous mountains of wall street money).
trivia: former head of IBM (mainframe) POK and then Boca (PS2) ... left and was CEO for hire, 1st taking Perot public ... and then Cybersafe (one of the companies at secure transaction conference).
System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
online computer conferencing
https://www.garlic.com/~lynn/subnetwork.html#cmc
internal network
https://www.garlic.com/~lynn/subnetwork.html#internalnet
ha/cmp
https://www.garlic.com/~lynn/subtopic.html#hacmp
continuous availability, disaster
survivability, geographic survivability
https://www.garlic.com/~lynn/submain.html#available
assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
economic mess
https://www.garlic.com/~lynn/submisc.html#economic.mess
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 360, Future System Date: 26 Jan, 2026 Blog: FacebookAs undergraduate, I had taken two credit hr intro to fortran/computers and at end of semester was hired to rewrite 1401 MPIO in 360 assembler for 360/30. The univ was getting 360/67 for TSS/360 replacing 709/1401 and got a 360/30 temporarily pending 360/67s. Univ. shutdown datacenter on weekends and I got the whole place (although 48hrs w/o sleep made Monday classes hard). They gave me a pile of hardware and software manuals and I got to design and implement my own monitor, device drivers, interrupt handlers, error recovery/retry, storage management, etc and within a few weeks had 2000 card assembler program). I quickly learned first thing Sat. morning, to clean tape drives and printers, disassemble/clean/reassemble 2540 reader/punch. Sometimes production had finished early and all power was off, I had to power everything back on ... sometimes wouldn't come back up and lots of manuals and trial&error to learn to get things on. Within year of intro class, the 360/67 arrived and I was hired fulltime responsible for OS/360 (TSS/360 never came to fruition).
709 ran student jobs in less than second. Initially os/360 on (360/67 as) 360/65, ran over a minute. I install HASP cutting time in half. I then start carefully redo STAGE2 sysgen to place datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9secs. 360 never got better than 709 for student jobs until I install UofWaterloo WATFOR (on 360/65 clocked at 20,000 statements/min, 333/sec, typical student job was 30-60 statements).
Then IBM CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
Then before I graduate, I was hired into small group in Boeing CFO office to help with formation of Boeing Computer Services, consolidating all dataprocessing into an independent business unit. I think Renton was the largest IBM datacenters with 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around the machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing field for payroll (although they enlarge it to install 360/67 for me to play with when I wasn't doing other stuff). When I graduate, I join IBM CSC instead of staying with Boeing CFO.
One of my hobbies after joining CSC was enhanced production operating systems for internal datacenters. One of the first (and long time) customer was the internal online sales&marketing support HONE datacenters ... which were all consolidated in Palo Alto in the 1st half of the 70s (trivia: when FACEBOOK 1st moves into Silicon Valley, it was new bldg built next to the old consolidated US HONE datacenter). I had also been asked to do early non-US HONE installs.
Amdahl won battle to make ACS, 360 compatible ... but then ACS/360 was
killed (folklore, executives were concerned that it would advance
state-of-art too fast and IBM would loose control of the market) and
Amdahl leaves IBM to start his own clone mainframe company.
https://people.computing.clemson.edu/~mark/acs_end.html
First half of 70s, IBM has Future System, totally different and
planned to totally replace 370 (during FS, internal politics was
killing off 370 efforts, lack of new 370s during FS is credited with
giving the clone makers their market foothold). When FS implodes,
there is mad rush to get stuff back into product pipelines, including
kicking-off quick&dirty 3033&3081 efforts.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
3081 was some warned over FS ... and was going to be multiprocessor only. Amdahl single CPU MIPS was more than the initial 2-CPU 3081D aggregate MIPS. IBM doubles the CPU processor cache sizes for 2-CPU 3081K, bringing aggregate MIPS up to about the same as 1-CPU Amdahl. However, MVS documents say that 2-CPU support only has 1.2-1.5 times the throughput of single CPU (because of MVS multiprocessor support issues). This means that MVS 3081K only has .6-.75 throughput of Amdahl MVS single CPU (even though 2-CPU 3081K had approx. same aggregate MIPS as Amdahl single CPU).
trivia: also after FS implodes, I was asked to help with a 16-CPU 370 multiprocessor and we con the 3033 processor engineers into helping in their spare time (a lot more interesting than remapping 168-3 logic to 20% faster chips). Evenbody thought it was great until somebody tells head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (POK doesn't ship 16-CPU system until after turn of the century). The head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, "heads down and no distractions".
HASP, ASP, JES2, JES3, NJE/NJI posts
https://www.garlic.com/~lynn/submain.html#hasp
Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
SMP, tightly-coupled, shared memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Amdahl Computers Date: 26 Jan, 2026 Blog: FacebookAmdahl won battle to make ACS, 360 compatible ... but then IBM killed ACS/360 (folklore, executives were concerned that it would advance state-of-art too fast and IBM would loose control of the market) and Amdahl leaves IBM to start his own clone mainframe company.
First half of 70s, IBM has Future System, totally different and
planned to totally replace 370 (during FS, internal politics was
killing off 370 efforts, lack of new 370s during FS is credited with
giving the clone makers their market foothold). When FS implodes,
there is mad rush to get stuff back into product pipelines, including
kicking-off quick&dirty 3033&3081 efforts.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
3081 was some warned over FS ... and was going to be multiprocessor only. Amdahl single CPU MIPS was more than the initial 2-CPU 3081D aggregate MIPS. IBM doubles the CPU processor cache sizes for 2-CPU 3081K, bringing aggregate MIPS up to about the same as 1-CPU Amdahl. However, MVS documents say that 2-CPU support only has 1.2-1.5 times the throughput of single CPU (because of MVS multiprocessor support issues). This means that MVS 3081K only has .6-.75 throughput of Amdahl MVS single CPU (even though 2-CPU 3081K had approx. same aggregate MIPS as Amdahl single CPU).
trivia: also after FS implodes, I was asked to help with a 16-CPU 370 multiprocessor and we con the 3033 processor engineers into helping in their spare time (a lot more interesting than remapping 168-3 logic to 20% faster chips). Evenbody thought it was great until somebody tells head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (POK doesn't ship 16-CPU system until after turn of the century). The head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, "heads down and no distractions".
At same time as 16-cpu (after FS imploded), Endicott also asked me to help with 138/148 microcode assist ("ECPS", also used for 4300s). In the early 80s, I got permission to give talks at user group meetings on how ECPS was done, and after meetings, Amdahl people would grill me for more information. Amdahl had done MACROCODE (370-like instructions that ran in microcode mode), originally done to quickly respond to plethora of trivial 3033 microcode required for MVS to IPL. Amdahl was then using it to implement hypervisor ("Multiple Domain", subset of virtual machine done in microcode, note IBM wasn't able to respond until nearly decade later with LPAR).
A lot of 370/XA was for various MVS shortcomings and IBM was finding it was easier for Amdahl customers to migrate from MVS to MVS/XA (because Amdahl hypervisor allowed MVS & MVS/XA to run concurrently on the same machine). Part of IBM difficulty was after FS implosion, the head of IBM POK, had convinced corporate to kill VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA (Endicott eventually manages to acquire the VM370 product responsibility for the midrange, but had to recreate a development group from scratch).
Some of the former VM370 people did do a very simplified virtual machine ("VMTOOL") used for MVS/XA testing, but never intended for customers, production or performance purpose. As a last measure, VMTOOL was repackaged as VM/MA & VM/SF for customer limited testing. 370/XA (3081) required SIE instruction to move in & out of virtual machine mode ... but 3081 didn't have microcode space for SIE, so it needed to "page" the microcode (also affecting any kind of production performance).
trivia: Once the 3033 was out the door, the processor engineers start
on trout/3090 ... and we stayed in touch (even sneaking into POK when
banned). I've posted before old email comparing that 3090 actually
implemented SIE for production use (but PR/SM&LPARs wasn't done until
almost to 3090 end-of-life).
https://www.garlic.com/~lynn/2006j.html#email810630
Somewhat analogous to trouble POK had with customers migrating from
VS2/SVS to VS2/MVS
http://www.mxg.com/thebuttonman/boney.asp
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
posts referencing 360&370 microcode
https://www.garlic.com/~lynn/submain.html#360mcode
SMP, tightly-coupled, shared memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Mosaic and Netscape Date: 27 Jan, 2026 Blog: Facebookfrom google search:
early 80s, I got HSDT project, T1 and faster computer links (both
terrestrial and satellite) and battles with SNA group (60s, IBM had
2701 supporting T1, 70s with SNA/VTAM and issues, links were capped at
56kbit ... and I had to mostly resort to non-IBM hardware). Also was
working with NSF director and was suppose to get $20M to interconnect
the NSF Supercomputer centers. Then congress cuts the budget, some
other things happened and eventually there was RFP released (in part
based on what we already had running). NSF 28Mar1986 Preliminary
Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet
... aka NCSA ... new "supercomputer software"
https://www.ncsa.illinois.edu/
1988, HA/6000 was approved, initially for NYTimes to migrate their
newspaper system off DEC VAXCluster to RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid Jan92, convince IBM FSD to bid
HA/CMP for gov. supercomputers. Late Jan92, cluster scale-up is
transferred for announce as IBM Supercomputer (for
technical/scientific *ONLY*) and we are told we can't do clusters with
anything that involve more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
After leaving IBM, was brought in as consultant to small client/server startup, two former Oracle people (that had worked on HA/CMP and were in the Ellison/Hester meeting) are there responsible for something called "commerce server" and they want to do payment transactions. The startup had also invented this stuff they called "SSL" they want to use, it is now frequently called "e-commerce". I had responsibility for everything between web servers and payment networks, including the payment gateways. One of the problems with HTTP&HTTPS were transactions built on top of TCP ... implementation that sort of assumed long lived sessions. As webserver workload ramped up, web servers were starting to spend 95+% of CPU running FINWAIT list. NETSCAPE was increasing number of company servers and trying to spread the workload. Eventually NETSCAPE installs a large multiprocessor server from SEQUENT (that had also redone DYNIX FINWAIT processing to eliminate that non-linear increase in CPU overhead).
I was told that NCSA complained that they couldn't use the name "MOSAIC" and they acquired "NETSCAPE" from another silicon valley company.
e-commerce and payment transaction posts
https://www.garlic.com/~lynn/subnetwork.html#gateway
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Amdahl Computers Date: 27 Jan, 2026 Blog: Facebookre:
One of my hobbies after joining IBM was enhanced production operating systems for internal datacenters (and the internal online sales&marketing HONE systems was one of the 1st and long-time customer). In the morph of CP67->VM370, lots of stuff was simplified or dropped (like multiprocessor support). In 1974, I start adding bunch of stuff back into a VM370R2-base for my CSC/VM (including kernel re-org for multiprocessor, but not the actual multiprocessor support). Then I add multiprocessor support back into a VM370R3-base CSC/VM, originally for HONE so they could upgrade with 2nd CPU for their 158 & 168 systems (getting twice throughput of single CPU systems).
Part of 370 2-CPU is IBM reducing CPU processor cycle speed by 10% (to offset the cross-cache protocol, making 2-CPU hardware processing only 1.8times a single processor). In order to get twice the throughput of 1-CPU, needed to have highly optimized SMP support and cache-affinity support that effectively improved cache-hit ratio, resulting in higher effective MIP rate (analogous to what 3081K achieved by doubling the size of the 3081D processor caches).
The IBM 23Jun1969 unbundling announcement started to charge for (application) software (but managed to make case that kernel software was still free), SE services, maint. etc. After the FS implosion (and the rise of clone 370 makers), it was decided to transition to charging for 370 kernel software (initially add-ons, with rule that direct hardware support was still free and couldn't depend on charged for software; that is until the 80s when all kernel software became charged for).
My dynamic adaptive scheduling (part of my internal CSC/VM) was chosen as the initial guinea pig (which was part of my VM370R2-base CSC/VM). What I actually did was include nearly everything in my VM370R2-base CSC/VM moved to VM370R3-base (including multiprocessor kernel reorg) for charged-for kernel add-on. Then IBM wanted to release multiprocessor support in VM370R4 ... but it was dependent on (required) the VM370R2-base CSC/VM kernel re-org that was part of the VM370R3-base charged-for kernel. Eventually it was decided that approx. 90% of the code in my VM370R3 charged for kernel code add-on, had to be moved into the "free" VM370R4 kernel (as part of releasing multiprocessor support in VM370R4).
All this contributing to head of POK getting corporate to kill the VM370 product.
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
IBM 23Jun1969 unbundling announce posts
https://www.garlic.com/~lynn/submain.html#unbundle
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: 360 Channel Date: 29 Jan, 2026 Blog: FacebookUndergraduate I took a two credit hour intro to fortran/computers. At the end of semester, I was hired to rewrite 1401 MPIO in assembler for 360/30. The univ was getting 360/67 for tss/360 replacing 709/1401 (360/30 temporarily replaced 1401 pending arrival of 360/67). The univ. shutdown datacenter on weekends and I would have the place dedicated (although 48hrs w/o sleep made monday classes hard). I was given pile of hardware&software manuals and got to design & implement monitor, device drivers, interrupt handlers, error recovery, storage management, etc. and within a few weeks had 2000 card assembler program.
Within a year of taking intro class, the 360/67 arrives and I was hired fulltime responsible for OS/360 (tss/360 never came to production). The 709 ran student fortran jobs in under second, but initially with os/360, they ran over a minute (MFT9.5). I install HASP which cuts the time in half. I then start redoing SYSGEN STAGE2 (MFT11-MFT14), to carefully place datasets and PDS members to optimize disk arm seek and multi-track search ... cutting another 2/3rds to 12.9secs; it never got better than 709 until I install UofWaterloo WATFOR. MVT15/16 (15 was late so merged into combined 15/16) shipped being able to select VTOC cylinder (and played games w/VTOC cyl, optimizing arm seek). At one point had few 3rd shift test shots in IBM Regional center. During the day, I wander around the bldg looking for stuff to do and found MVT debugging class and asked if I could sit in. It lasted for ten minutes, before instructor asked me to leave (was suggesting better debugging).
Along the way, CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support including automagic
terminal type (changing terminal type port scanner). Univ. had a bunch
of ASCII/TTY terminals and I add ASCII terminal support to CP/67
integrated with automagic terminal type. I then want to have a single
dial-in number for all terminals ("hunt group"). Didn't quite work,
while IBM controller could change terminal type port scanner, they had
hard wire port speed. This kicks off univ program, build a channel
interface board for Interdata/3 programmed to emulate IBM controller
(but with automatic line speed). It was later upgraded to Interdata/4
for channel interface and cluster of Interdata/3s for ports. Interdata
and later Perkin/Elmer sells as clone IBM controller and four of us
get written up for some part of IBM controller clone business.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
First bug when we connected Interdata to channel was 360/67 would red-light. 360/67 had fast/13mic loc. 80 timer. If controller/channel held the memory bus when timer went to "tic" it would hold the memory update ... if memory bus was still held for the next timer tic, the machine would red light (can't hold for more than 13mic, across two possible loc. 80 memory timer tic updates).
While still undergraduate, was hired fulltime into small group in the Boeing CFO office to help with the formation of Boeing Computer Services (consolidate all dataprocessing into an independent business unit). I think Renton datacenter largest IBM datacenter in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in the hallways around the machine room. Lots of politics between Renton director and CFO, who only had a 360/30s up at Boeing field for payroll ... although they enlarge the room for a 360/67 for me to play with when I wasn't doing something else. Then when I graduate, I join the IBM Cambridge Scientific Center (instead of staying with CFO).
Second half of 70s, I transfer from CSC to SJR on the west coast ... and work with Jim Gray and Vera Watson on original SQL/relational, System/R. I also get to wander around datacenters in silicon valley, including DASD bldg14/engineering and bldg15/product test across the street. They were doing 7x24, pre-scheduled, stand-alone testing and mentioned they had recently tried MVS, but it had 15min MTBF (in that environment). I offered to to rewrite I/O supervisor to make it bullet proof and never fail, allowing any amount of ondemand, concurrent testing, greatly improving productivity. One of the problems was new GPD president directed that cheap, slow processor to be used for the 3880 controller (possibly because thought 3880 data streaming channel support had custom hardware for actual data transfer). The slow processor made rest of channel protocol (other than actual data streaming transfer) and trying to compensate, they started games transferring channel program end interrupt as soon as data transfer had been completed (but not before 3880 controller finished operation ... assuming it could happen asynchronous while software cleaned up operation). It turns out that "unit check" condition later, and they would present UC interrupt independently. We got into arguments when I pointed out that violated channel architecture. Things escalated to conference call with POK channel architects and GPD was told I was right. From then on, controller/disk engineers invited me to attend design meetings and POK conference calls.
I did an internal only research report on the I/O Integrity work and happen to mention MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
1980, STL (since renamed SVL) was bursting at seams and 300 people/terminals from IMS group were being moved to offsite bldg, with dataprocessing service back to STL datacenter. They had tried "remote 3270" but found human factors totally unacceptable. I get con'ed into doing channel extender support, allowing placing 3270 controllers at offsite bldg with no perceived difference in human factors. Unanticipated side-effect was the associated systems' throughput increase 10-15 percent. STL had been speading 3270 controllers across all channels with 3330 drives. The channel-extenders significantly reduced the channel busy interference with the 3330 drives (for same amount of 3270 traffic; there was some consideration moving all 3270 controllers to channel-extenders).
Trout/3090 configured number of channels to achieve target throughput assuming 3880 was like 3830 but with data streaming 3mbyte/sec transfer. When they found out how bad 3880 channel busy actually was, they released they would have to greatly increase the number of channels. The number of channel increase required an extra TCM and they semi-facetiously said they would bill the 3880 group for the increase in 3090 manufacturing cost. Eventually sales/marketing respun the big increase in channels as 3090 a great I/O machine (even though it was purely to offset the big increase in 3880 channel busy).
cambridge scientific center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
360 plug compatible controller
https://www.garlic.com/~lynn/submain.html#360pcm
playing disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
some recent posts mentioning undergraduate: 1401 MPIO for 360/30, univ
responsible OS/360, watfor, rewrite lots of CP67, work in small group
for Boeing CFO:
https://www.garlic.com/~lynn/2026.html#24 IBM 360, Future System
https://www.garlic.com/~lynn/2025e.html#104 Early Mainframe Work
https://www.garlic.com/~lynn/2025e.html#74 IBM 370 Virtual Memory
https://www.garlic.com/~lynn/2025e.html#57 IBM 360/30 and other 360s
https://www.garlic.com/~lynn/2025d.html#112 Mainframe and Cloud
https://www.garlic.com/~lynn/2025d.html#99 IBM Fortran
https://www.garlic.com/~lynn/2025d.html#15 MVT/HASP
https://www.garlic.com/~lynn/2025c.html#115 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#64 IBM Vintage Mainframe
https://www.garlic.com/~lynn/2025c.html#55 Univ, 360/67, OS/360, Boeing, Boyd
https://www.garlic.com/~lynn/2025b.html#59 IBM Retain and other online
https://www.garlic.com/~lynn/2025.html#91 IBM Computers
https://www.garlic.com/~lynn/2024g.html#39 Applications That Survive
https://www.garlic.com/~lynn/2024g.html#17 60s Computers
https://www.garlic.com/~lynn/2024f.html#124 Any interesting PDP/TECO photos out there?
https://www.garlic.com/~lynn/2024f.html#110 360/65 and 360/67
https://www.garlic.com/~lynn/2024f.html#88 SHARE User Group Meeting October 1968 Film Restoration, IBM 360
https://www.garlic.com/~lynn/2024f.html#69 The joy of FORTH (not)
https://www.garlic.com/~lynn/2024f.html#20 IBM 360/30, 360/65, 360/67 Work
https://www.garlic.com/~lynn/2024e.html#136 HASP, JES2, NJE, VNET/RSCS
https://www.garlic.com/~lynn/2024d.html#103 IBM 360/40, 360/50, 360/65, 360/67, 360/75
https://www.garlic.com/~lynn/2024d.html#76 Some work before IBM
https://www.garlic.com/~lynn/2024d.html#22 Early Computer Use
https://www.garlic.com/~lynn/2024c.html#93 ASCII/TTY33 Support
https://www.garlic.com/~lynn/2024c.html#15 360&370 Unix (and other history)
https://www.garlic.com/~lynn/2024b.html#97 IBM 360 Announce 7Apr1964
https://www.garlic.com/~lynn/2024b.html#63 Computers and Boyd
https://www.garlic.com/~lynn/2024b.html#60 Vintage Selectric
https://www.garlic.com/~lynn/2024b.html#44 Mainframe Career
https://www.garlic.com/~lynn/2024.html#87 IBM 360
https://www.garlic.com/~lynn/2024.html#43 Univ, Boeing Renton and "Spook Base"
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: 360 Channel Date: 29 Jan, 2026 Blog: Facebookre:
1988, branch office asks if I could help LLNL (national lab) standardize some serial stuff they were working with which quickly becomes fibre-channel standard ("FCS", including some stuff I had done in 1980, initially 1gbit transfer, full-duplex, aggregate 200mbyte/sec). Then IBM mainframe release some serial (when it was already obsolete) as ESCON, initially 10mbyte/sec, upgrading to 17mbyte/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight protocol that drastically cuts native throughput, eventually ships as FICON. Around 2010 was a max configured z196 public "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON, running over FCS). Note IBM docs has SAPs (system assist processors that do actual I/O) CPU be kept to 70% ... or 1.5M IOPS ... also no CKD DASD have been made for decades (just simulated on industry fixed-block devices).
Trivia: in the wake of Future System implosion, I got asked to help with 16-CPU 370 and we con the 3033 processor engineers into working on it in their spare time (a lot more interesting than remapping 168-3 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effectivee) 16-CPU support (docs at the time said MVS 2-CPU multiprocessor support only had 1.2-1.5 times the throughput of single CPU, POK doesn't ship 16-CPU support until after turn of the century). The head of POK then invites some of us to never visit POK again and directs the 3033 processor engineers "heads down and no distractions". Then once 3033 was out the door, the processor engineers start on trout/3090.
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared-memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: 360 Channel Date: 29 Jan, 2026 Blog: Facebookre:
FS totally different from 370 and was going to completely replace it. During FS internal politics was killing off 370 projects and lack of new 370 during the period is credited with giving 370 makers their market foothold. When FS finally implodes there is made rush to get stuff back into 370 product pipelines, including kick off quick&dirty 3033&3081 efforts in paralle. One of the last nails in the FS coffin was study by the IBM Houston Scientific Center that if 370/195 apps were redone for FS machine made out of the fastest available technology, they would have throughput of 370/145 (about 30 times slowdown).
For 303x channel director they took 158 engine with the integrated
channel microcode (and no 370 microcode). A 3031 was two 158 engines,
one with just 370 microcode and one with integrated channel
microcode. A 3032 was 168-3 redone for 303x channel director for
external channels. A 3033 started out remapping 168-3 microcode to 20%
faster chips.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CICS & DB2 Date: 30 Jan, 2026 Blog: FacebookTrivia: as undergraduate, I had been hired fulltime by the univ responsible for OS/360 (univ had 360/67 to replace 709/1401, originally for tss/360 but didn't come to fruition, so ran as 360/65). Then the Univ. library got ONR grant and used some of the money for 2321 datacell. IBM also selected it as betatest for the original CICS program product and CICS support was added to my tasks. some CICS history ... website gone 404, but lives on at the wayback machine
1st problem was CICS wouldn't come up, turned out (betatest) CICS had some (undocumented) hard coded BDAM dataset options and library had created BDAM datasets with different set of options.
When I graduate, I join the IBM Cambridge Scientific Center ... then less than decade later, I transfer out to SJR on the west coast and worked with Jim Gray and Vera Watson on the original SQL/relational, System/R. Then was able to do tech transfer ("under the radar" while company was preoccupied with the next, new DBMS, "EAGLE") to Endicott for SQL/DS. Then when EAGLE imploded, there was request for how fast could System/R be ported to MVS, which was eventually released as DB2 (originally for decision support only).
CICS &/or BDAM posts
https://www.garlic.com/~lynn/submain.html#cics
science center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
original sql/relational System/R
https://www.garlic.com/~lynn/submain.html#systemr
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM SNA Date: 31 Jan, 2026 Blog: FacebookUndergraduate in the 60s, I was hired fulltime responsible for os/360. Univ. was getting 360/67 for tss/360 replacing 709/1401, but tss/360 didn't come to production so ran as 360/65. then csc came out to install (virtual machine) cp67 (3rd installation after csc itself and MIT Lincoln labs) and I mostly got to play with it during my weekend dedicated time. CP67 came with automagic terminal type support for 1052 & 2741. The univ had some number of tty33 & tt35 ascii so I add ASCII terminal type support integrated with recognizing terminal type and switching terminal type port scanner. I then want to have single phone number ("hunt group") for all terminals. Didn't quite work since IBM had taken short cut and hardwired the line speed, kicks off univ. project to build our own clone IBM controller. Build a channel interface board for Interdata/3 programmed to emulate IBM controller with addition to do auto baud rate. It is then upgraded for Interdata/4 for channel interface and clusters of Interdata/3s for port interfaces. Interdata (and then Perkin/Elmer) was marketing at IBM clone controller (and four of us get written up for some part of IBM clone controller business.
After I graduate, I join CSC and after a few years, transfer out to SJR on the west coast. 1980, STL (since rename SVL) is bursting at the seams and 300 people (& 3270s) are being moved to offsite bldg., with dataprocessing service back to STL datacenter. They had tried "remote 3270" but found human factors totally unacceptable. I get con'ed into doing channel extender support, allowing placing 3270 controllers at offsite bldg with no perceived difference in human factors. Unanticipated side-effect was the associated systems' throughput increase 10-15 percent. STL had been spfeading (slow & high channel busy) 3270 controllers across all channels with 3330 drives. The channel-extenders significantly reduced the channel busy interference with the 3330 drives (for same amount of 3270 traffic; there was some consideration moving all 3270 controllers to channel-extenders, masking the significant overhead & channel busy from 3270 controllers).
... 1981, I got HSDT project, T1 and faster computer links and lots of
conflict with corporate communication product group (note, 60s, IBM
had 2701 telecommunication controller that had T1 support, then with
the move to SNA/VTAM and associated issues capped controllers at
56kbits/sec. HSDT was working with NSF director and was suppose to get
$20M to interconnect the NSF Supercomputer center. Then congress cuts
the budget, some other things happen and eventually an RFP is released
(in part based on what we already had running). NSF 28Mar1986
Preliminary Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
The communication group was fighting off release of mainframe TCP/IP support. When they lost, they change strategy and said that since they had corporate responsibility for everything that crosses datacenter walls, it had to be release through them. What shipped used nearly whole 3090 CPU getting aggregate 44kbytes/sec. I then add RFC1044 support and in some tuning tests at Cray Research between Cray and 4341, get aggregate sustained 4341 channel throughput using only modest amount of 4341 processor (something like 500 times improvement in bytes moved per instruction executed).
IBM AWD (workstation) got to do their own cards for the PC/RT (PC/AT bus), including 4mbit token-ring cards. Then for microchannel RS/6000, they were told they couldn't do their own cards, but have to use (heavily performance kneecapped by the communication group) microchannel cards (the PC/RT 4mbit token ring card had higher card throughput than the PS2 microchannel 16mbit token ring card; joke that a PC/RT 4mbit T/R server would have higher throughput than RS/6000 16mbit T/R server). $69 10mbit Ethernet cards had much higher throughput than the $800 16mbit token-ring PS2 microchannel cards.
1988, Nick Donofria approves HA/6000, originally for NYTimes to
migrate their newspaper system off DEC VAXCluster to RS/6000. I rename
it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics).
Early Jan92, have a meeting with Oracle CEO where IBM AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid Jan92, convince IBM FSD to bid
HA/CMP for gov. supercomputers. Late Jan92, cluster scale-up is
transferred for announce as IBM Supercomputer (for
technical/scientific *ONLY*) and we are told we can't do clusters with
anything that involve more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
After leaving IBM, was brought in as consultant to small client/server startup, two former Oracle people (that had worked on HA/CMP and were in the Ellison/Hester meeting) are there responsible for something called "commerce server" and they want to do payment transactions. The startup had also invented this stuff they called "SSL" they want to use, it is now frequently called "e-commerce". I had responsibility for everything between web servers and payment networks, including the payment gateways. One of the problems with HTTP&HTTPS were transactions built on top of TCP ... implementation that sort of assumed long lived sessions. As webserver workload ramped up, web servers were starting to spend 95+% of CPU running FINWAIT list. NETSCAPE was increasing number of company servers and trying to spread the workload. Eventually NETSCAPE installs a large multiprocessor server from SEQUENT (that had also redone DYNIX FINWAIT processing to eliminate that non-linear increase in CPU overhead).
I then do a talk on "Why Internet Isn't Business Critial Dataprocessing", based on documentation, procedures and software that I had to do for e-commerce that (Internet IETF RFC standards editor) Postel sponsored at ISI/USC.
Late 80s, a senior disk engineer got a talk scheduled at world-wide, annual, internal communication group conference, supposedly on 3174 performance ... but open the talk with statement that the communication group was going to be responsible for the demise of the disk division. The disk division was seeing drop in disk sales with data fleeing mainframe datacenters to more distributed computing friendly platforms. The disk division had come up with a number of solutions, but they were constantly being vetoed by the communication group (with their corporate ownership of everything that crossed the datacenter walls) trying to protect their dumb terminal paradigm. Senior disk software executive partial countermeasure was investing in distributed computing startups that would use IBM disks (he would periodically ask us to drop in on his investments to see if we could offer any assistance). The communication group stranglehold on mainframe datacenters wasn't just disks and a couple years later, IBM has one of the largest losses in the history of US companies
In early 80s, I was introduced to John Boyd and would sponsored his
briefings at IBM In 89/90, The Marine Corps Commandant leverages Boyd
for makeover of the corps; at a time when IBM was desperately in need
of a makeover; was being reorganized into the 13 "baby blues" in
preparation for breaking up the company (take-off on "baby bell"
breakup decade earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
360 clone/compatible controller posts
https://www.garlic.com/~lynn/submain.html#360pcm
IBM CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
channel extender posts
https://www.garlic.com/~lynn/submisc.html#channel.extender
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
RFC 1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
demise of disk division and communication group stranglehold posts
https://www.garlic.com/~lynn/subnetwork.html#emulation
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
e-commerce, internet payment network gateway posts
https://www.garlic.com/~lynn/subnetwork.html#gateway
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM, NSC, HSDT, HA/CMP Date: 01 Feb, 2026 Blog: Facebook1980, IBM STL (since renamed SVL) was bursting at the seams and were moving 300 people & 3270s from the IMS group to offsite bldg and had tried "remote 3270", but found the human factors totally unacceptable. I got con'ed into providing channel-extender support so channel attached 3270 controllers could be placed at the offsite bldg with no human factors difference between in STL and offsite. Did have problems, it used NSC A220/A710/A710/A510 (A220 attached to IBM channel, A710s on each end of telco link, A510 emulating IBM channel) ... and claimed A710 supported full-duplex. NSC support didn't actually schedule channel programs that might cause traffic to flow full-duplex. I learned to pace activity to try and damp down probability of concurrent traffic in both directions. Temporary got pair of 720 satellite link adapters (two boxes on each end, dedicated for traffic in each direction) until they came out with A715 that actually supported full-duplex traffic.
From law of unintended consequences, STL had spread 3270 controllers across all the mainframe channels with 3830 disk controllers. Substituting direct attached A220s reduced the really channel busy, improving 3830/3330 disk throughput, increasing system throughput by 10%-15% (and once a got full-duplex telco operation) had no degradation in 3270 terminal throughput. There was some consideration to move all channel-attached 3270 controllers behind A220s/A510s.
NSC asked if IBM would allow release of my support, but there was group in POK that were afraid if it was in the market, they would have problems justify release some of their stuff ("ESCON") and got it veto'ed. NSC then duplicated my support. Five years later, I got a call from the IBM 3090 product administrator. He said 3090 channel FEC was designed that their would only an aggregate of 3-5 channel errors across all 3090 systems for a year period but found 15-20 errors were reported (there was a industry operation that collected customer EREP information for all IBM and non-IBM clone systems and published them). Turns out in 1980, I simulated "channel check" (for any kind of NSC error) to invoke error retry/recovery and was copied by NSC. I then did some research and found IFCC (interface control check) would effectively invoke the same retry/recovery and got NSC to change their "CC" to "IFCC" (to improve the 3090 comparison to clone 370 makers).
A510 channel emulation didn't handle CKD DASD channel programs. NSC eventually came out with A515, (I believe) initially for NCAR, that could handle CKD DASD channel programs. The was an IBM mainframe system with A220s that could access all the A515s ... and all the other (super) computers all had access the A515s. Supercomputers would send request to IBM system for specific data. The IBM system would download channel program into A515 and return the "handle" for the channel program to the requesting supercomputer, and the supercomputer can use the channel program "handle" to execute the A515 channel program. I got several requests from the IBM NCAR account team for help on implementation.
trivia-1: when I transferred from Cambridge Science Center (on east coast) to San Jose Research (on west coast) in 1977, I got to wander around IBM datacenters in silicon valley, including disk bldg14/engineering and blg15/product test across the street. At the time they were doing 7x24, prescheduled, stand-alone testing and mentioned they had recently tried "MVS", but it had 15min MTBF (in that environment). I offer to rewrite the I/O supervisor to make it bullet-proof and never fail, allowing any amount of on-demand, concurrent testing, greatly improving productivity. I assume that my rewriting I/O supervisor for disk engineering/product test brought me to attention of STL. I then write an internal research report on I/O Integrity and happen to mention MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
trivia-2: Early 1980s, got HSDT project, T1 and faster computer links (both terrestrial and satellite) and battles with IBM communication group (60s, IBM had 2701 controllers that supported T1 links but 70s "SNA" with issues that capped controllers at 56kbits ... so had to use lots of non-IBM hardware). Mid-80s IBM Communication group was fighting release of mainframe TCP/IP support and when they lost, they change their strategy. Because they had corporate ownership of everything that crossed datacenter walls, it had to be released through them. What shipped got aggregate 44kbytes/sec throughput using nearly whole 3090 processor. I then add RFC1044 support and in some tuning tests at Cray Research between Cray and IBM 4341 got sustained 4341 channel throughput using only modest amount of 4341 processor (something like 500 times improvement in bytes moved per instruction executed).
HSDT was suppose to have got $20M to interconnect the NSF
Supercomputer Centers, then their budget was but, other things
happened and eventually an RFP was released (in part based on what we
already had running). NSF 28Mar1986 Preliminary Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet
trivia-3: 1988, IBM branch office asks if I could help LLNL (national lab) standardize some serial stuff they were working with, which quickly becomes fibre-channel standard ("FCS", including some stuff I had done with NSC in 1980, initial 1gbit transfer, full-duplex, aggregate 200mbyte/sec). Then POK gets their stuff released as ESCON (when it was already obsolete), initially 10mbytes/sec, upgraded to 17mbytes/sec. Later some POK engineers become involved with "FCS" and defines a protocol that significantly reduces "FCS" throughput, eventually released as FICON. Pulbic released benchmark was Z196 "Peak I/O" getting 2M IOPS with 104 FICONs (20K IOPS/FICON). About the same time, a FCS was announced for E5-2600 server blades that got over million IOPS (two such FCS higher throughput than 104 FICONs). Also, IBM docs advise SAPs (system assist processors that does actually I/O) CPUs be kept to 70% (or 1.5M IOPS) ... as well as no CKD DASD have been made for decades, all being simulated on industry standard fixed-block devices.
trivia-4: Also 1988, Nick Donofrio approves HA/6000, originally for
NYTimes to migrate their newspaper system off DEC VAXCluster to
RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc, also porting LLNL LINCS and NCAR
filesystems to HA/CMP) and commercial cluster scale-up with RDBMS
vendors (Oracle, Sybase, Ingres, Informix) that had VAXCluster support
in same source base with unix (also do DLM supporting VAXCluster
semantics). LINCS was being standardized as UNITREE and NCAR had
spun-off their filesystem as "Mesa Archival" (and the IBM disk
division had invested in "Mesa Archival").
Early Jan1992, meeting with Oracle CEO, IBM AWD executive Hester tells
Ellison that we would have 16-system clusters mid92 and 128-system
clusters ye92. Mid-jan1992, convinced IBM FSD to bid HA/CMP for
gov. supercomputers. Late-jan1992, HA/CMP is transferred for announce
as IBM Supercomputer (for technical/scientific *ONLY*), and we were
told couldn't work on clusters with more than 4-systems (we leave IBM
a few months later). A couple weeks after cluster scale-up transfer,
17feb1992, Computerworld news ... IBM establishes laboratory to
develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 benchmarks (number of program iterations
compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, 51MIPS/CPU
RS6000/990 : (1-CPU) 126MIPS, 16-systems: 2BIPS, 128-systems: 16BIPS
Channel-extender posts
https://www.garlic.com/~lynn/submisc.html#channel.extender
playing disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
RFC1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM, NSC, HSDT, HA/CMP Date: 03 Feb, 2026 Blog: Facebookre:
IBM had done thin-film head with lower flying height, going from 3330
800kbyte/sec to 3mbyte/sec transfer (3380)
https://www.computerhistory.org/storageengine/thin-film-heads-introduced-for-large-disks/
IBM channels had been end-to-end handshake for every byte transferred
... limiting 1.5mbyte/sec (a few 3mbyte/sec were done using pairs of
channel cables). For 3mbyte/sec, went to "data streaming" with
multiple bytes per end-to-end handshake.
Original 3380 had 20 track spacings between every data track. They then cut data track spacing in half for double the number of cylinders (and capacity) ... then cut spacing again for triple the capacity.
1987, "father of 801/risc" wanted me to help him with proposal for further reduction in track spacing and a "WIDE" disk head that transferred 16 data tracks in parallel (format was servo track on each side of 16 data track groupings that disk head would follow). Problem was 50mbyte/sec transfer and IBM mainframe only handled 3mbyte/sec. A couple months later I was asked to help LLNL standardize some serial stuff that initially handled 1gbit/sec.
A couple years later, IBM announces it serial channel, but only
10mbytes/sec (later upgraded to 17mbytes/sec).
https://en.wikipedia.org/wiki/ESCON
RAID could get 50mbyte/sec just using multiple industry standard
disks, transferring, synchronized in parallel.
https://en.wikipedia.org/wiki/RAID
trivia: mentions Ken Ouchi and RAID4 in 1977 (I got to play disk
engineer part time starting in 1977
... aka 1977 I transfer from Cambridge Scientific Center (east coast) to San Jose Research (west coast) and get to wander around silicon valley datacenters, including disk bldg14/engineering and bldg15/product test across the street. They were running 7x24, prescheduled, stand-alone testing and mentioned they had recently tried MVS, but it had 15min MTBF (in that environment, requiring manual re-ipl). I offered to rewrite I/O supervisor making it bullet-proof and never fail, allowing any amount of on-demand, concurrent testing (greatly improving productivity). I then write an internal-only I/O Integrity research report and happen to mention MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
Because had to emulate channel architecture, was quick to discover errors and/or architecture deviations ... and they wanted me to start participating in design meetings.
Bldg15 got 1st engineering 3033 out of POK processor engineering ... and since testing only took a percent or two of CPU, we scrounge up 3830 and 3330 string setting up our private online service. Then found that the thin-film air bearing simulation was only getting one or two turn arounds/month on SJR MVT 370/195, we set them up on bldg15 3033 where they can get as many turn arounds/day as they wanted.
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
cambridge science center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
some recent posts mentioning air bearing simulation
https://www.garlic.com/~lynn/2025e.html#50 IBM Disks
https://www.garlic.com/~lynn/2025e.html#29 IBM Thin Film Disk Head
https://www.garlic.com/~lynn/2025d.html#107 Rapid Response
https://www.garlic.com/~lynn/2025d.html#78 Virtual Memory
https://www.garlic.com/~lynn/2025d.html#58 IBM DASD, CKD, FBA
https://www.garlic.com/~lynn/2025d.html#1 Chip Design (LSM & EVE)
https://www.garlic.com/~lynn/2025c.html#107 IBM San Jose Disk
https://www.garlic.com/~lynn/2025c.html#102 More 4341
https://www.garlic.com/~lynn/2025c.html#62 IBM Future System And Follow-on Mainframes
https://www.garlic.com/~lynn/2025b.html#112 System Throughput and Availability II
https://www.garlic.com/~lynn/2025b.html#47 IBM Datacenters
https://www.garlic.com/~lynn/2025b.html#25 IBM 3880, 3380, Data-streaming
https://www.garlic.com/~lynn/2025b.html#12 IBM 3880, 3380, Data-streaming
https://www.garlic.com/~lynn/2025.html#29 IBM 3090
https://www.garlic.com/~lynn/2024g.html#58 FCS, ESCON, FICON
https://www.garlic.com/~lynn/2024g.html#54 Creative Ways To Say How Old You Are
https://www.garlic.com/~lynn/2024g.html#38 IBM Mainframe User Group SHARE
https://www.garlic.com/~lynn/2024g.html#3 IBM CKD DASD
https://www.garlic.com/~lynn/2024f.html#5 IBM (Empty) Suits
https://www.garlic.com/~lynn/2024c.html#59 IBM "Winchester" Disk
https://www.garlic.com/~lynn/2023f.html#68 Vintage IBM 3380s
https://www.garlic.com/~lynn/2023f.html#58 Vintage IBM 5100
https://www.garlic.com/~lynn/2023f.html#27 Ferranti Atlas
https://www.garlic.com/~lynn/2023e.html#25 EBCDIC "Commputer Goof"
https://www.garlic.com/~lynn/2023d.html#104 DASD, Channel and I/O long winded trivia
https://www.garlic.com/~lynn/2023c.html#46 IBM DASD
https://www.garlic.com/~lynn/2023b.html#58 IBM 3031, 3032, 3033
https://www.garlic.com/~lynn/2023.html#74 IBM 4341
https://www.garlic.com/~lynn/2023.html#73 IBM 4341
https://www.garlic.com/~lynn/2022g.html#95 Iconic consoles of the IBM System/360 mainframes, 55 years old
https://www.garlic.com/~lynn/2022g.html#9 3880 DASD Controller
https://www.garlic.com/~lynn/2022c.html#74 IBM Mainframe market was Re: Approximate reciprocals
https://www.garlic.com/~lynn/2022b.html#73 IBM Disks
https://www.garlic.com/~lynn/2022.html#64 370/195
https://www.garlic.com/~lynn/2021f.html#53 3380 disk capacity
https://www.garlic.com/~lynn/2021f.html#40 IBM Mainframe
https://www.garlic.com/~lynn/2021f.html#23 IBM Zcloud - is it just outsourcing ?
https://www.garlic.com/~lynn/2021e.html#28 IBM Cottle Plant Site
https://www.garlic.com/~lynn/2021.html#6 3880 & 3380
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM, NSC, HSDT, HA/CMP Date: 03 Feb, 2026 Blog: Facebookre:
23jun1969 unbundling announce started to charge for (application)
software (but made the case that kernel software still free), SE
services, maint. etc. Early 70s, IBM had "Future System" totally
different from 370 and going to completely replace it (during FS,
internal politics was killing off 370s efforts and lack of new 370s
during FS is credited with giving clone 370 makers their market
foothold).
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
After the FS implosion there was mad rush to get stuff back into the 370 product pipeline, including kicking off the quick&dirty 3033&3081. With the the rise of clone 370 makers, it was decided to transition to charging for 370 kernel software (initially add-ons, with rule that direct hardware support was still free and couldn't depend on charged for software; then in 80s, transitioning to all kernel software became charged for).
My dynamic adaptive scheduling (part of my internal CSC/VM) was chosen as the initial guinea pig (which was part of my VM370R2-base CSC/VM). What I actually did was include nearly everything in my VM370R2-base CSC/VM moved to VM370R3-base (including multiprocessor kernel reorg) for charged-for kernel add-on. Then IBM wanted to release multiprocessor support in VM370R4 ... but it was dependent on (required) the VM370R2-base CSC/VM kernel re-org that was part of the VM370R3-base charged-for kernel. Eventually it was decided that approx. 90% of the code in my VM370R3 charged for kernel code add-on, had to be moved into the "free" VM370R4 kernel (as part of releasing multiprocessor support in VM370R4).
23jun1969 unbundling announce posts
https://www.garlic.com/~lynn/submain.html#unbundle
future system posts
https://www.garlic.com/~lynn/submain.html#futuresys
dynamic adaptive scheduling/resource management posts
https://www.garlic.com/~lynn/subtopic.html#fairshare
internal CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM, NSC, HSDT, HA/CMP Date: 03 Feb, 2026 Blog: Facebookre:
Also, in the wake of FS implosion, Endicott cons me into helping with
138/148 microcode assist, ECPS (also used by 4300s) ... 6kbyte highest
used kernel code (responsible for 79% of kernel execution) migrated to
microcode on nearly 1:1 (machines were averaging 10 microcode
instructions per 370 instruction, so represented 10 times
throughput). Archived post with initial analysis
https://www.garlic.com/~lynn/94.html#21
Endicott then tries to get corporate approval to pre-install VM370 on every 138/148 (which would have also done for 4300), but head of POK (high-end 370) was in the process of convincing corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA. Eventually Endicott does get VM370 product mission (for the mid-range), but had to recreate a development group from scratch.
San Jose bldg15 product test gets engineering 4341 in 1978 ... and branch office finds out and in Jan1979 gets me to do benchmark for national lab that was looking at getting 70 for compute farm (sort of leading edge of cluster supercomputer tsunami). Later in the 80s, large corporations were ordering hundreds of VM4341s at a time for placing out in departmental areas (inside IBM, departmental conference rooms became scarce, being converted to VM4341s rooms) ... sort of the leading edge of the coming distributed computing tsunami.
future system posts
https://www.garlic.com/~lynn/submain.html#futuresys
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
internal CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Internal Network Date: 04 Feb, 2026 Blog: FacebookSome of the MIT ctss/7094 (had msg function on same machine) people went to the 5th flr for Multics. Others went to IBM Science Center on 4th flr did virtual machines (virtual memory hardware mods for 360/40 for CP40/CMS, morphs into CP67/CMS when 360/67 standard with virtual memory became available), Science Center wide-area network (morphs into VNET/RSCS internal corporate network, larger than arpanet/internet from beginning until sometime mid/late 80s about the same time it was forced to convert to SNA/VTAM, technology also used for corporate sponsored univ BITNET), lots of other stuff ... including messaging on the same machine
CP67 "SPM" (internal; sort of superset of later combination of IUCV, VMCF, and SMSG) that was later ported to (internal) VM370. Original (CP67 & later VM370) RSCS/VNET (before ship to customers) had SPM support ... that RSCS/VNET supported to capture CP messages for local commands and/or forwarding over the network.
Co-worker was responsible for CP67-based wide-area network, one of the
1969 inventors of GML (decade later morphs ISO SGML and after another
decade morphs into HTML at CERN)
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
CSC CP67-based wide-area network then grows into the corporate internal network (larger than arpanet/internet from just about the beginning until sometime mid/late 80s when the internal network was forced to convert to SNA).
To provide MVS systems access to the internal network, there was a NJE simulation RSCS/VNET driver. There were problems with MVS/JES2 systems and had to be tightly regulated ... original HASP code had "TUCC" in cols68-71 and scavenged unused entries in the 255-entry psuedo device table (tended to be 160-180 entries). JES2/NJE would trash traffic where origin or destination node wasn't in local table ... when the internal network was well past 255 nodes (and JES2 had to be restricted to edge nodes with no or minimal forwarded traffic).
Both RSCS/VNET and MVS/JES2 want release to customers. After 23jun1969 unbundling announce, customer release required that software be charged for. Rule was revenue had to cover original development and maintenance. RSCS/VNET met the requirement at $30/month, however head of POK was in the process of convincing corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA ... and vetoed its release. Standard procedure was to forcast low/medium/high price and JES2/NJE had no forecast at $300, $600, or $1200 that met the requirement. Eventually JES2 group cut deal with VM370 to announce NJE&RSCS/VNET as a "joint" project with combined development&maint ... where most of the RSCS/VNET revenue went to covering NJE (drastically lowering the NJE price and still meeting requirement) ... and head of POK wouldn't veto release of the "combined" product).
After VM370 development group was shutdown, Endicott manages to acquire responsibility for VM370 product (for the mid-range) but had to recreate a development group from scratch. While SPM wasn't released for customers, combination of IUCV, VMCF, and SMSG was released and RSCS/VNET upgraded to use functions (that it already supported with SPM). Starting with CP67, along the way various CMS execs were developed that leveraged RSCS/VNET for various kinds of (multi-system) instant messaging.
1980 internally, there was a multi-user, client/server, 3270 spacewar game (using SPM). Almost immediately robot players appeared that beat human players and server was upgraded that power use increased non-linearly as intervals between commands dropped lower than human levels.
Also NJE fields were somewhat intermixed with job control fields and there were tenancy for traffic between JES2 systems at different release levels to crash the destination MVS. As a result the RSCS/VNET simulated NJE driver built up a large amount of code that would recognize differences between MVS/JES2 origin and destination and adjust fields to correspond to the immediate destination MVS/JES2 (further restricting MVS systems to edge/boundary node, behind a protective VM370 RSCS/VNET system). There was infamous case where changes in a San Jose MVS system was crashing MVS systems in Hursley (England) and the Hursley VM370/VNET was blamed (because they hadn't installed the updates to account for the San Jose JES2 field changes).
co-worker responsible for RSCS/VNET
https://en.wikipedia.org/wiki/Edson_Hendricks
In June 1975, MIT Professor Jerry Saltzer accompanied Hendricks to
DARPA, where Hendricks described his innovations to the principal
scientist, Dr. Vinton Cerf. Later that year in September 15-19 of 75,
Cerf and Hendricks were the only two delegates from the United States,
to attend a workshop on Data Communications at the International
Institute for Applied Systems Analysis, 2361 Laxenburg Austria where
again, Hendricks spoke publicly about his innovative design which
paved the way to the Internet as we know it today.
... snip ...
newspaper article about some of Edson's Internet & TCP/IP IBM battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed, Internet &
TCP/IP) references from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
IBM internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
BITNET (& EARN) posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
HASP/JES NJE/NJI posts
https://www.garlic.com/~lynn/submain.html#hasp
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
Eventually NJE was upgraded to support 999 nodes, but it was after the internal network had passed 1000 nodes.
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM CMS Applications Date: 05 Feb, 2026 Blog: Facebooklate 70s, san jose research fridays after work discussing on how to get more ibmers to use computers and one was online telephone book. jim gray would spend one week to implement search program and I would spend one week on processes/software for starting to collect plant site and location telephone books and converting to lookup format. Big problem were lawyers who thought online phone books needed to be classified IBM Confidential
before that were discussion on how to promote email ... initially
CP67/CMS and Science Center wide-area network (evolves into the
internal network larger than arpanet/internet from just about
beginning until sometime mid/late 80s about same time forced to
convert to SNA/VTAM. Some of the MIT 7094/CTSS (which had email)
people had joined the IBM science center on the 4th flr ... and did
virtual machines (1st modified 360/40 with virtual memory and did
CP40/CMS which morphs into CP67/CMS when 360/67 standard with virtual
memory becomes available). Account by one of the CSC members that
invented GML (morphs into SGML & HTML) in 1969 ....
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
When decision was made to add virtual memory to all 370s, decision to redo CP67 virtual machines as VM370. Late 70s, there was rapid spreading rumor that corporate executive committee were exchanging email. At the time 3270 terminals were part of annual budget and required VP sign-off. Then managers started preempting project delivery 3270s for their desks (to give impression that they were computer literate, normally powered on in the morning with logon burning into the screen all day) and their secretaries (that actually would handle their email).
After graduating and 1st joined the IBM science center, one of my hobbies was enhanced production operating systems for internal datacenters, one of the 1st and long time customer was the sales and marketing support HONE systems. 23jun1969 unbundling included starting to start charge for SE services. Up until then novice/trainee SEs were part of group on-site at customers ... but with unbundling, couldn't figure out how to not charge for trainee SE services. Multiple HONE CP67 datacenters were setup around the US with online access from branches where SEs would practice with guest operating systems in virtual machines. The science center also had redone APL\360 from 16kbyte swapped workspaces to large virtual memory demand page and APIs for system services (like file I/O), as CMS\APL for real world applications. HONE then started using CMS\APL for delivering sales&marketing support applications, which came to dominate all HONE activity (and guest operating systems just withered away).
Tymshare (commercial online VM370/CMS services)
https://en.wikipedia.org/wiki/Tymshare
https://spectrum.ieee.org/someone-elses-computer-the-prehistory-of-cloud-computing
in Aug1976, Tymshare started offering their CMS-based online computer
conferencing for free to the IBM mainframe SHARE user group
https://www.share.org/
as VMSHARE, archived here
http://vm.marist.edu/~vmshare
I cut a deal with Tymshare to get monthly tape dump of all VMSHARE files for putting up on internal network and internal systems (including HONE). Initially lawyers objected, they were concerned about exposing internal employees with unfiltered customer information (that was possibly different from corporate party line). This is similar to a 1974 CERN comparison of VM370/CMS with MVS/TSO that was presented at SHARE (copies inside IBM were stamped "IBM Confidential - Restricted")
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
SGML, GML, HTML, etc
https://www.garlic.com/~lynn/submain.html#sgml
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
23jun1969 unbundling posts
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
some recent posts mentioning online phone book
https://www.garlic.com/~lynn/2026.html#32 IBM SNA
https://www.garlic.com/~lynn/2026.html#5 PROFS and other CMS applications
https://www.garlic.com/~lynn/2025c.html#113 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#56 IBM OS/2
https://www.garlic.com/~lynn/2025c.html#0 Interactive Response
https://www.garlic.com/~lynn/2025b.html#66 IBM 3101 Glass Teletype and "Block Mode"
https://www.garlic.com/~lynn/2025b.html#47 IBM Datacenters
https://www.garlic.com/~lynn/2024f.html#43 IBM/PC
https://www.garlic.com/~lynn/2024e.html#99 PROFS, SCRIPT, GML, Internal Network
https://www.garlic.com/~lynn/2024e.html#74 IBM San Jose
https://www.garlic.com/~lynn/2024e.html#48 PROFS
https://www.garlic.com/~lynn/2024b.html#50 IBM Token-Ring
https://www.garlic.com/~lynn/2023b.html#50 Ethernet (& CAT5)
https://www.garlic.com/~lynn/2023.html#118 Google Tells Some Employees to Share Desks After Pushing Return-to-Office Plan
https://www.garlic.com/~lynn/2023.html#74 IBM 4341
https://www.garlic.com/~lynn/2023.html#49 23Jun1969 Unbundling and Online IBM Branch Offices
https://www.garlic.com/~lynn/2023.html#18 PROFS trivia
https://www.garlic.com/~lynn/2022h.html#122 The History of Electronic Mail
https://www.garlic.com/~lynn/2022c.html#7 Cloud Timesharing
https://www.garlic.com/~lynn/2022b.html#123 System Response
https://www.garlic.com/~lynn/2022.html#94 VM/370 Interactive Response
https://www.garlic.com/~lynn/2021k.html#79 IBM Fridays
https://www.garlic.com/~lynn/2021h.html#60 PROFS
https://www.garlic.com/~lynn/2021e.html#30 Departure Email
https://www.garlic.com/~lynn/2021c.html#65 IBM Computer Literacy
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Security Date: 05 Feb, 2026 Blog: Facebookcirca 1980, IBM brought trade-secret lawsuit against disk clone maker for couple billion dollars ... for having acquired detailed unannounced new (3380) disk drive documents. Judge ruled that IBM had to show security proportional to risk ... or "security proportional to value" ... i.e. temptation for normal person finding something not adequately protected and selling it for money ... couldn't be blamed (analogous to requiring fences around swimming pools because children couldn't be expected to not jump in unprotected pool).
I had a bunch of double locked cabinet "ibm confidential registered" (in this case "811" for their Nov78 publication date) that required random audits by plant site security. I get a call from head hunter about technical assistant job to president of front company for foreign clone maker. during the interview they brought up ibm classified information and I aborted the interview. A couple yrs later, I had a couple hrs with FBI (gov. was suing foreign company for industrial espionage) because I was on the lobby check-in register. I tell the agent about sequence and suggested that maybe somebody in site security was feeding head hunter, the identifies of people that had registered documents.
some past posts
https://www.garlic.com/~lynn/2024f.html#77 IBM Registered Confidential and "811"
https://www.garlic.com/~lynn/2023.html#59 Classified Material and Security
https://www.garlic.com/~lynn/2019.html#83 The Sublime: Is it the same for IBM and Special Ops?
https://www.garlic.com/~lynn/2002d.html#8 Security Proportional to Risk (was: IBM Mainframe at home)
https://www.garlic.com/~lynn/aadsm28.htm#75 Fun with Data Theft/Breach Numbers
https://www.garlic.com/~lynn/aepay10.htm#20 Security Proportional to Risk (was: IBM Mainframe at home)
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM HSDT, Series/1 T1 Date: 06 Feb, 2026 Blog: FacebookFirst half 80s, I got HSDT project, T1 and faster computer links (both terrestrial and satellite), which included requirement being able to show some IBM content ... along with battles with the communication group (60s, IBM had 2701 controller that supported T1, transition to SNA in the 70s, with associated issues, capped controller links at 56kbits).
The only IBM T1 I could find was the FSD Series/1 T1 ZIRPEL card (FSD did for gov customers who had 2701s that were failing). I went to order a half dozen S/1s ... but was told there were year's backlog; newly acquired ROLM was a Data General shop ... but to try and show some IBM content they had made a huge S/1 order. Turns out the ROLM datacenter manager, I had known when they were at IBM ... and cut a deal to help them with some problems in return for some of their S/1s.
Then I was approached by some IBMers in branch office for a baby bell
and some from S/1 group ... to turn out as type-1 product a VTAM/NCP
emulation that baby bell had done on S/1s ... that had enormous better
feature, function, availability, performance and price/performance,
etc. Part of presentation that I gave at SNA ARB meeting (comparing
baby bell implementation with VTAM/3725)
https://www.garlic.com/~lynn/99.html#67
part of Baby Bell presentation given at IBM user group "COMMON" meeting
https://www.garlic.com/~lynn/99.html#70
The IBMers claimed to have extensive experience with communication group internal politics and made extensive effort to wall it off ... what the communication group did next to tank the effort, can only be described as fact/truth is stranger than fiction.
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Ethernet and IBM Token-Ring Date: 06 Feb, 2026 Blog: FacebookIBM AWD (workstation) got to do their own cards for the PC/RT (PC/AT bus), including 4mbit token-ring cards. Then for microchannel RS/6000, they were told they couldn't do their own cards, but have to use (heavily performance kneecapped by the communication group) microchannel cards (the PC/RT 4mbit token ring card had higher card throughput than the PS2 microchannel 16mbit token ring card; joke that a PC/RT 4mbit T/R server would have higher throughput than RS/6000 16mbit T/R server).
New Almaden research bldg was heavily provisioned with IBM wiring assuming 16mbit token-ring, but found 10mbit ethernet lan had lower latency and higher aggregate throughput than 16mbit token-ring. Also the $69 10mbit Ethernet cards had much higher throughput than the $800 16mbit token-ring PS2 microchannel cards.
Early 80s, I got HSDT project, T1 and faster computer links
(terrestrial and satellite) and lots of conflict with corporate
communication product group (note, 60s, IBM had 2701 telecommunication
controller that had T1 support, then with the 70s move to SNA/VTAM and
associated issues, capped controllers at 56kbits/sec). We were working
with NSF director and was suppose to get $20M to interconnect the NSF
Supercomputer centers. Then congress cuts the budget, some other
things happen and eventually an RFP is released (in part based on what
we already had running). NSF 28Mar1986 Preliminary Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
The communication group had also been fighting off release of mainframe TCP/IP support. When they lost, they change strategy and said that since they had corporate responsibility for everything that crosses datacenter walls, it had to be release through them. What shipped used nearly whole 3090 CPU getting aggregate 44kbytes/sec. I then add RFC1044 support and in some tuning tests at Cray Research between Cray and 4341, get aggregate sustained 4341 channel throughput using only modest amount of 4341 processor (something like 500 times improvement in bytes moved per instruction executed).
Also at the time there was lots of internal network SNA/VTAM
misinformation (including converting the internal network to SNA/VTAM)
and there was similar misinformation about being able to use SNA/VTAM
for NSFNET. Somebody was collecting internal NSFNET SNA/VTAM
misinformation email and forwarded it to us (heavily clipped &
redacted to protect the guilty)
https://www.garlic.com/~lynn/2006w.html#email870109
And 1988, IBM branch office asks if I could help LLNL (national lab) standardize some serial stuff they were working with, which quickly becomes fibre-channel standard ("FCS", initially 1gbit transfer, full-duplex, 200mbyte/sec, including some stuff I had done in 1980). Eventually POK announces serial stuff they had been working with for over a decade, "ESCON" (when it was already obsolete), initially 10mbyte/sec, later 17mbyte/sec. Then some POK engineers become involved with "FCS" and define a heavy weight protocol that radically reduces native throughput, eventually released as FICON. 2010, public released benchmark was z196 "Peak I/O" getting 2M IOPS with 104 FICONs (20K IOPS/FICON). About the same time, a FCS was announced for E5-2600 server blades that got over million IOPS (two such FCS higher throughput than 104 FICONs). Also, IBM docs advise SAP (system assist processors that does actually I/O) CPUs be kept to 70% (or 1.5M IOPS) ... as well as no CKD DASD have been made for decades, all being simulated on industry standard fixed-block devices.
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
IBM internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET Posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
RFC 1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
Recent posts mentioning Ethernet and Token-ring
https://www.garlic.com/~lynn/2025e.html#88 IBM 3270 Emulators
https://www.garlic.com/~lynn/2025e.html#40 IBM Boca and IBM/PCs
https://www.garlic.com/~lynn/2025e.html#21 IBM Token-Ring
https://www.garlic.com/~lynn/2025e.html#2 PS2 Microchannel
https://www.garlic.com/~lynn/2025d.html#81 Token-Ring
https://www.garlic.com/~lynn/2025d.html#73 Boeing, IBM, CATIA
https://www.garlic.com/~lynn/2025d.html#46 IBM OS/2 & M'soft
https://www.garlic.com/~lynn/2025d.html#8 IBM ES/9000
https://www.garlic.com/~lynn/2025d.html#2 Mainframe Networking and LANs
https://www.garlic.com/~lynn/2025c.html#114 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#88 IBM SNA
https://www.garlic.com/~lynn/2025c.html#56 IBM OS/2
https://www.garlic.com/~lynn/2025c.html#53 IBM 3270 Terminals
https://www.garlic.com/~lynn/2025c.html#41 SNA & TCP/IP
https://www.garlic.com/~lynn/2025b.html#10 IBM Token-Ring
https://www.garlic.com/~lynn/2025.html#95 IBM Token-Ring
https://www.garlic.com/~lynn/2024g.html#101 IBM Token-Ring versus Ethernet
https://www.garlic.com/~lynn/2024f.html#39 IBM 801/RISC, PC/RT, AS/400
https://www.garlic.com/~lynn/2024f.html#27 The Fall Of OS/2
https://www.garlic.com/~lynn/2024e.html#64 RS/6000, PowerPC, AS/400
https://www.garlic.com/~lynn/2024e.html#52 IBM Token-Ring, Ethernet, FCS
https://www.garlic.com/~lynn/2024d.html#7 TCP/IP Protocol
https://www.garlic.com/~lynn/2024c.html#69 IBM Token-Ring
https://www.garlic.com/~lynn/2024c.html#56 Token-Ring Again
https://www.garlic.com/~lynn/2024c.html#47 IBM Mainframe LAN Support
https://www.garlic.com/~lynn/2024b.html#50 IBM Token-Ring
https://www.garlic.com/~lynn/2024b.html#41 Vintage Mainframe
https://www.garlic.com/~lynn/2024b.html#22 HA/CMP
https://www.garlic.com/~lynn/2024.html#117 IBM Downfall
https://www.garlic.com/~lynn/2024.html#41 RS/6000 Mainframe
https://www.garlic.com/~lynn/2024.html#5 How IBM Stumbled onto RISC
https://www.garlic.com/~lynn/2023g.html#76 Another IBM Downturn
https://www.garlic.com/~lynn/2023c.html#91 TCP/IP, Internet, Ethernett, 3Tier
https://www.garlic.com/~lynn/2023c.html#49 Conflicts with IBM Communication Group
https://www.garlic.com/~lynn/2023c.html#6 IBM Downfall
https://www.garlic.com/~lynn/2023b.html#83 IBM's Near Demise
https://www.garlic.com/~lynn/2023b.html#50 Ethernet (& CAT5)
https://www.garlic.com/~lynn/2023b.html#34 Online Terminals
https://www.garlic.com/~lynn/2023.html#77 IBM/PC and Microchannel
https://www.garlic.com/~lynn/2022h.html#57 Christmas 1989
https://www.garlic.com/~lynn/2022f.html#18 Strange chip: Teardown of a vintage IBM token ring controller
https://www.garlic.com/~lynn/2022f.html#4 What is IBM SNA?
https://www.garlic.com/~lynn/2022e.html#24 IBM "nine-net"
https://www.garlic.com/~lynn/2022b.html#84 David Boggs, Co-Inventor of Ethernet, Dies at 71
https://www.garlic.com/~lynn/2021j.html#50 IBM Downturn
https://www.garlic.com/~lynn/2021i.html#69 IBM MYTE
https://www.garlic.com/~lynn/2021g.html#42 IBM Token-Ring
https://www.garlic.com/~lynn/2021d.html#15 The Rise of the Internet
https://www.garlic.com/~lynn/2021c.html#87 IBM SNA/VTAM (& HSDT)
https://www.garlic.com/~lynn/2021b.html#45 Holy wars of the past - how did they turn out?
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Ethernet and IBM Token-Ring Date: 06 Feb, 2026 Blog: Facebookre:
Second half of 80s, I was also on Chessin's XTP TAB. TCP had minimum 7 packet exchange and XTP defined a reliable transaction with minimum of 3 packet exchange. Issue was that TCP/IP was part of kernel distribution requiring physical media (and typically some expertise for complete system change/upgrade, browsers and webservers were self contained load&go). XTP also defined things like trailer protocol where interface hardware could do CRC as packet flowing through and do the append/check ... helping minimize packet fiddling (as well as other pieces of protocol offloading, Chessin also liked to draw analogies with SGI graphic card process pipelining). Problem was that there were lots of push back for anything that required kernel changes.
In part because there were gov. military members, we took XTP to ISO/ANSI X3S3.3 as HSP and initially got acceptance. Then were told ISO required that standards work could only be for things that conformed to OSI Model. XTP didn't because 1) supported internetworkiing layer, didn't exist in OSI, 2) skipped transport/network interface and went directly to LAN, 3) went directly to LAN, which didn't exist in OSI. Joke that while (internet) IETF required two interoperable implementations before proceed in standard, ISO didn't even require a standard be implementable.
also OSI: The Internet That Wasn't. How TCP/IP eclipsed the Open
Systems Interconnection standards to become the global protocol for
computer networking
https://spectrum.ieee.org/osi-the-internet-that-wasnt
Meanwhile, IBM representatives, led by the company's capable director
of standards, Joseph De Blasi, masterfully steered the discussion,
keeping OSI's development in line with IBM's own business
interests. Computer scientist John Day, who designed protocols for the
ARPANET, was a key member of the U.S. delegation. In his 2008 book
Patterns in Network Architecture(Prentice Hall), Day recalled that IBM
representatives expertly intervened in disputes between delegates
"fighting over who would get a piece of the pie.... IBM played them
like a violin. It was truly magical to watch."
... snip ...
XTP/HSP posts
https://www.garlic.com/~lynn/subnetwork.html#xtphsp
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: PROFS, VMSG, 3270 Date: 07 Feb, 2026 Blog: FacebookMIT CTSS/7094 had email. Then some of the CTSS/7094 went to the 5th flr for MULTICS. Others went to the IBM Cambridge Science Center on the 4th flr and did virtual machines (1st wanted a 360/50 to add hardware virtual memory but all the extra 50s were going to FAA/ATC and had to settle for 360/40 to add virtual memory and did CP40/CMS, then when 360/67 became available standard with virtual memory, CP40/CMS morphs into CP67/CMS ... precursor to VM370/CMS), CP67-based wide-area network (morphs into IBM internal network, larger than arpanet/internet from beginning until sometime mid/late 80s about time internal network was forced to convert to SNA/VTAM; technology also used for corporate sponsored univ. BITNET). GML was invented in 1969, also one of the people that would invent GML (morphs into SGML & HTML):
Actually, the law office application was the original motivation for the project, something I was allowed to do part-time because of my knowledge of the user requirements. My real job was to encourage the staffs of the various scientific centers to make use of the CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
CTSS/7094 RUNOFF had been redone for CMS as SCRIPT, later after GML
was invented, GML tag processing support added to SCRIPT
https://en.wikipedia.org/wiki/TYPSET_and_RUNOFF
Numerous email clients were done (for CP67 & VM370) during the 70s. Then the PROFS group was collecting internal apps to wrap 3270 menus around and acquired very early version of VMSG for the email client. When the VMSG author tried to offer a much enhanced VMSG source to the PROFS group, they tried to have him separated from the company. The whole thing quieted down when the VMSG author demonstrated his initials in non-displayed field in every PROFS email. After that, the VMSG author only shared his source with me and one other person.
Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
BITNET (& EARN) posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
some recent posts mentioning profs, vmsg, 3270
https://www.garlic.com/~lynn/2026.html#19 IBM Online Apps, Network, Email
https://www.garlic.com/~lynn/2026.html#5 PROFS and other CMS applications
https://www.garlic.com/~lynn/2025d.html#109 Internal Network, Profs and VMSG
https://www.garlic.com/~lynn/2025d.html#43 IBM OS/2 & M'soft
https://www.garlic.com/~lynn/2025d.html#32 IBM Internal Apps, Retain, HONE, CCDN, ITPS, Network
https://www.garlic.com/~lynn/2025c.html#113 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025b.html#60 IBM Retain and other online
https://www.garlic.com/~lynn/2025.html#90 Online Social Media
https://www.garlic.com/~lynn/2024f.html#44 PROFS & VMSG
https://www.garlic.com/~lynn/2024e.html#99 PROFS, SCRIPT, GML, Internal Network
https://www.garlic.com/~lynn/2024e.html#48 PROFS
https://www.garlic.com/~lynn/2024e.html#27 VMNETMAP
https://www.garlic.com/~lynn/2024b.html#109 IBM->SMTP/822 conversion
https://www.garlic.com/~lynn/2024b.html#69 3270s For Management
https://www.garlic.com/~lynn/2023g.html#49 REXX (DUMRX, 3092, VMSG, Parasite/Story)
https://www.garlic.com/~lynn/2023f.html#71 Vintage Mainframe PROFS
https://www.garlic.com/~lynn/2023f.html#46 Vintage IBM Mainframes & Minicomputers
https://www.garlic.com/~lynn/2023c.html#78 IBM TLA
https://www.garlic.com/~lynn/2023c.html#42 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2023c.html#32 30 years ago, one decision altered the course of our connected world
https://www.garlic.com/~lynn/2023c.html#5 IBM Downfall
https://www.garlic.com/~lynn/2023.html#97 Online Computer Conferencing
https://www.garlic.com/~lynn/2023.html#62 IBM (FE) Retain
https://www.garlic.com/~lynn/2023.html#18 PROFS trivia
https://www.garlic.com/~lynn/2022b.html#2 Dataprocessing Career
https://www.garlic.com/~lynn/2021j.html#83 Happy 50th Birthday, EMAIL!
https://www.garlic.com/~lynn/2021i.html#68 IBM ITPS
https://www.garlic.com/~lynn/2021h.html#33 IBM/PC 12Aug1981
https://www.garlic.com/~lynn/2021e.html#30 Departure Email
https://www.garlic.com/~lynn/2021d.html#48 Cloud Computing
https://www.garlic.com/~lynn/2021c.html#65 IBM Computer Literacy
https://www.garlic.com/~lynn/2021b.html#37 HA/CMP Marketing
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Loosely-coupled and Hot Standby Date: 07 Feb, 2026 Blog: FacebookMy wife was in Gburg JES group and one of the catchers for ASP/JES3. Then she was con'ed into going to POK responsible for loosely-coupled architecture, where she did peer-coupled shared data architecture. She didn't remain long, 1) lots of battles with the communication group trying to force her into using SNA/VTAM for loosely-coupled operation, 2) little uptake (until much later with SYSPLEX and Parallel SYSPLEX), except IMS hot-standby. She has story asking Vern Watts who he asks permission for to do hot-standby; he replies, nobody, will just tell them when its all done.
1988, Nick Donofrio approved HA/6000, originally for NYTimes to move
their newspaper system (ATEX) off DEC VAXCluster to RS/6000. I rename
it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LLNL, LANL, NCAR, etc) and commercial cluster scale-up with
RDBMS vendors (Oracle, Sybase, Ingres, Informix that had VAXcluster
support in same source base with Unix; I do distributed lock
manager with VAXCluster semantics to ease ports). Then the S/88
product administrator (relogo'ed Stratus) starts taking us around to
their customers and gets me to write a section for the
corporate continuous availability strategy document (it gets
pulled when both Rochester/as400 and POK/mainframe, complain they
can't meet the objectives). Had coined disaster survivability
and geographic survivability (as counter to disaster/recovery)
when out marketing HA/CMP. One of the visits to 1-800 bellcore
development showed that S/88 would use a century of downtime in one
software upgrade, while HA/CMP had a couple extra "nines" (compared to
S/88). Work is also underway to port LLNL supercomputer filesystem
(LINCS) to HA/CMP and working with NCAR spinoff (Mesa Archive) to
platform on HA/CMP.
Early Jan92, there was meeting with Oracle CEO and IBM/AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid-jan92, I update FSD on HA/CMP
work with national labs and FSD decides to go with HA/CMP for federal
supercomputers. By end of Jan, we are told that cluster scale-up is
being transferred to Kingston for announce as IBM Supercomputer
(technical/scientific *ONLY*) and we aren't allowed to work with
anything that has more than four systems (we leave IBM a few months
later). A couple weeks later, 17feb1992, Computerworld news ... IBM
establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 benchmarks (number of program iterations
compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, 51MIPS/CPU
RS6000/990 : (1-CPU) 126MIPS, 16-systems: 2BIPS, 128-systems: 16BIPS
Mid-90s (after having left IBM), the guy at NYFED that ran FEDWIRE,
liked us to drop in and talk technology. FEDWire had triple redundant
hot-standby IMS system, two in same datacenter and 3rd at remote
location (credited with 100% availability for over a decade).
Peer-coupled, shared data architecture posts
https://www.garlic.com/~lynn/submain.html#shareddata
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
There was VTAM/NCP implementation on distributed Series/1s which could
support "shadow sessions" that were setup and immediately available
for fall-over. Same past refs:
https://www.garlic.com/~lynn/2025.html#97 IBM Token-Ring
https://www.garlic.com/~lynn/2024c.html#53 IBM 3705 & 3725
https://www.garlic.com/~lynn/2023b.html#62 Ethernet (& CAT5)
https://www.garlic.com/~lynn/2022c.html#79 Peer-Coupled Shared Data
https://www.garlic.com/~lynn/2021k.html#115 Peer-Coupled Shared Data Architecture
https://www.garlic.com/~lynn/2021b.html#72 IMS Stories
https://www.garlic.com/~lynn/2019d.html#114 IBM HONE
https://www.garlic.com/~lynn/2018e.html#94 It's 1983: What computer would you buy?
https://www.garlic.com/~lynn/2017.html#98 360 & Series/1
https://www.garlic.com/~lynn/2014e.html#7 Last Gasp for Hard Disk Drives
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Loosely-coupled and Hot Standby Date: 08 Feb, 2026 Blog: Facebookre:
Executive we reported to goes over to head up Somerset/AIM (Apple,
IBM, Motorola) to do single chip Power/PC including using Motorola 88K
bus/cache enabling multiprocessor/core. 1999 Industry benchmark
(number of program iterations compared to the industry MIPS/BIPS
reference platform):
IBM PowerPC 440: 1,000MIPS
2000 industry benchmark:
z900, 16 processors 2.5BIPS (156MIPS/core), Dec2000
Also 1988, IBM branch office asks if I could help LLNL (national lab)
standardize some serial stuff they were working with, which quickly
becomes fibre-channel standard ("FCS", including some stuff I had done
in 1980, initial 1gbit transfer, full-duplex, aggregate 200mbyte/sec),
planning on using for HA/CMP. Then POK gets their stuff released as
ESCON (when it was already obsolete), initially 10mbytes/sec, upgraded
to 17mbytes/sec.
Later some POK engineers become involved with "FCS" and define a protocol that significantly reduces "FCS" throughput, eventually released as FICON. 2010 pulbic released benchmark was z196 "Peak I/O" getting 2M IOPS with 104 FICONs (20K IOPS/FICON). About the same time, a FCS was announced for E5-2600 server blades that got over million IOPS (two such FCS higher throughput than 104 FICONs). Also, IBM docs advise SAP (system assist processors that does actually I/O) CPUs be kept to 70% (or 1.5M IOPS) ... as well as no CKD DASD have been made for decades, all being simulated on industry standard fixed-block devices.
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: UofM MTS and IBM CP67 Date: 08 Feb, 2026 Blog: FacebookI had taken two credit hour intro to fortran/computers. At the end of semester, I was hired to rewrite 1401 MPIO in assembler for 360/30. The univ was getting 360/67 for tss/360 replacing 709/1401 (360/30 temporarily replaced 1401 pending arrival of 360/67). The univ. shutdown datacenter on weekends and I would have the place dedicated (although 48hrs w/o sleep made monday classes hard). I was given pile of hardware&software manuals and got to design & implement monitor, device drivers, interrupt handlers, error recovery, storage management, etc. and within a few weeks had 2000 card assembler program.
Within a year of taking intro class, the 360/67 arrives and I was hired fulltime responsible for OS/360 (tss/360 never came to production). The 709 ran student fortran jobs in under second, but initially with os/360, they ran over a minute. I install HASP which cuts the time in half. I then start redoing SYSGEN STAGE2, to carefully place datasets and PDS members to optimize disk arm seek and multi-track search ... cutting another 2/3rds to 12.9secs; it never got better than 709 until I install UofWaterloo WATFOR.
Then CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initiall 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 had arrived with 1052&2741 terminal support including automagic
terminal type (changing terminal type port scanner). Univ. had a bunch
of ASCII/TTY terminals and I add ASCII terminal support to CP/67
integrated with automagic terminal type. I then want to have a single
dial-in number for all terminals ("hunt group"). Didn't quite work,
while IBM controller could change terminal type port scanner, they had
hard wire port speed. This kicks off univ program, build a channel
interface board for Interdata/3 programmed to emulate IBM controller
(but with automatic line speed). It was later upgraded to Interdata/4
for channel interface and cluster of Interdata/3s for ports. Interdata
and later Perkin/Elmer sells as clone IBM controller and four of us
get written up for some part of IBM controller clone business.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
note Univ. of Michigan had done a terminal controller, "data
concentrator" for MTS
https://www.eecis.udel.edu/~mills/gallery/gallery7.html
more MTS, mentions data concentrator
https://www.eecis.udel.edu/~mills/gallery/gallery8.html
MIT Lincoln Labs' LLMPS was somewhat like a more sophisticated version
of IBM DEBE and Michigan had started out scaffolding MTS off LLMPS.
https://web.archive.org/web/20200926144628/michigan-terminal-system.org/discussions/anecdotes-comments-observations/8-1someinformationaboutllmps
IBM Cambridge Scientific Center
https://www.garlic.com/~lynn/subtopic.html#545tech
Posts mention MTS, data concentrator, and LLMPS
https://www.garlic.com/~lynn/2025.html#64 old pharts, Multics vs Unix
https://www.garlic.com/~lynn/2024f.html#32 IBM 370 Virtual memory
https://www.garlic.com/~lynn/2023.html#46 MTS & IBM 360/67
https://www.garlic.com/~lynn/2021j.html#68 MTS, 360/67, FS, Internet, SNA
https://www.garlic.com/~lynn/2021h.html#65 CSC, Virtual Machines, Internet
https://www.garlic.com/~lynn/2021e.html#43 Blank 80-column punch cards up for grabs
https://www.garlic.com/~lynn/2016c.html#6 You count as an old-timer if (was Re: Origin of the phrase "XYZZY")
https://www.garlic.com/~lynn/2006m.html#42 Why Didn't The Cent Sign or the Exclamation Mark Print?
https://www.garlic.com/~lynn/2006k.html#41 PDP-1
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Internal Network Date: 08 Feb, 2026 Blog: Facebookre:
Tymshare (commercial online VM370/CMS services)
https://en.wikipedia.org/wiki/Tymshare
https://spectrum.ieee.org/someone-elses-computer-the-prehistory-of-cloud-computing
in Aug1976, Tymshare started offering their CMS-based online computer
conferencing for free to the IBM mainframe SHARE user group
https://www.share.org/
as VMSHARE, archived here
http://vm.marist.edu/~vmshare
I cut a deal with Tymshare to get monthly tape dump of all VMSHARE files for putting up on internal network and internal systems (including HONE). Initially lawyers objected, they were concerned about exposing internal employees with unfiltered customer information (that was possibly different from corporate party line). This is similar to a 1974 CERN comparison of VM370/CMS with MVS/TSO that was presented at SHARE (copies inside IBM were stamped "IBM Confidential - Restricted")
I was influenced by VMSHARE and was blamed for online computer
conferencing on the IBM internal network in late 70s and early 80s. It
really took off spring of 1981 when I distributed a trip report to see
Jim Gray at Tandem. Only about 300 directly participated but claims
that 25,000 were reading. From IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
--- six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore was 5of6 corporate
executive committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the company is
rapidly heading for disaster. Furthermore, people fear that this
movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their management
and with the way things are going in IBM. To an increasing extent,
people are reacting to this by leaving IBM. Most of the contributors
to the present discussion would prefer to stay with IBM and see the
problems rectified. However, there is increasing skepticism that
correction is possible or likely, given the apparent lack of
commitment by management to take action
• There is a widespread perception that IBM management has failed to
understand how to manage technical people and high-technology
development in an extremely competitive environment
... snip ...
There were task forces to look at online computer conferencing resulting in official IBM forum software and approved, moderated forum discussions. Also a researcher was paid to study how I communicated; sat in the back of my office for nine months taking notes on how I communicated, also got copies of all my incoming and outgoing email and logs of all instant messages. The result was used for IBM research reports, conference talks and papers, books and Stanford Phd (joint with language and computer AI, Winograd was advisor on computer AI side).
IBM internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: UofM MTS and IBM CP67 Date: 09 Feb, 2026 Blog: Facebookre:
trivia: before I graduate, I was hired into a small group in the Boeing CFO office to help with the formation of Boeing Computer Services (consolidate all data processing into an independent business unit). I think Renton datacenter the largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in the hallways around the machine room. Lots of politics between the Renton director and CFO, who only had a 360/30 up at Boeing field for payroll (although they enlarge the room to install a 360/67 for me to play with when I wasn't doing other stuff). When I graduate, I join the IBM Cambridge Science Center, instead of staying with the CFO.
Early last decade I was asked if I could track down decision to add virtual memory to all 370s and found staff member to executive making the decision. Basically MVT storage management was so bad, that regions had to be specified four times larger than used, as result, typical 1mbyte, 370/165 only ran four concurrent regions, insufficient to keep system busy and justified. Going to MVT in 16mbyte virtual address space (similar to running MVT in a CP67 16mbyte virtual machine) allowed the number of concurrent regions to be increased by factor of four times (capped at 15 because of 4bit storage protect keys) with little or no paging. I would stop by Ludlow doing VS2/SVS initially on 360/67, a little bit of code to make virtual memory tables and simple paging support. Biggest effort was EXCP/SVC0 would then be passed channel programs with virtual addresses (and channels required real addresses). EXCP needed to make a channel program copy, replacing virtual addresses with real (similar to what CP67 had to do for virtual machines) and Ludlow borrows CP67 CCWTRANS for crafting into EXCP.
While I was at Boeing, Boeing Huntsville 2-CPU 360/67 was brought up to Seattle. Huntsville had originally got 360/67 with several 2250s for CAD/CAM (for TSS/360 similar to Univ), but configured as two 360/65s running OS/360. MVT was introduced with R13 and Huntsville ran into MVT storage management problem (later used as justification to add virtual memory to all 370s). They modified MVT to run in 360/67 virtual address space mode (but w/o paging) as partial countermeasure to the MVT problems.
virtual machine timsharing posts
https://www.garlic.com/~lynn/submain.html#timeshare
some posts mentioning Boeing CFO, BCS, Renton, Huntsville, MVT13
https://www.garlic.com/~lynn/2025e.html#104 Early Mainframe Work
https://www.garlic.com/~lynn/2025e.html#76 Boeing Computer Services
https://www.garlic.com/~lynn/2025e.html#74 IBM 370 Virtual Memory
https://www.garlic.com/~lynn/2025d.html#101 Stanford WYLBUR, ORVYL, MILTON
https://www.garlic.com/~lynn/2025d.html#99 IBM Fortran
https://www.garlic.com/~lynn/2025d.html#95 IBM VM370 And Pascal
https://www.garlic.com/~lynn/2025b.html#117 SHARE, MVT, MVS, TSO
https://www.garlic.com/~lynn/2025.html#15 Dataprocessing Innovation
https://www.garlic.com/~lynn/2024g.html#106 IBM 370 Virtual Storage
https://www.garlic.com/~lynn/2024f.html#20 IBM 360/30, 360/65, 360/67 Work
https://www.garlic.com/~lynn/2024e.html#136 HASP, JES2, NJE, VNET/RSCS
https://www.garlic.com/~lynn/2024e.html#24 Public Facebook Mainframe Group
https://www.garlic.com/~lynn/2024d.html#63 360/65, 360/67, 360/75 750ns memory
https://www.garlic.com/~lynn/2024d.html#40 ancient OS history, ARM is sort of channeling the IBM 360
https://www.garlic.com/~lynn/2024b.html#49 Vintage 2250
https://www.garlic.com/~lynn/2024.html#87 IBM 360
https://www.garlic.com/~lynn/2024.html#17 IBM Embraces Virtual Memory -- Finally
https://www.garlic.com/~lynn/2023g.html#39 Vintage Mainframe
https://www.garlic.com/~lynn/2023g.html#19 OS/360 Bloat
https://www.garlic.com/~lynn/2023g.html#5 Vintage Future System
https://www.garlic.com/~lynn/2023g.html#4 Vintage Future System
https://www.garlic.com/~lynn/2023f.html#110 CSC, HONE, 23Jun69 Unbundling, Future System
https://www.garlic.com/~lynn/2023e.html#34 IBM 360/67
https://www.garlic.com/~lynn/2022h.html#4 IBM CAD
https://www.garlic.com/~lynn/2022e.html#42 WATFOR and CICS were both addressing some of the same OS/360 problems
https://www.garlic.com/~lynn/2022.html#73 MVT storage management issues
https://www.garlic.com/~lynn/2021c.html#2 Colours on screen (mainframe history question)
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Online Timesharing Date: 09 Feb, 2026 Blog: Facebookrecent post about early (CSC CP67/CMS) days
one of my hobbies after joining IBM was enhanced production operating systems for internal datacenters (originally 2741 and tty terminals). Then IBM had 3272/3277 (had .086 hardware response). Then circa 1980, IBM came out with 3274/3728 ... moved a lot of terminal hardware back into shared 3274 controller (lowered manufacturing cost) ... significantly driving up coax protocol ... making hardware response (protocol elapsed) time .3-.5secs (dependent on amount of data). Complaining letters to the 3278 product administrator got replies that 3278 wasn't intended for interactive computing ... but data entry (i.e. keypunch data). About the same time were reports that quarter second response improved productivity. My internal systems about same time were avg. .11sec interactive system response (i.e. .11+.086= .196sec seen by human).
Later IBM/PC 3277 terminal emulation card would have 4-5 times the throughput of 3278 terminal emulation card.
Also 1980, IBM STL (since renamed silicon valley lab) was bursting at seams and 300 people (& terminals) from the IMS group were being moved to offsite bldg with dataprocessing back to STL datacenter. They had tried "remote 3270" but found the human factors were totally unacceptable. I get con'ed into doing channel-extender support so that direct channel attach 3270 controllers can be placed at the offsite bldg and there no perceived human factors difference between inside STL and offsite. From law of unattended consequences; STL had been spreading 3270 channel-attached controllers across all the system channels with 3330 DASD. Moving the 3270 controllers offsite (with channel-extenders) increased system throughput by 10-15% ... turns out 3270 channel-attached controllers had relatively high channel busy ... interfering with DASD throughput .... the channel-extender hardware significantly masked/reduced the channel busy time, reducing interference with DASD I/O. There was then consideration to even place 3270 controllers inside STL behind channel-extenders.
trivia: 1988, branch office asks if I could help LLNL (national lab) standardize some serial stuff they were working with which quickly becomes fibre-channel standard ("FCS", including some stuff I had done in 1980, initially 1gbit transfer, full-duplex, aggregate 200mbyte/sec). Then IBM mainframe release some serial (when it was already obsolete) as ESCON, initially 10mbyte/sec, upgrading to 17mbyte/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight protocol that drastically cuts native throughput, eventually ships as FICON. Around 2010 was a max configured z196 public "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON, running over FCS). Note IBM docs has SAPs (system assist processors that do actual I/O), CPU be kept to 70% ... or 1.5M IOPS ... also no CKD DASD have been made for decades (just simulated on industry fixed-block devices).
other trivia: some of the MIT CTSS/7094 people went to the 5th flr to do Multics, others went to the IBM Cambridge Scientific Center on the 4th flr and did virtual machines (wanted 360/50 to add virtual memory, but all extra 50s were going to FAA/ATC and they had to settle for 360/40 and did CP40/CMS which morphs into CP67/CMS when 360/67 standard with virtual memory becomes available), CP67-based science center wide-area network (which morphs into the IBM internal corporate network larger than arpanet/internet from the beginning until sometime mid/late 80s, about the time it was forced to convert to SNA/VTAM, technology also used for the corporate sponsored univ BITNET), invented GML in 1969 (which later morphs into SGML and HTML) ... various online apps.
After graduating and joining science center I found there was some friendly rivalry between 5th & 4th flrs (and one of my hobbies was enhanced production operating systems for internal datacenters). It wasn't fair to compare the total number MULTICS installations with the total number of VM370 installations or even the total number of internal IBM VM370 installations ... but I found that at one point, I had more internal IBM VM370 installation than all MULTICS installations in existence.
IBM Cambridge Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
commercial, online timesharing posts
https://www.garlic.com/~lynn/submain.html#timeshare
channel-extender posts
https://www.garlic.com/~lynn/submisc.html#channel.extender
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
enhanced production operating systems, CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Online Timesharing Date: 10 Feb, 2026 Blog: Facebookre:
MFT, MVT, SVS, VS1, MVS all had multi-track search orientation that interfered horribly with interactive computing. I 1st ran into it as undergraduate in the 60s hired fulltime responsible for OS/360 at the Univ. Univ was getting 360/67 supposedly for TSS/360, replacing 709/1401 ... however, TSS/360 didn't come to production and ran as 360/65 initially with OS/360. 709 (tape->tape) ran student fortran jobs in under a second ... but initially well over a minute with os/360. I install HASP and it cut the time in half. Then I start redoing SYSGEN STAGE2 to carefully place datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9secs. Student Fortran never got better than 709 until I install UofWaterloo WATFOR. WATFOR was clocked at 20,000 cards/minute on (360/67 running as) 360/65 (333cards/sec, student fortran jobs ran 30-60 cards/job).
End of following decade, I was at San Jose Research and they replace a MVT 370/195 with a MVS 370/168 and a VM370/CMS 370/158 ... there were two 3830 and two 3330 strings, both having two channel interface, one with dedicated for MVS and one dedicate for VM370 and hard & fast rule that no MVS 3330s could be mounted on dedicated VM370 string. One morning, operations mount a MVS 3330 on the VM370 string and within 5mins, operations were getting phone calls from CMS users all over the bldg complaining about CMS response. MVS was doing full-cylinder multi-track PDS member search on the VM370 string mounted MVS pack; locking up VM370 3830 controller (and access to all the VM370 3330s and the same string) ... 3330 19tracks/cylinder, 60revs/sec. basically VM370 I/O lockup for .317/sec per multi-track search (pushing CMS interactive response to well over second). Operations response to demands to move the MVS pack was they would do it 2nd shift. We then bring a one pack VS1 3330 on MVS string, highly optimized for running VM370, including handshaking. The VM370 optimized VS1 on loaded 370/158 was easily much faster than MVS on dedicated 370/168 and brought MVS to its knees and operations then agreed to immediately move the MVS pack. Observation that multi-track search paradigm so egregiously impacts MVS interactive response ...
A year or two later got a call from branch office to come look at customer MVS performance issues; a multi-168, loosely-coupled MVS operations for one of the largest national grocery companies. All the standard IBM MVS performance experts had been through and didn't find anything. I was brought into a large classroom with tables covered system activity reports for all 168s. After 30mins, I noticed that the aggregate I/Os across all 168s peaked at 6-to-7/sec for a specific drive. It turns out it was shared DASD with store controller applications PDS for all stores. Basically configuration at peak load was capable of loading two applications/sec for all stores in the US. The PDS dataset had three cylinder directory ... member search avg. cylinder and half ... or two multi-track I/Os, .317sec for full cyl, and .159sec for half cyl. ... .476sec total ... plus the I/Os to load the member (stand-alone seek plus read) ... throttles at two store controller applications loads per second across all stores in the US. So partition the store controller PDS dataset and replicate dedicated sets dedicated for each 168.
MVS trivia: when I 1st transferred to SJR, I got to wander around silicon valley datacenters, including disk bldg14/engineering and bldg15/product test, across the street. There were doing prescheduled, 7x24, stand-alone mainframe testing. They mentioned that they had recently tried MVS, but it had 15min MTBF (requiring manual re-ipl) in that environment. I offer to rewrite I/O supervisor to make it bullet proof and never fail, allowing any amount of on-demand concurrent testing, greatly improving productivity. Then bldg15 gets 1st engineeering 3033 outside POK 3033 processor engineering. Testing only took a percent or two of the CPU so we scrounge up a 3830 and 3330 string so we could have our own private online service. I then do a internal I/O Integrity Research Report and happen to mention the MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
posts mentioning getting to play disk engineer
https://www.garlic.com/~lynn/subtopic.html#disk
some posts mentioning SJR, 195, 168, 158, MVS, VM370, VS1
https://www.garlic.com/~lynn/2025e.html#75 Interactive response
https://www.garlic.com/~lynn/2025b.html#47 IBM Datacenters
https://www.garlic.com/~lynn/2024.html#75 Slow MVS/TSO
https://www.garlic.com/~lynn/2022c.html#101 IBM 4300, VS1, VM370
https://www.garlic.com/~lynn/2021k.html#131 Multitrack Search Performance
https://www.garlic.com/~lynn/2011.html#36 CKD DASD
some posts mentioning national grocery, store controller, multi-track
https://www.garlic.com/~lynn/2025d.html#105 Rapid Response
https://www.garlic.com/~lynn/2024g.html#65 Where did CKD disks come from?
https://www.garlic.com/~lynn/2024g.html#29 Computer System Performance Work
https://www.garlic.com/~lynn/2024d.html#54 Architectural implications of locate mode I/O
https://www.garlic.com/~lynn/2023g.html#60 PDS Directory Multi-track Search
https://www.garlic.com/~lynn/2023e.html#7 HASP, JES, MVT, 370 Virtual Memory, VS2
https://www.garlic.com/~lynn/2023c.html#96 Fortran
https://www.garlic.com/~lynn/2022f.html#85 IBM CKD DASD
https://www.garlic.com/~lynn/2021k.html#108 IBM Disks
https://www.garlic.com/~lynn/2021j.html#105 IBM CKD DASD and multi-track search
https://www.garlic.com/~lynn/2019b.html#15 Tandem Memo
https://www.garlic.com/~lynn/2025d.html#105 Rapid Response
https://www.garlic.com/~lynn/2024g.html#65 Where did CKD disks come from?
https://www.garlic.com/~lynn/2024g.html#29 Computer System Performance Work
https://www.garlic.com/~lynn/2024d.html#54 Architectural implications of locate mode I/O
https://www.garlic.com/~lynn/2023g.html#60 PDS Directory Multi-track Search
https://www.garlic.com/~lynn/2023e.html#7 HASP, JES, MVT, 370 Virtual Memory, VS2
https://www.garlic.com/~lynn/2023c.html#96 Fortran
https://www.garlic.com/~lynn/2022f.html#85 IBM CKD DASD
https://www.garlic.com/~lynn/2021k.html#108 IBM Disks
https://www.garlic.com/~lynn/2021j.html#105 IBM CKD DASD and multi-track search
https://www.garlic.com/~lynn/2019b.html#15 Tandem Memo
some recent posts mentioning sysgen, multi-track pds directory
https://www.garlic.com/~lynn/2025d.html#70 OS/360 Console Output
https://www.garlic.com/~lynn/2025c.html#3 Interactive Response
https://www.garlic.com/~lynn/2024g.html#29 Computer System Performance Work
https://www.garlic.com/~lynn/2024f.html#29 IBM 370 Virtual memory
https://www.garlic.com/~lynn/2024d.html#34 ancient OS history, ARM is sort of channeling the IBM 360
https://www.garlic.com/~lynn/2023g.html#60 PDS Directory Multi-track Search
https://www.garlic.com/~lynn/2023f.html#90 Vintage IBM HASP
https://www.garlic.com/~lynn/2023f.html#34 Vintage IBM Mainframes & Minicomputers
https://www.garlic.com/~lynn/2023e.html#34 IBM 360/67
https://www.garlic.com/~lynn/2023e.html#7 HASP, JES, MVT, 370 Virtual Memory, VS2
https://www.garlic.com/~lynn/2023d.html#101 Operating System/360
https://www.garlic.com/~lynn/2023d.html#88 545tech sq, 3rd, 4th, & 5th flrs
https://www.garlic.com/~lynn/2023d.html#79 IBM System/360 JCL
https://www.garlic.com/~lynn/2023d.html#72 Some Virtual Machine History
https://www.garlic.com/~lynn/2023d.html#14 Rent/Leased IBM 360
https://www.garlic.com/~lynn/2023c.html#96 Fortran
https://www.garlic.com/~lynn/2023c.html#82 Dataprocessing Career
https://www.garlic.com/~lynn/2023c.html#67 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2023c.html#62 Conflicts with IBM Communication Group
https://www.garlic.com/~lynn/2023c.html#46 IBM DASD
https://www.garlic.com/~lynn/2023b.html#91 360 Announce Stories
https://www.garlic.com/~lynn/2023b.html#26 DISK Performance and Reliability
https://www.garlic.com/~lynn/2023.html#65 7090/7044 Direct Couple
https://www.garlic.com/~lynn/2023.html#33 IBM Punch Cards
https://www.garlic.com/~lynn/2023.html#22 IBM Punch Cards
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Future System, Multiprocessor Date: 10 Feb, 2026 Blog: FacebookThe original 2-CPU 3081D single CPU benchmark was less than 3033 and the 3081D aggregate 2-CPU MIPS was less than Amdahl single CPU. IBM doubled the processor cache sizes for the 3081K, bringing aggregate MIPS up to about the same as Amdahl single CPU. Howevr, IBM docs had MVS 2-CPU throughput as only 1.2-1.5 times throughput of 1-CPU (inefficient multiprocessor overhead) making MVS 3081K only about .6-.75 throughput (even with approx. same aggregate MIPS) as MVS Amdahl 1-CPU.
First half of 1970s, IBM had the "Future System" effort, totally
different than 370 and completely replace 370 (internal politics was
killing off 370 efforts, lack of new 370 during the period is credited
with giving clone 370 makers their market foothold)
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
Memo125 specifically points out that 3081 is warmed over FS technology
and involved significantly greater circuits (some ref to enough to
make 16 168s with significantly greater performance) ... contributing
to the need for TCMs to package the circuits in reasonable size
physical volume ... comment that IBM had to significantly reduce the
price in order to make 3081 competitive with clone 370 makers ... aka
The 370 emulator minus the FS microcode was eventually sold in 1980 as
as the IBM 3081. The ratio of the amount of circuitry in the 3081 to
its performance was significantly worse than other IBM systems of the
time; its price/performance ratio wasn't quite so bad because IBM had
to cut the price to be competitive. The major competition at the time
was from Amdahl Systems -- a company founded by Gene Amdahl, who left
IBM shortly before the FS project began, when his plans for the
Advanced Computer System (ACS) were killed. The Amdahl machine was
indeed superior to the 3081 in price/performance and spectaculary
superior in terms of performance compared to the amount of circuitry.]
... snip ...
3081 originally was going to be multiprocessor only ... but Airline ACP/TPF didn't have multiprocessor support ... and IBM was concerned that the whole ACP/TPF market would go Amdahl ... including Amdahl single processor was faster than the initial 2-CPU 3081D. Initially they make a lot of tweaks to VM370 for running ACP/TPF on 3081 in a single CPU virtual machine ... however that degrades the throughput for every other IBM VM370 multiprocessor customer (I was brought into a number of large, major customers to come up with compensating features that could mask the ACP/TPF tweaks)
Eventually IBM removes one of the 3081 CPUs for the 3083 (trivia: simplest would have been removing 2nd CPU which was in the middle of the box, and concern that it would make the box top heavy and prone to tip over, so box had to be rewired in order to move the 1st CPU to the middle of the box) for the ACP/TPF market. Then because 3081K single CPU would have been only half the MIPS of Amdahl single CPU ... there were numerous 3083 microcode tweaks specifically for the ACP/TPF market.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
some posts reference to ACP/TPF VM370 multiprocessor tweaks degrading
performance for every other VM370 multiprocessor customers
https://www.garlic.com/~lynn/2025d.html#16 Some VM370 History
https://www.garlic.com/~lynn/2024g.html#84 IBM 4300 and 3370FBA
https://www.garlic.com/~lynn/2023f.html#87 FAA ATC, The Brawl in IBM 1964
https://www.garlic.com/~lynn/2023c.html#9 IBM Downfall
https://www.garlic.com/~lynn/2022f.html#49 z/VM 50th - part 2
https://www.garlic.com/~lynn/2022e.html#99 Enhanced Production Operating Systems II
https://www.garlic.com/~lynn/2022d.html#31 COMPUTER HISTORY: REMEMBERING THE IBM SYSTEM/360 MAINFRAME, its Origin and Technology
https://www.garlic.com/~lynn/2022b.html#94 Computer BUNCH
https://www.garlic.com/~lynn/2021i.html#77 IBM ACP/TPF
https://www.garlic.com/~lynn/2021i.html#75 IBM ITPS
https://www.garlic.com/~lynn/2021g.html#90 Was E-mail a Mistake? The mathematics of distributed systems suggests that meetings might be better
https://www.garlic.com/~lynn/2021.html#72 Airline Reservation System
https://www.garlic.com/~lynn/2016.html#81 DEC and The Americans
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CMS SFS (Shared File System) Date: 14 Feb, 2026 Blog: Facebook60s as undergraduate, Univ. hired me fulltime responsible for OS/360 (they got a 360/67 originally for tss/360 replacing 709/1401, but used it as 360/65) ... and one of the things I had to deal with was overhead of PDS directory and multi-track search. And later at IBM would be periodically be called into customer accounts with the problem. Example was datacenter for one of the largest national grocery store chains ... all of the IBM MVS performance experts had been brought through before getting around to calling me.
Customer had multi-CEC 168 complex in loosley-coupled configuration ... with regions stores load-balanced across the 168 systems. I was brought into classroom with large piles of system activity reports for all the systems. After about 30mins, I noticed that specific activity of one (3330) disk peaked around 6-7/sec aggregate across all systems.
Turns out drive was shared across all systems & containing PDS dataset for store controller apps for all stores in the US. It had a 3cyl PDS directory ... single app load required avg 1.5cyl multi-track search, two I/Os for 1.5*19=28.5tracks at 60revs/sec or .475sec plus the I/O to read app .... aka bottle necked at loading two apps/sec throughput for servicing every store controller in the country.
from old 850822 email:
As most of you know, Endicott has proposed a shared file system for
VM/SP6 based on a SQL database.
trivia: transferred from CSC to SJR in 1977 and worked with Jim Gray
and Vera Watson on the original SQL/relational DBMS, System/R ... had
been done on VM/145. Then in early 80s was able to do tech transfer
"under the radar" (while company was preoccupied with the next great
DBMS, "EAGLE") for SQL/DS (after "EAGLE" imploded there was request
for how fast could System/R be ported to MVS).
Note after Future System imploded
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
the head of POK was in process of convincing corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA (Endicott eventually manages to acquire the VM370 product mission for the mid-range, but had to recreate a development group from scratch).
Some of the original VM370 group did a very simplified virtual machine for MVS/XA testing (VMTOOL) never intended for production or customers (in part because required SIE instruction but 3081 had limited microcode space and had to "page" SIE microcode). Amdahl was having more success because they had done microcode "multiple domain"/hypervisor able to run MVS & MVS/XA concurrently on the same machine. VMTOOL was eventual package for release as VM/MA (migration aid) and VM/SF (system facility).
trivia: note just prior to shutdown of the original VM370 development group there was very extensive, sophisticated CMS processing R/W support of MVS filesystems ... all of which evaporated.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
posts mentioning 3081 & paging SIE microcode
https://www.garlic.com/~lynn/2026.html#25 Amdahl Computers
https://www.garlic.com/~lynn/2025e.html#67 Mainframe to PC
https://www.garlic.com/~lynn/2025d.html#63 Amdahl Leaves IBM
https://www.garlic.com/~lynn/2025b.html#55 POK High-End and Endicott Mid-range
https://www.garlic.com/~lynn/2025b.html#46 POK High-End and Endicott Mid-range
https://www.garlic.com/~lynn/2025.html#120 Microcode and Virtual Machine
https://www.garlic.com/~lynn/2024g.html#36 What is an N-bit machine?
https://www.garlic.com/~lynn/2024c.html#91 Gordon Bell
https://www.garlic.com/~lynn/2024b.html#12 3033
https://www.garlic.com/~lynn/2024.html#50 Slow MVS/TSO
https://www.garlic.com/~lynn/2023g.html#78 MVT, MVS, MVS/XA & Posix support
https://www.garlic.com/~lynn/2023c.html#61 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2023.html#55 z/VM 50th - Part 6, long winded zm story (before z/vm)
https://www.garlic.com/~lynn/2022e.html#9 VM/370 Going Away
https://www.garlic.com/~lynn/2022.html#82 Virtual Machine SIE instruction
https://www.garlic.com/~lynn/2019b.html#78 IBM Tumbles After Reporting Worst Revenue In 17 Years As Cloud Hits Air Pocket
https://www.garlic.com/~lynn/2019b.html#77 IBM downturn
https://www.garlic.com/~lynn/2019.html#38 long-winded post thread, 3033, 3081, Future System
https://www.garlic.com/~lynn/2018e.html#30 These Are the Best Companies to Work For in the U.S
https://www.garlic.com/~lynn/2017c.html#81 GREAT presentation on the history of the mainframe
https://www.garlic.com/~lynn/2017c.html#80 Great mainframe history(?)
https://www.garlic.com/~lynn/2016b.html#78 Microcode
https://www.garlic.com/~lynn/2013n.html#46 'Free Unix!': The world-changing proclamation made30yearsagotoday
https://www.garlic.com/~lynn/2011p.html#114 Start Interpretive Execution
https://www.garlic.com/~lynn/2011i.html#63 Before the PC: IBM invents virtualisation (Cambridge skunkworks)
https://www.garlic.com/~lynn/2011b.html#18 Melinda Varian's history page move
https://www.garlic.com/~lynn/2011.html#62 SIE - CompArch
https://www.garlic.com/~lynn/2010n.html#71 Fujitsu starts shipping 800 rack 80,000 chip 'K' supercomputer
https://www.garlic.com/~lynn/2010m.html#55 z millicode: where does it reside?
https://www.garlic.com/~lynn/2010e.html#76 LPARs: More or Less?
https://www.garlic.com/~lynn/2010e.html#51 LPARs: More or Less?
https://www.garlic.com/~lynn/2009r.html#51 "Portable" data centers
https://www.garlic.com/~lynn/2007e.html#39 FBA rant
https://www.garlic.com/~lynn/2006n.html#44 Any resources on VLIW?
https://www.garlic.com/~lynn/2006l.html#22 Virtual Virtualizers
https://www.garlic.com/~lynn/2006j.html#27 virtual memory
https://www.garlic.com/~lynn/2004n.html#10 RISCs too close to hardware?
https://www.garlic.com/~lynn/2002p.html#44 Linux paging
https://www.garlic.com/~lynn/2002p.html#40 Linux paging
https://www.garlic.com/~lynn/2002o.html#15 Home mainframes
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Downfall Date: 14 Feb, 2026 Blog: FacebookIBM totally changed; Learson tried (& failed) to block the bureaucrats, careerists, and MBAs from destroying Watson culture/legacy, pg160-163, 30yrs of management briefings 1958-1988
FS completely different from 370 and going to completely replace it
(during FS, internal politics was killing off 370 efforts, limited new
370 is credited with giving 370 system clone makers their market
foothold). One of the final nails in the FS coffin was analysis by the
IBM Houston Science Center that if 370/195 apps were redone for FS
machine made out of the fastest available hardware technology, they
would have throughput of 370/145 (about 30 times slowdown). Claim that
if any other computer company had a loss the magnitude of FS, they
would have been bankrupt and out of business.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
The F/S implosion, from: Computer Wars: The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
Then (20 yrs after Learson tried&failed to block destruction of Watson
culture/legacy) IBM has one of the largest losses in the history of US
companies and was being reorganized into the 13 "baby blues" in
preparation for breaking up the company (take-off on "baby bell"
breakup decade earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
Undergraduate, within year of taking 2 credit hour intro to fortran/computers, univ hired me fulltime responsible of OS/360 (univ got a 360/67 for tss/360 replacing 709/1401, but ran it as 360/65). Then before I graduate, I'm hired into small group in the Boeing CFO office to help with the formation of Boeing Computer Services (consolidate all dataprocessing into independent business unit). I think Renton datacenter largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Both Boeing and IBM people tell story of Boeing walking into IBM marketing rep'ss office on day 360 was announced with a large order, making him the highest earning IBM employee that year (in the days of straight commission). Next year, IBM introduces sales quota plans and Boeing makes another large order in Jan, making the rep's quota for the year. IBM then adjusts his quota and he leaves IBM.
When I graduate, I join IBM Science Center instead of staying with the Boeing CFO; and one of my hobbies was enhanced production operating systems for internal datacenters and the online sales&marketing support HONE systems were one of first and long time internal customers.
IBM US 23Jan1969 Unbundling announcement started to charge for (appliction) software (managed to make the case that kernel software was still free), SE services, maint., etc. SE training had included part of group at customer's datacenter.
However, IBM couldn't figure out how to not charge for SE trainee time at the customer. Thus was born several CP67 datacenters around the US where branch office SE trainees could logon to HONE CP67 system and practice with guest operating systems running in virtual machines. The science center had also ported APL\360 to CP67/CMS as CMS\APL (redoing storage from 16kbyte swapped workspaces to large virtual memory demand paged workspace and API for system services like file I/O enabling real world applications), and HONE started providing CMS\APL-based sales&marketing support applications, eventually coming to dominate all HONE activity (and practice with guest operating systems just withered away). Trivia: in mid-70s, US HONE datacenters were consolidated in Palo Alto; when FACEBOOK 1st moved into silicon valley it was into a new bldg built next door to the former consolidated US HONE datacenter.
After joining IBM, I was told that you can always tell when something
wasn't selling; it was declared strategic and bonus established for
selling ... like early MVS (I think song 1st sung at Denver SHARE
meeting)
http://www.mxg.com/thebuttonman/boney.asp
including
$4K - MVS was the first operating system for which the IBM Salesman
got a $4000 bonus if he/she could convince their customer to install
VS 2.2 circa 1975. IBM was really pissed off that this fact became
known thru this song.
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
IBM Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Enhanced production operating system posts, CP67L, CSC/VM SJR/VM
https://www.garlic.com/~lynn/submisc.html#cscvm
23June1969 Unbundline posts
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Supercomputer Date: 15 Feb, 2026 Blog: Facebook1988, branch office asks if I could help SLAC/Gustavson with SCI standard (various uses including shared memory multiprocessor, up to 64 cache consistency, some efforts Data General and Sequent 64 4-i486 boards (256 processors), Convex 64 2-HP-snake boards (128 processor), SGI 64 4-MIPS boards, etc),
same time as asked about helping LLNL (national lab) with
fibre-channel standard ("FCS", initial 1gbit transfer, full-duplex,
aggregate 200mbyte/sec)
https://en.wikipedia.org/wiki/Fibre_Channel
also 1988, Nick Donofrio approves HA/6000, initially for NYTimes to
move their newspaper system (ATEX) off DEC VAXCluster to RS/6000, I
rename it HA/CMP when I start doing (technical/scientific) cluster
scale-up with national labs (LANL, LLNL, NCAR, etc) and commercial
cluster scale-up with RDBMS vendors (Oracle, Sybase, Ingres, Informix)
with VAXCluster support in same source base with UNIX
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
Conti had sponsored Kingston supercomputing effort as well as funneling money to Steve Chen for SSI (Supercomputer Systems Incorporated). Conti retires Oct1991 and his "projects" were audited ... one result was internal conference setup basically part of scouring the company for technology that might be used for supercomputer.
Early Jan92, there was meeting with Oracle CEO and IBM/AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid-jan92, I update FSD on HA/CMP
work with national labs and FSD decides to go with HA/CMP for federal
supercomputers. By end of Jan, we are told that cluster scale-up is
being transferred to Kingston for announce as IBM Supercomputer
(technical/scientific *ONLY*) and we aren't allowed to work with
anything that has more than four systems (we leave IBM a few months
later). A couple weeks later, 17feb1992, Computerworld news ... IBM
establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS, 128-systems: 16BIPS
After leaving IBM, I do some consulting for Steve Chen who was then
CTO at Sequent (before IBM buys Sequent and shuts it down).
previous posts refering to Conti retires oct1991
https://www.garlic.com/~lynn/2021j.html#42 IBM Business School Cases
https://www.garlic.com/~lynn/2021j.html#2 IBM Lost Opportunities
https://www.garlic.com/~lynn/2018c.html#72 Indian Casino and HA/CMP
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
FCS and/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
previous posts referencing sequent, exemplar, steve chen
https://www.garlic.com/~lynn/2023.html#42 IBM AIX
https://www.garlic.com/~lynn/2019.html#32 Cluster Systems
https://www.garlic.com/~lynn/2015g.html#72 100 boxes of computer books on the wall
https://www.garlic.com/~lynn/2014.html#71 the suckage of MS-DOS, was Re: 'Free Unix!
https://www.garlic.com/~lynn/2013n.html#50 'Free Unix!': The world-changing proclamation made30yearsagotoday
https://www.garlic.com/~lynn/2013h.html#6 The cloud is killing traditional hardware and software
https://www.garlic.com/~lynn/2010i.html#61 IBM to announce new MF's this year
https://www.garlic.com/~lynn/2009s.html#5 While watching Biography about Bill Gates on CNBC last Night
https://www.garlic.com/~lynn/2009o.html#29 Justice Department probing allegations of abuse by IBM in mainframe computer market
https://www.garlic.com/~lynn/2006y.html#38 Wanted: info on old Unisys boxen
https://www.garlic.com/~lynn/2006q.html#9 Is no one reading the article?
https://www.garlic.com/~lynn/2003d.html#57 Another light on the map going out
https://www.garlic.com/~lynn/2002h.html#42 Looking for Software/Documentation for an Opus 32032 Card
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Supercomputer Date: 15 Feb, 2026 Blog: Facebookre:
When Future System imploded
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
there was mad rush to get stuff back into the 370 product pipelines, including kick off the quick&dirty 3033&3081
I also got asked to help with a 16-CPU 370 and we con the 3033
processor engineers into helping in their spare time. Everybody thot
it was great until somebody tells the head of POK that it could be
decades before POK favorite son operating system ("MVS") had
(effective) 16-CPU mutliprocessor support (POK doesn't ship 16-CPU
machine until after the turn of the century). At the time MVS
documentation had 2-CPU support only getting 1.2-1.5 times the
throughput of a 1-CPU (of the same model), aka MVS multiprocessor
overhead so large. Then head of POK asks some of us to never visit POK
again and directed 3033 processor engineers, heads down and no
distractions. Once the 3033 was out the door the processor engineers
start on trout/3090. Later email from engineer
Date: 04/23/81 09:57:42
To: wheeler
your ramblings concerning the corp(se?) showed up in my reader
yesterday. like all good net people, i passed them along to 3 other
people. like rabbits interesting things seem to multiply on the
net. many of us here in pok experience the sort of feelings your mail
seems so burdened by: the company, from our point of view, is out of
control. i think the word will reach higher only when the almighty $$$
impact starts to hit. but maybe it never will. its hard to imagine one
stuffed company president saying to another (our) stuffed company
president i think i'll buy from those inovative freaks down the
street. '(i am not defending the mess that surrounds us, just trying
to understand why only some of us seem to see it).
bob tomasulo and dave anderson, the two poeple responsible for the
model 91 and the (incredible but killed) hawk project, just left pok
for the new stc computer company. management reaction: when dave told
them he was thinking of leaving they said 'ok. 'one word. 'ok. ' they
tried to keep bob by telling him he shouldn't go (the reward system in
pok could be a subject of long correspondence). when he left, the
management position was 'he wasn't doing anything anyway. '
in some sense true. but we haven't built an interesting high-speed
machine in 10 years. look at the 85/165/168/3033/trout. all the same
machine with treaks here and there. and the hordes continue to sweep
in with faster and faster machines. true, endicott plans to bring the
low/middle into the current high-end arena, but then where is the
high-end product development?
... snip ... top of post, old email index
trivia: 3033 started out remapping 168 logic to 20% faster chips. 165
microcode avg 2.1 processor cycles per 370 instructions. This was
improved for 168 microcode to avg 1.6 processor cycles per 370
instruction and for 3033, to one 370 instruction per processor cycle.
Date: 2/10/81 14:05
To: wheeler
...
We have a new problem in cache management. The 3081 has cache lines
containing pageable microcode: about 1000 words (108 bits) of
non-pageable and about 1000 words of pageable. Unfortunately, it
appears that these 1000 words of pageable microcode are not enough to
hold both the VM and the MVS microcode for the new goodies present in
811 architecture. I'm hoping our analysis was wrong and that is not
what we are looking at, but it indeed appears to be. It may be a few
years yet before we see an 811 suitable for use by VM.
Even if we have enough microcode cache, there is a small cache size
for other work in comparison to the storage size. It was designed
with 16M in mind and has been 'upgraded' to 64M without increasing the
cache size (brilliant move). There is thought of requesting
architecture to define an instruction to cast out all altered cache
lines from the store-through cache. This would place cache management
under more direct control from the scheduler.
...
While the pageable microcode cache seems to be inadequate for both
VM/370 and VM/811 (VM/370 was hoping to catch VM/PE, but VMA+MVSA is
too tight a fit), it is much worse for VM/811 than for
VM/370. Management is still talking about 12/82 delivery dates (which
they in fact made impossible when they decided to re-convert all
control blocks, module names and linkage conventions last summer). I
live in a mad-house.
... snip ... top of post, old email index
trivia: 370/xa design and architecture documents were called "811" for their nov1978 publication date.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
past posts referring to 370/xa as "811" for document Nov1978
publication dates
https://www.garlic.com/~lynn/2026.html#39 IBM Security
https://www.garlic.com/~lynn/2026.html#12 IBM Virtual Machine and Virtual Memory
https://www.garlic.com/~lynn/2025e.html#61 "Business Ethics" is Oxymoron
https://www.garlic.com/~lynn/2025d.html#23 370 Virtual Memory
https://www.garlic.com/~lynn/2025c.html#77 IBM 4341
https://www.garlic.com/~lynn/2025.html#120 Microcode and Virtual Machine
https://www.garlic.com/~lynn/2025.html#61 old pharts, Multics vs Unix
https://www.garlic.com/~lynn/2024f.html#113 IBM 370 Virtual Memory
https://www.garlic.com/~lynn/2024f.html#77 IBM Registered Confidential and "811"
https://www.garlic.com/~lynn/2024d.html#113 ... some 3090 and a little 3081
https://www.garlic.com/~lynn/2024d.html#100 Chipsandcheese article on the CDC6600
https://www.garlic.com/~lynn/2024b.html#58 Vintage MVS
https://www.garlic.com/~lynn/2024.html#50 Slow MVS/TSO
https://www.garlic.com/~lynn/2023g.html#2 Vintage TSS/360
https://www.garlic.com/~lynn/2023.html#59 Classified Material and Security
https://www.garlic.com/~lynn/2022h.html#69 Fred P. Brooks, 1931-2022
https://www.garlic.com/~lynn/2022d.html#35 IBM Business Conduct Guidelines
https://www.garlic.com/~lynn/2022c.html#4 Industrial Espionage
https://www.garlic.com/~lynn/2022.html#48 Mainframe Career
https://www.garlic.com/~lynn/2022.html#47 IBM Conduct
https://www.garlic.com/~lynn/2021k.html#125 IBM Clone Controllers
https://www.garlic.com/~lynn/2021k.html#113 IBM Future System
https://www.garlic.com/~lynn/2021j.html#38 IBM Registered Confidential
https://www.garlic.com/~lynn/2021i.html#17 Versatile Cache from IBM
https://www.garlic.com/~lynn/2021d.html#86 Bizarre Career Events
https://www.garlic.com/~lynn/2021b.html#12 IBM "811", 370/xa architecture
https://www.garlic.com/~lynn/2019e.html#75 Versioning file systems
https://www.garlic.com/~lynn/2019e.html#29 IBM History
https://www.garlic.com/~lynn/2019d.html#115 Assembler :- PC Instruction
https://www.garlic.com/~lynn/2019.html#83 The Sublime: Is it the same for IBM and Special Ops?
https://www.garlic.com/~lynn/2018.html#99 Prime
https://www.garlic.com/~lynn/2017i.html#62 64 bit addressing into the future
https://www.garlic.com/~lynn/2017i.html#57 64 bit addressing into the future
https://www.garlic.com/~lynn/2017f.html#35 Hitachi to Deliver New Mainframe Based on IBM z Systems in Japan
https://www.garlic.com/~lynn/2017e.html#67 [CM] What was your first home computer?
https://www.garlic.com/~lynn/2015h.html#116 Is there a source for detailed, instruction-level performance info?
https://www.garlic.com/~lynn/2015f.html#88 Formal definition of Speed Matching Buffer
https://www.garlic.com/~lynn/2014k.html#82 Do we really need 64-bit DP or is 48-bit enough?
https://www.garlic.com/~lynn/2014f.html#22 Complete 360 and 370 systems found
https://www.garlic.com/~lynn/2014e.html#40 The mainframe turns 50, or, why the IBM System/360 launch was the dawn of enterprise IT
https://www.garlic.com/~lynn/2013m.html#71 'Free Unix!': The world-changing proclamation made 30 years agotoday
https://www.garlic.com/~lynn/2012g.html#19 Co-existance of z/OS and z/VM on same DASD farm
https://www.garlic.com/~lynn/2012c.html#29 5 Byte Device Addresses?
https://www.garlic.com/~lynn/2012c.html#20 M68k add to memory is not a mistake any more
https://www.garlic.com/~lynn/2012b.html#66 M68k add to memory is not a mistake any more
https://www.garlic.com/~lynn/2011n.html#31 big-little
https://www.garlic.com/~lynn/2011g.html#12 Clone Processors
https://www.garlic.com/~lynn/2011g.html#8 Is the magic and romance killed by Windows (and Linux)?
https://www.garlic.com/~lynn/2011g.html#2 WHAT WAS THE PROJECT YOU WERE INVOLVED/PARTICIPATED AT IBM THAT YOU WILL ALWAYS REMEMBER?
https://www.garlic.com/~lynn/2011f.html#50 Dyadic vs AP: Was "CPU utilization/forecasting"
https://www.garlic.com/~lynn/2011f.html#46 At least two decades back, some gurus predicted that mainframes would disappear in future and it still has not happened
https://www.garlic.com/~lynn/2011f.html#39 At least two decades back, some gurus predicted that mainframes would disappear in future and it still has not happened
https://www.garlic.com/~lynn/2011f.html#20 New job for mainframes: Cloud platform
https://www.garlic.com/~lynn/2011c.html#67 IBM Future System
https://www.garlic.com/~lynn/2011b.html#70 vm/370 3081
https://www.garlic.com/~lynn/2010h.html#3 Far and near pointers on the 80286 and later
https://www.garlic.com/~lynn/2010h.html#2 Far and near pointers on the 80286 and later
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 303x Channel Director Date: 16 Feb, 2026 Blog: FacebookFirst half 70s, IBM had Future System project ... completely different from 370 and going to completely replace it (internal politics was killing off 370 efforts and claim is lack of new 370 during the period is responsible for giving clone 370 makers (like Amdahl) their market foothold).
For the 303x channel director (external channels), they took 158 engine with just integrated channels microcode. I did number of I/O benchmarks for 370/148, 370/158, and 370/168 ... with 158 being slowest. For 3031, there was two 158 engines, one with just the integrated channel microcode and 2nd with just the 370 microcode. For 3032 they took 168 reworked to use 303x channel director (158 enginewith just integrated channel microcode). 3033 started out with 168 logic remapped to 20% faster chips and up to three 303x channel directors.
After being invited to never visit POK again (for working with 3033 processor engineers on a 16-CPU 370 system), I transfer out to San Jose Research and get to wander around silicon valley datacenters, including disk bldg14/engineering and bldg15/product test across the street. They had been doing 7/24, prescheduled stand-alone testing and mentioned that recently they had tried MVS, but it had 15min MTBF (in that environment). I offer to rewrite I/O Supervisor, making it bullet proof and never fail allowing any amount of ondemand, concurrent testing (greatly improving productivity).
One of the channel benchmarks was how fast could 3330 track (on same cylinder) be switched (maximizing how much data/records ... on different tracks ... could be transferred in single revolution).
Bldg15 then gets 1st engineering 3033 outside POK engineering. 3033 I/O testing took only percent or two of CPU, so we scrounge up spare 3830 and 3330 string and setup our own private online service. Early on we were finding 303x channel directors were hanging requiring manual re-IMPL. Find that if I quickly hit every (303x director) channel address with CLRCH would automagically re-IMPL.
posts mentioning getting to play disk engineer
https://www.garlic.com/~lynn/subtopic.html#disk
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Mainframe TCP/IP and RFC1044 Date: 17 Feb, 2026 Blog: Facebookre:
I originally did (dynamic adaptive resource manager) "wheeler scheduler" as undergraduate in the 60s for cp/67 (precursor to vm370). With the decision to add virtual memory to all 370s, they also decided to morph CP67 into VM370 (and simplified or dropped lots of feature/function, including wheeler scheduler and multiprocessor support).
Tymshare started providing their CMS-based online computer
conferencing system to SHARE organization as VMSHARE in Aug1976. After
M/D acquires Tymshare in the 80s, VMSHARE was moved to another
platfrom. Early on I had cut a deal with Tymshare to get a monthly
tape dump of all VMSHARE files for putting up on internal systems
(including online sales&marketing support HONE systems) and
internal network; archived here
http://vm.marist.edu/~vmshare
Date: Sat, 11 Jan 1986 15:26:02 EST
From: Melinda Varian MAINT@PUCC
To: Lynn Wheeler WHEELER@ALMVMA
Subject: From VMSHARE....
PROB HPOGRIND - 48 lines, 0 append(s)
HPO 3.4 allows a user to run away with the CPU
One of the reasons we were always happy to pay to get a Wheeler
scheduler, beginning way back in the PRPQ days, was that it did such a
good job of protecting other users from a CPU hog.
Indeed, several times a year we would have a user panic because he had
just discovered that his computer account was overdrawn by several
thousand dollars. The scenario was always the same. He had invoked a
program or EXEC he was working on; his terminal had gone dead, so he
had gone home for the night. A couple of days later, he tried to
logon again, found himself still logged on, and asked the operators to
force him. That's when he found he had no money left. Then he would
come to us. We'd tell him about loops, ask him not to do that again,
and give him his money back.
The interesting part of all this is that the Wheeler Scheduler had
been doing such a good job of protecting the system from the looping
user, that nobody had noticed him. The scheduler just kept him in the
background absorbing the spare cycles, but didn't let him use the
cycles somebody else wanted.
This is not at all the way the HPO 3.4 scheduler works, however. In
the year we've been running it, we have seen numerous cases in which
one or two heavy CPU users severely degraded the performance of the
entire system.
These people are not paging heavily and are not doing a lot of I/O.
(VM has never done a real good job of containing users who put
excessive loads on memory/paging or I/O.) They are using CPU only and
generally have very small working sets. Typically, their TVRATIO's
are 1.0.
And the HPO 3.4 scheduler lets a single such user have as much as 90%
of one processor in the middle of the afternoon, when there are plenty
of other users who need (and deserve) some of those cycles.
I'm rather at a loss to figure out how to approach IBM on this
problem. I don't want to be told that the scheduler is working as
designed. Does anybody have any suggestions? Also, do other people
see this problem?
... snip ... top of post, old email index
Date: 04/04/86 13:18:06
From: Lynn Wheeler WHEELER@ALMVMA
To: Melinda Varian MAINT@PUCC
is your location connected to the super-computer center? I'm trying to
see how many of the proposed nodes on the super-computer backbone
network have VM systems (at least nearby) and level programming
difficulty I may have putting it all together and talking to them from
LSG.
... snip ... top of post, old email index
Date: Mon, 7 Apr 1986 12:20:32 EST
From: Melinda Varian MAINT@PUCC
To: Lynn Wheeler WHEELER@ALMVMA
lots of stuff about CYBER 205 hasn't been installed yet, but lots of
stuff planned for Princeton Supercomputer center
ending with: "Thank you very much for your recent notes about
hungusers. I am still struggling with the problem"
... snip ... top of post, old email index
Early 80s got HSDT project, T1 and faster computer links, both terrestrial and satellites ... and battles with the communication group (note in the 60s, IBM had 2701 telecommunication controller that supported T1, but in the transition to SNA/VTAM in the 70s, issues capped controllers at 56kbit/sec). Part of the funding was being able to show some IBM content (since otherwise, everything was going to be non-IBM). I eventually found the FSD special bid, Series/1 T1 Zirpel cards (for gov. customers with failing 2701s). I went to order half dozen Series/1 but found there was year's backlog for orders. This was right after the ROLM purchase and Rolm had made a really large Series/1 order (they were otherwise a data general shop, and trying to show their new owners they were part of the organization). I found that I knew the Rolm datacenter manager ... that had left IBM some years before. They offered to transfer me some Series/1s, if I would help them with some of their problems (one was that they were using 56kbit/sec links to load test switch software which was taking 24hrs, and they would really like upgrading to T1, radically reducing their testing process cycle time).
We were also working with NSF director and was suppose to get $20M to
interconnect the NSF Supercomputer centers. Then congress cuts the
budget, some other things happen and eventually an RFP is released (in
part based on what we already had running). NSF 28Mar1986 Preliminary
Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
Later the NSF director leaves NSF and joins a DC lobbying group (council on competitiveness) and we would try and periodically drop in to see him.
Also at the time there was lots of internal network SNA/VTAM
misinformation (including converting the internal network to SNA/VTAM)
and there was similar misinformation about being able to use SNA/VTAM
for NSFNET. Somebody was collecting internal NSFNET SNA/VTAM
misinformation email and forwarded it to us (following heavily clipped
& redacted to protect the guilty):
https://www.garlic.com/~lynn/2006w.html#email870109
Dymamic adaptive resource manager ("wheeler scheduler") posts
https://www.garlic.com/~lynn/subtopic.html#fairshare
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 6670 Printer Date: 19 Feb, 2026 Blog: Facebooksan jose research 1979 (before move up the hill to new almaden bldg, mid-80s) got ibm copiers with computer interface for departmental 6670 laser printers spread around the bldg. colored paper in the alternate paper drawer for output separator ... page mostly blank ... so modified driver and would print random quotations ... from couple different source files, including ibmjargon
Then 6670s were modified for SHERPA/APA6670 ... aka do images (all
point addressable) and able to scan input. Later did Adobe Postscript
processor for SHERPA.
Date: 03/04/82 10:26-PM
From: somebody in san jose
To: somebody at boulder
CC: wheeler
Lynn Wheeler forwarded me your mail about the Boulder satelite link.
We have a joint project between two departments here in San Jose
Research which is building a 6670 laser printer/copier/scanner. I
should rather say that we are adding a scanner to the Boulder built
6670 laser printer/copier. My involvement is that we have built an
APA (all points addressable) control unit for the 6670 for printing
arbitrarily complex pages. We call it SHERPA. In fact, we installed
a copy of our controller in Boulder in December.
It has a 1M byte storage that hold a complete page image for
printing. It is serialized and sent to the 6670 at a 10Mhz data rate
(the 6670 laser speed). When we were designing the printer we also
made allowances for the hardware to run "backward", taking a 10Mhz
signal and filling the page image storage. Another group headed by
zzzzz San Jose Research, has modified a 6670 to allow the laser to
scan the toned photoconductor drum. We can dump the image into our
full page bit image storage.
One experiment that could be done with this high-speed scanner is to
use it as a "remote copier". One could put one on each end of a
high-speed data link and scan on one machine, transmit to the other
and print on it. It is conceivable that this could be done at 35
pages/minute.
We currently have a 56KB link between our SHERPA control unit and our
3033 host. On that bisync link it takes us 2 minutes to transmit a
full page (uncompressed) bit image of a page. While that is not the
mode for which we designed SHERPA it none-the-less supports it. We
designed it to behave more like a photocomposer, taking coded
character information with font selections and variable (flexible)
spacing. The SHERPA also supports including images with the printed
text and, in fact, the images can be as large as the whole page,
providing the facimile like capability.
What I would envision is encoding the scanned image inside the SHERPA,
itself, to reduce the data from roughly 670,000 bytes/page to maybe
100,000 bytes. These would be sent to the 3033 host to be transmitted
to the remote site. There the process would be reversed to form the
printed image. Since we already have a SHERPA in Boulder and in fact
are modifying a second 6670 for the manager of Boulder printer
products, zzzzzzz, for Boulder experimentation, it would be the ideal
set up for a high-speed link to demonstrate such a system. I would
envision a link from host VM to VM. If it were 56KB and we could get
a compression ratio of 4 to 1 or better with a simple algorithm, we
could send about 2 pages/minute. One could possibly do much better.
I am typing this at home just before bedtime so am not too sure if it
is very easy to read, but will send it on anyway. If you would like
to discuss this further please call me. You may also wish to look at
the SHERPA there: contact zzzzzz or zzzzz. They have the SHERPA set
up in Bldg. 22 (print only).
I would imagine that zzzzz would give this kind of project some
support. This is one way to make the 6670 do what the TV commercials
show it doing.
... snip ... top of post, old email index
There was Harvard Business Case about IBM TV commercial showing how it was much easier to clear IBM paper jams (than competitors) .... which was major failure because it (turns out) people hated being reminded about how much they disliked paper jams (IBM tended to have larger numbers of paper jams).
Early 80s got HSDT project, T1 and faster computer links, both terrestrial and satellites ... and battles with the communication group (note in the 60s, IBM had 2701 telecommunication controller that supported T1, but in the transition to SNA/VTAM in the 70s, issues capped controllers at 56kbit/sec). Part of the funding was being able to show some IBM content (since otherwise, everything was going to be non-IBM). I eventually found the FSD special bid, Series/1 T1 Zirpel cards (for gov. customers with failing 2701s). I went to order half dozen Series/1 but found there was year's backlog for orders. This was right after the ROLM purchase and Rolm had made a really large Series/1 order (they were otherwise a data general shop, and trying to show their new owners they were part of the organization). I found that I knew the Rolm datacenter manager ... that had left IBM some years before. They offered to transfer me some Series/1s, if I would help them with some of their problems (one was that they were using 56kbit/sec links to load test switch software which was taking 24hrs, and they would really like upgrading to T1, radically reducing their testing process cycle time).
We were also working with NSF director and was suppose to get $20M to
interconnect the NSF Supercomputer centers. Then congress cuts the
budget, some other things happen and eventually an RFP is released (in
part based on what we already had running). NSF 28Mar1986 Preliminary
Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
Also at the time there was lots of internal network SNA/VTAM
misinformation (including converting the internal network to SNA/VTAM)
and there was similar misinformation about being able to use SNA/VTAM
for NSFNET. Somebody was collecting internal NSFNET SNA/VTAM
misinformation email and forwarded it to us (following heavily clipped
& redacted to protect the guilty):
https://www.garlic.com/~lynn/2006w.html#email870109
Later the NSF director leaves NSF and joins a DC lobbying group (council on competitiveness) and we would try and periodically drop in to see him.
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
Internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM CP67 and VM370 Date: 19 Feb, 2026 Blog: FacebookI took two credit hr intro to fortran/computers and at end of semester was hired to rewrite 1401 MPIO for 360/30 in assembler. Univ was getting 360/67 for tss/360 (replacing 709/1401) and got a 360/30 temporarily pending 360/68 availability. Univ shutdown datacenter on weekends and I had whole place dedicated (although 48hrs w/o sleep made monday classes hard). I was given stack of software/hardware manuals and got to design and implement my own monitor, device drivers, interrupt handlers, error recovery, storage management, etc. Within a year of taking intro class, 360/67 arrives and I'm hired fulltime responsible for os/360 (tss/360 didn't come to production).
709 student fortran ran in under a second, initially 360/67 os/360 ran over a minute. I install HASP cutting time in half. I then redo STAGE2 SYSGEN to carefully place datasets and PDS members optimizing seek and multi-track search, cutting another 2/3rds to 12.9secs. os/360 never got better than 709 until I install UofWaterloo WATFOR. 65/67 WATFOR clocked at 20,000 statements/min (333/statements/sec, typical student fortran 30-60 statements).
CSC comes out to install CP67/CMS (3rd after CSC itself and MIT Lincol Labs) and I mostly get to play with it during my dedicated weekend time. I initially work on rewriting pathlengths to optimize running OS/360 in virtual machines. Test stream was 322secs, under CP67 ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher/scheduler , (dynamic adaptive resource manager/default fair share scheduling policy), paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 online commercial spin-offs.
Then before I graduate, I'm hired fulltime into small group in the Boeing CFO office to help with the formation of Boeing Computer Services (consolidate all dataprocessing into independent business unit including offering services to non-Boeing entities). I think Renton largest IBM datacenter in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Lots of politics between Renton director and CFO who only had 360/30 for payroll up at Boeing Field (although they enlarge the room for 360/67 for me to play with when i wasn't doing other stuff).
First half 70s, IBM had Future System project ... completely different
from 370 and going to completely replace it (internal politics was
killing off 370 efforts and claim is lack of new 370 during the period
is responsible for giving clone 370 makers (like Amdahl) their market
foothold).
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
when FS implodes, there is mad rush to get stuff back into 370 product
pipelines, including quick&dirty 3033&3081 efforts.
For the 303x channel director (external channels), they took 158 engine with just integrated channels microcode. I did number of I/O benchmarks for 370/148, 370/158, and 370/168 ... with 158 being slowest. For 3031, there was two 158 engines, one with just the integrated channel microcode and 2nd with just the 370 microcode. For 3032 they took 168 reworked to use 303x channel director (158 engine with just integrated channel microcode). 3033 started out with 168 logic remapped to 20% faster chips and up to three 303x channel directors.
After being invited to never visit POK again (for working with 3033 processor engineers on a 16-CPU 370 system, everybody thought it was great until somebody tells head of POK that it could take POK's favorite son operating system, "MVS", until it has effective 16-CPU support; MVS docs had the 2-CPU support only had 1.2-1.5 times throughput of single CPU; POK doesn't ship 16-CPU system until after turn of century), I transfer out to San Jose Research and get to wander around silicon valley datacenters, including disk bldg14/engineering and bldg15/product test across the street. They had been doing 7/24, prescheduled stand-alone testing and mentioned that recently they had tried MVS, but it had 15min MTBF (in that environment). I offer to rewrite I/O Supervisor, making it bullet proof and never fail allowing any amount of ondemand, concurrent testing (greatly improving productivity).
note: Boeing Huntsville had gotten 2-CPU 360/67 for tss/360 with lots of 2250s for CAD/CAM, but ran it as two 360/65 MVT systems and had ran into early MVT storage management problem. They made simple modifications to MVT13 to run in virtual memory mode (w/o paging) as partial countermeasure to MVT storage management issues. Their 2-CPU 360/67 system moved to Seattle while I was in CFO office. When I graduate, I join CSC (instead of staying w/CFO).
One of the channel benchmarks was how fast could 3330 track (on same cylinder) be switched (maximizing how much data/records ... on different tracks ... could be transferred in single revolution).
Bldg15 then gets 1st engineering 3033 outside POK engineering. 3033 I/O testing took only percent or two of CPU, so we scrounge up spare 3830 and 3330 string and setup our own private online service. Early on we were finding 303x channel directors were hanging requiring manual re-IMPL. Find that if I quickly hit every (303x director) channel address with CLRCH would automagically re-IMPL.
I write an internal research report on the I/O integrity work and happened to mention MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
Back to after graduating, leaving Boeing and joining CSC, one of my hobbies was enhanced production operating systems for internal datacenters (including online sales&marketing support HONE systems was one of the 1st and long time customers). Then decision to add virtual memory to all 370s, some of CSC people take-over the IBM Boston Programming Center for VM370 development group. For CP67->VM370, there was a lot of simplification and dropping features (including my 60s CP67 "Wheeler Scheduler" and multiprocessor support). I then start adding lots of stuff back into VM370R2-base for my internal CSC/VM (including "wheeler scheduler" and kernel re-org for multiprocessor, but not actual SMP support). Then for VM370R3-base CSC/VM, I include SMP support, originally for HONE so they could upgrade their 158s&168s to 2-CPU systems (getting 2-times throughput of the 1-CPU systems). This contributed to me being asked to help with 16-CPU 370 design and some of head of POK issues over MVS performance (Note after FS implosion, head of POK started lobbying corporate to kill the VM370 product, shutdown the VM370 development group and transfer all the people to POK for MVS/XA; Endicott eventually acquires the VM370 product mission for the mid-range, but had to recreate a development group from scratch).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
dynamic adaptive scheduling/resource management posts
https://www.garlic.com/~lynn/subtopic.html#fairshare
SMP, tightly-coupled, shared memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
some posts mentioning undergraduate, 709/1401, 1401 MPIO, student
fortran, watfor, cp/67, wheeler scheduler, boeing, cfo, renton
https://www.garlic.com/~lynn/2026.html#28 360 Channel
https://www.garlic.com/~lynn/2026.html#24 IBM 360, Future System
https://www.garlic.com/~lynn/2025c.html#115 IBM VNET/RSCS
https://www.garlic.com/~lynn/2024.html#87 IBM 360
https://www.garlic.com/~lynn/2022e.html#31 Technology Flashback
https://www.garlic.com/~lynn/2022.html#12 Programming Skills
https://www.garlic.com/~lynn/2018f.html#51 All programmers that developed in machine code and Assembly in the 1940s, 1950s and 1960s died?
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 135/145, 138/148, 4331/4341 Date: 20 Feb, 2026 Blog: FacebookFollow-on to 135&145 was 138&148 (after "Future System" imploded)
... FS was totally different from 370 and was going to completely replace 370 (during FS, internal politics was killing off 370 efforts and lack of new IBM 370 during FS is credited with giving clone 370 makers their market foothold).
Endicott cons me into helping with 138/148 (Virgil/Tully) microcode
assist ("ECPS") ... 138/148 370 microcode avg 10 microcode
instructions for every 370 instructions and ECPS translated 370
instruction to microcode instruction on appox. 1-for-1 basis with ten
times speedup. I was told that machines had approx 6kbytes microcode
space for ECPS. I was to identify the highest used instruction
pathlengths for translation to ECPS ... which turned out to account
for 79.55% of VM370 kernel execution ... old archived (1994) post with
the initial (1975) analysis:
https://www.garlic.com/~lynn/94.html#21
Then Endicott talks me into around the world trip, part of presenting 138/148 business case to country business planners. This was during the period when the head of POK was convincing corporate to kill the VM370 product, shutdown the development group, and transfer all the people to POK for MVS/XA (Endicott eventually manages to acquire the VM370 product mission for the mid-range, but had to recreate a development group from scratch). Then the attempt to have VM370 pre-installed on every 138/148 shipped was never approved by corporate.
I transfer out to SJR on the west coast and get to wander around datacenters on the west coast, including disk bldg14/engineering and bldg15/product test, across the street. They were doing prescheduled, 7x24, stand-alone mainframe testing and mentioned that they had tried MVS, but it had 15min MBTF (in that environment), requiring manual re-ipl. I offer to rewrite I/O supervisor making it bullet-proof and never fail ... allowing any amount of ondemand, concurrent testing ... greatly improving productivity. I write an internal research report on the I/O Integrity work and happen to mention the MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
Bldg15 then gets the first engineering 3033 outside POK processor engineering and find testing only takes a percent or two of CPU, so we scrounge up 3830 controller and 3330 string to setup our own private online service. An engineering 4341 (4331/4341 follow-on to 138/148) arrives summer 1978 (not delivered to customers until following summer). Somehow branch office finds out and Jan1979 cons me into doing benchmarks for national lab looking at getting 70 for a compute farm (sort of leading edge of the coming cluster supercomputing tsunami). Also find a five system cluster of 4341s, is much less expensive than 3033, higher throughput, smaller floor space, less power&cooling. In early 80s, find large corporations making orders for hundreds of VM/4341s at a time, for deployment out in departmental areas (sort of the leading edge of the departmental computing tsunami; inside IBM, conference rooms were becoming scarce as they were converted to VM/4341 rooms).
side-note: early last decade, I was asked to track down decision to add virtual memory to all 370s. I found staff member to executive making the decision; basically MVT storage management was so bad that region sizes had to be specified four times larger than used, a typical 1mbyte 370/165 only ran four concurrent regions, insufficient to keep system busy and justified. Running MVT in 16mbyte virtual address space (sort of like running MVT in CP67 16mbyte virtual machine) allowed number of regions to be increased by factor of four (capped at 15 because of 4bit storage protect keys) with little or no paging. I would drop by Ludlow periodically who was doing initial work for VS2/SVS on 360/67, a little bit of code to bring MVT up in 16mbye virtual address space and some simple paging. The biggest issue was now EXCP/SVC0 was being called with channel programs that had virtual addresses (and channels required real addresses) and EXCP had to make channel program copies replacing virtual addresses with real. He borrows CP67 CCWTRANS (that did the same function) for crafting into EXCP.
360/370 microcode posts
https://www.garlic.com/~lynn/submain.html#360mcode
posts mentioning getting to play disk engineer
https://www.garlic.com/~lynn/subtopic.html#disk
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM SNA Date: 20 Feb, 2026 Blog: Facebookre:
70s, 3272 controller & 3277 terminal, channel attached had .086sec hardware response. Early 80s, 3274 controller & 3278 terminal ... lots of terminal hardware was moved back into shared 3274 controller (reducing 3278 manufacturing cost), significantly driving up coax protocol & latency ... to .3secs-.5secs hardware response depending on amount of data. Papers published during this period show less than quarter second response improved productivity. Letters to 3278 product manager complaining got back reply that 3278 wasn't intended for interactive computing but data entry.
At the time, my internal systems were getting .11sec interactive system response plus the 3272/3278 .086 hardware response was still within interactive (.196sec). MVS/TSO hardly noticed the 3278 change ... since they rarely saw even 1sec system response.
recent posts mentioning 3270 interactive response
https://www.garlic.com/~lynn/2026.html#9 IBM Terminals
https://www.garlic.com/~lynn/2025d.html#102 Rapid Response
https://www.garlic.com/~lynn/2025c.html#47 IBM 3270 Terminals
https://www.garlic.com/~lynn/2025b.html#47 IBM Datacenters
https://www.garlic.com/~lynn/2025.html#127 3270 Controllers and Terminals
https://www.garlic.com/~lynn/2025.html#75 IBM Mainframe Terminals
https://www.garlic.com/~lynn/2025.html#69 old pharts, Multics vs Unix
https://www.garlic.com/~lynn/2024f.html#12 3270 Terminals
https://www.garlic.com/~lynn/2024e.html#26 VMNETMAP
https://www.garlic.com/~lynn/2024d.html#13 MVS/ISPF Editor
https://www.garlic.com/~lynn/2024c.html#19 IBM Millicode
https://www.garlic.com/~lynn/2024b.html#31 HONE, Performance Predictor, and Configurators
https://www.garlic.com/~lynn/2023g.html#70 MVS/TSO and VM370/CMS Interactive Response
https://www.garlic.com/~lynn/2023e.html#0 3270
https://www.garlic.com/~lynn/2023c.html#42 VM/370 3270 Terminal
https://www.garlic.com/~lynn/2022c.html#68 IBM Mainframe market was Re: Approximate reciprocals
https://www.garlic.com/~lynn/2022b.html#123 System Response
https://www.garlic.com/~lynn/2022b.html#110 IBM 4341 & 3270
https://www.garlic.com/~lynn/2021.html#84 3272/3277 interactive computing
https://www.garlic.com/~lynn/2017d.html#25 ARM Cortex A53 64 bit
https://www.garlic.com/~lynn/2016e.html#51 How the internet was invented
https://www.garlic.com/~lynn/2014h.html#106 TSO Test does not support 65-bit debugging?
https://www.garlic.com/~lynn/2014g.html#26 Fifty Years of BASIC, the Programming Language That Made Computers Personal
https://www.garlic.com/~lynn/2014g.html#23 Three Reasons the Mainframe is in Trouble
https://www.garlic.com/~lynn/2013g.html#14 Tech Time Warp of the Week: The 50-Pound Portable PC, 1977
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 135/145, 138/148, 4331/4341 Date: 21 Feb, 2026 Blog: Facebookre:
When CSC gets copy of the 370 architecture "red book" (packaged in red 3-ring binder, 1st main stream IBM pub done in CMS SCRIPT/GML, command line option that either produces the full architecture "red book" or the principle of operations subset), starts effort to add 370 virtual memory architecture virtual machine option to CP/67 (simulating 370 architecture rather than just 360 architecture) and a modification of CP/67 to run 370 architecture. This was in regular production use a year before the 1st engineering 370/145 with virtual memory support was operational ... in fact 370 virtual memory CP/67 was used as initial test for the engineering virtual memory 370/145.
CP/67L running on real 360/67 .. CP/67H running in 360/67 virtual machine, supporting 370 virtual machine .... CP/67I running in 370 virtual memory, virtual machine
Extra security layer was because CSC production CP/67 had profs, staff, and students from Boston area institutions using CSC (CP67L) system and 370 virtual memory hadn't been announced yet.
Then three people from San Jose come out and add 2305 and 3330 device support to CP/67I producing CP/67SJ ... which was in production use on internal virtual memory 370s (long after VM370 was operational).
The morph of CP67->VM370 simplified and dropped features. Then for VM370R2-base, I start adding CP67 features back in for my internal CSC/VM (including kernel re-org for multiprocessor support, but not actual multiprocessor). Then for VM370R3-base CSC/VM, I add full multiprocessor support, initially for the internal sales&marketing support online HONE systems, so they can upgrade their 158s&168s to 2-CPU (getting twice throughput of 1-CPU).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
CP67L, CSC/VM, SJRVM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
SMP, tightly-coupled, shared-memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
posts mentioning 370 architecture "red book"
https://www.garlic.com/~lynn/2024g.html#108 IBM 370 Virtual Storage
https://www.garlic.com/~lynn/2024g.html#67 HTTP Error 522 and OS/360 Error 222
https://www.garlic.com/~lynn/2024f.html#29 IBM 370 Virtual memory
https://www.garlic.com/~lynn/2024e.html#99 PROFS, SCRIPT, GML, Internal Network
https://www.garlic.com/~lynn/2024.html#59 RUNOFF, SCRIPT, GML, SGML, HTML
https://www.garlic.com/~lynn/2023.html#70 GML, SGML, & HTML
https://www.garlic.com/~lynn/2023.html#24 IBM Punch Cards
https://www.garlic.com/~lynn/2023.html#5 1403 printer
https://www.garlic.com/~lynn/2022h.html#68 Fred P. Brooks, 1931-2022
https://www.garlic.com/~lynn/2022c.html#99 IBM Bookmaster, GML, SGML, HTML
https://www.garlic.com/~lynn/2022c.html#8 Cloud Timesharing
https://www.garlic.com/~lynn/2022b.html#92 Computer BUNCH
https://www.garlic.com/~lynn/2022b.html#51 IBM History
https://www.garlic.com/~lynn/2014h.html#60 The Tragedy of Rapid Evolution?
https://www.garlic.com/~lynn/2014e.html#3 IBM PCjr STRIPPED BARE: We tear down the machine Big Blue wouldrather you f
https://www.garlic.com/~lynn/2013c.html#21 What Makes an Architecture Bizarre?
https://www.garlic.com/~lynn/2012l.html#73 PDP-10 system calls, was 1132 printer history
https://www.garlic.com/~lynn/2012l.html#24 "execs" or "scripts"
https://www.garlic.com/~lynn/2012l.html#23 PDP-10 system calls, was 1132 printer history
https://www.garlic.com/~lynn/2012e.html#59 Word Length
https://www.garlic.com/~lynn/2012.html#64 Has anyone successfully migrated off mainframes?
https://www.garlic.com/~lynn/2011e.html#86 The first personal computer (PC)
https://www.garlic.com/~lynn/2010p.html#18 Rare Apple I computer sells for $216,000 in London
https://www.garlic.com/~lynn/2010k.html#41 Unix systems and Serialization mechanism
https://www.garlic.com/~lynn/2005p.html#45 HASP/ASP JES/JES2/JES3
https://www.garlic.com/~lynn/2005k.html#58 Book on computer architecture for beginners
https://www.garlic.com/~lynn/2004p.html#50 IBM 3614 and 3624 ATM's
https://www.garlic.com/~lynn/2004b.html#57 PLO instruction
https://www.garlic.com/~lynn/2002h.html#21 PowerPC Mainframe
https://www.garlic.com/~lynn/2002b.html#48 ... the need for a Museum of Computer Software
https://www.garlic.com/~lynn/2001m.html#39 serialization from the 370 architecture "red-book"
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Pagesat Satellite USENET Date: 21 Feb, 2026 Blog: Facebookstill do sporadic usenet posting. after leaving IBM did some work for PAGESAT ... unix and windows drivers for their satellite modem and a boardwatch article ... in return got full/free usenet satellite feed ... pg51-59
past posts mentioning pagesat
https://www.garlic.com/~lynn/2024f.html#117 NETSYS Internet Service Provider
https://www.garlic.com/~lynn/2023e.html#58 USENET, the OG social network, rises again like a text-only phoenix
https://www.garlic.com/~lynn/2022g.html#77 RS/6000 (and some mainframe)
https://www.garlic.com/~lynn/2022b.html#7 USENET still around
https://www.garlic.com/~lynn/2022.html#11 Home Computers
https://www.garlic.com/~lynn/2021i.html#99 SUSE Reviving Usenet
https://www.garlic.com/~lynn/2018e.html#55 usenet history, was 1958 Crisis in education
https://www.garlic.com/~lynn/2018e.html#51 usenet history, was 1958 Crisis in education
https://www.garlic.com/~lynn/2017h.html#118 AOL
https://www.garlic.com/~lynn/2017h.html#110 private thread drift--Re: Demolishing the Tile Turtle
https://www.garlic.com/~lynn/2017b.html#21 Pre-internet email and usenet (was Re: How to choose the best news server for this newsgroup in 40tude Dialog?)
https://www.garlic.com/~lynn/2016g.html#59 The Forgotten World of BBS Door Games - Slideshow from PCMag.com
https://www.garlic.com/~lynn/2015h.html#109 25 Years: How the Web began
https://www.garlic.com/~lynn/2015d.html#57 email security re: hotmail.com
https://www.garlic.com/~lynn/2013l.html#26 Anyone here run UUCP?
https://www.garlic.com/~lynn/2012b.html#92 The PC industry is heading for collapse
https://www.garlic.com/~lynn/2010g.html#70 What is the protocal for GMT offset in SMTP (e-mail) header
https://www.garlic.com/~lynn/2009l.html#21 Disksize history question
https://www.garlic.com/~lynn/2009j.html#19 Another one bites the dust
https://www.garlic.com/~lynn/2006m.html#11 An Out-of-the-Main Activity
https://www.garlic.com/~lynn/2005l.html#20 Newsgroups (Was Another OS/390 to z/OS 1.4 migration
https://www.garlic.com/~lynn/2001h.html#66 UUCP email
https://www.garlic.com/~lynn/2000e.html#39 I'll Be! Al Gore DID Invent the Internet After All ! NOT
https://www.garlic.com/~lynn/aepay4.htm#miscdns misc. other DNS
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM CMS Applications Date: 21 Feb, 2026 Blog: Facebookre:
re: distribution list, prior to the update/enhancement to RSCS/VNET, for multiple recipients, a separate copy had to be sent to each one. Friday's after work we had discussions about things that could get employees to use online (vm370) computers and came up with online telephone books (Jim Gray would take one week to do lookup and I would take one week to do data collection and formatting). That started with regular update distribution to locations around the world. The change for RSCS/VNET was initially motivated for telephone book distribution (at one point accounted for majority of traffic on internal network) ... supported a header distribution list ... and would forward only a single copy to the next location (rather than one for every recipient).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network
https://www.garlic.com/~lynn/subnetwork.html#internalnet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Cloud Megadatacenters Date: 21 Feb, 2026 Blog: Facebooknot long after turn of century, large cloud operations were saying they had been assembling their own server blades for 1/3rd the cost of brand name server blades. decade or so later, industry press had articles that makers of server blade components were shipping at least 50% of the product directly to large cloud operations ... and IBM sells off its server blade business. There was also industry articles that server blade component makers were doing custom designed components for their large cloud customers.
Large cloud operations can have a score or more megadatacenters around the world, each with half million or more server blades (with enormous automation, a megadatacenter might have staff of only 70-80). They had enormously cost reduced their server blade systems, megadatacenter power&cooling costs was increasingly becoming major factor ... and they were heavily pressuring component makers to highly optimize power&cooling efficiency.
Other articles were large cloud operations supported being able to use a credit card and spin-up a cluster supercomputer (that for a few hours would rank in the top 40 supercomputer in the world).
megadatacenter posts
https://www.garlic.com/~lynn/submisc.html#megadatacenter
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM CSC, IBM Unbundle, IBM HONE, IBM System/R, SCI, FCS, IBM HA/CMP Date: 22 Feb, 2026 Blog: FacebookAfter graduating and joined the IBM science center, one of my hobbies was enhanced production operating systems for internal datacenters, one of the 1st and long time customer was the sales and marketing support HONE systems. 23jun1969 unbundling included starting to charge for SE services. Up until then novice/trainee SEs were part of group on-site at customers ... but with unbundling, couldn't figure out how to not charge for trainee SE services. Multiple HONE CP67 (virtual machine) datacenters were setup around the US with online access from branches where SEs would practice with guest operating systems in virtual machines. The science center also had redone APL\360 from 16kbyte swapped workspaces to large virtual memory demand page and APIs for system services (like file I/O), as CMS\APL for real world applications. HONE then started using CMS\APL for delivering sales&marketing support applications, which came to dominate all HONE activity (and SE working w/guest operating systems just withered away), w/HONE systems sprouting up all over the world.
1988, branch office asks if I could help SLAC/Gustavson with SCI
standard (various uses including shared memory multiprocessor, up to
64 cache consistency, some efforts Data General and Sequent 64 4-i486
boards (256 processors), Convex 64 2-HP-snake boards (128 processor),
SGI 64 4-MIPS boards, etc),
https://en.wikipedia.org/wiki/Scalable_Coherent_Interface
https://www.scizzl.com/SGIarguesForSCI.html
about same time branch office also asked if I could help LLNL
(national lab) with fibre-channel standard ("FCS", initial 1gbit
transfer, full-duplex, aggregate 200mbyte/sec)
https://en.wikipedia.org/wiki/Fibre_Channel
Then POK announce their stuff in the 90s as ESCON (when it was already
obsolete), initially 10mbytes/sec, upgraded to 17mbytes/sec. Then some
POK engineers become involved with "FCS" and define a heavy-weight FCS
protocol that drastically cuts native throughput, eventually ships as
FICON. Around 2010 was a max configured z196 public "Peak I/O"
benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the
same time, a "FCS" was announced for E5-2600 server blade claiming
over million IOPS (two such FCS with higher throughput than 104 FICON,
running over FCS). Note IBM docs has SAP (system assist processors
that do actual I/O) CPUs be kept to 70% ... or 1.5M IOPS ... also no
CKD DASD have been made for decades (just simulated on industry
fixed-block devices). Industry benchmark, number of program iterations
compared to industry MIPS/BIPS standard platform:
2010 max configured z196: 50BIPS, 80cores, 625MIPS/core
2010 E5-2600 server blade, two 8-core chips, 500BIPS, 31BIPS/core
also 1988, Nick Donofrio approves HA/6000, initially for NYTimes to
move their newspaper system (ATEX) off DEC VAXCluster to RS/6000, I
rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up with RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster support in same source base with UNIX (trivia: 2nd half of 70s, when I transferred to SJR on the west coast, I worked with Jim Gray and Vera Watson on the original SQL/relational, System/R ... had been developed on VM/370 ... while corporation was preoccupied with the next great DBMS, EAGLE ... was able to do tech (under the radar) transfer to Endicott for SQL/DS ... then when EAGLE implodes was asked how fast could System/R be ported to MVS, eventually announced as "DB2" originally for decision-support *ONLY*).
Early Jan92, there was HA/CMP meeting with Oracle CEO and IBM/AWD
executive Hester tells Ellison that we would have 16-system clusters
by mid92 and 128-system clusters by ye92. Mid-jan92, I update FSD on
HA/CMP work with national labs and FSD decides to go with HA/CMP for
federal supercomputers. By end of Jan, we are told that cluster
scale-up is being transferred to Kingston for announce as IBM
Supercomputer (technical/scientific *ONLY*) and we aren't allowed to
work with anything that has more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS,
... 128-systems: 16BIPS
After leaving IBM, I do some consulting for Steve Chen who was then
CTO at Sequent (before IBM buys Sequent and shuts it down).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
IBM 23jun11969 unbundling
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
FCS and/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
Original SQL/relational posts
https://www.garlic.com/~lynn/submain.html#systemr
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
some recent posts mentioning SCI
https://www.garlic.com/~lynn/2026.html#54 IBM Supercomputer
https://www.garlic.com/~lynn/2025c.html#24 IBM AIX
https://www.garlic.com/~lynn/2025c.html#16 Cluster Supercomputing
https://www.garlic.com/~lynn/2024g.html#85 IBM S/38
https://www.garlic.com/~lynn/2024e.html#90 Mainframe Processor and I/O
https://www.garlic.com/~lynn/2024.html#37 RS/6000 Mainframe
https://www.garlic.com/~lynn/2023g.html#106 Shared Memory Feature
https://www.garlic.com/~lynn/2023g.html#16 370/125 VM/370
https://www.garlic.com/~lynn/2023e.html#78 microcomputers, minicomputers, mainframes, supercomputers
https://www.garlic.com/~lynn/2022g.html#91 Stanford SLAC (and BAYBUNCH)
https://www.garlic.com/~lynn/2022f.html#29 IBM Power: The Servers that Apple Should Have Created
https://www.garlic.com/~lynn/2022b.html#67 David Boggs, Co-Inventor of Ethernet, Dies at 71
https://www.garlic.com/~lynn/2022.html#118 GM C4 and IBM HA/CMP
https://www.garlic.com/~lynn/2022.html#95 Latency and Throughput
https://www.garlic.com/~lynn/2021i.html#16 A brief overview of IBM's new 7 nm Telum mainframe CPU
https://www.garlic.com/~lynn/2021h.html#45 OoO S/360 descendants
https://www.garlic.com/~lynn/2021b.html#44 HA/CMP Marketing
https://www.garlic.com/~lynn/2019d.html#81 Where do byte orders come from, Nova vs PDP-11
https://www.garlic.com/~lynn/2019c.html#53 IBM NUMBERS BIPOLAR'S DAYS WITH G5 CMOS MAINFRAMES
https://www.garlic.com/~lynn/2019.html#32 Cluster Systems
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Early Mainframe work Date: 23 Feb, 2026 Blog: FacebookI had taken two credit hr intro to fortran/computers and at end of semester was hired to rewrite 1401 MPIO in 360 assembler for 360/30. The univ was getting 360/67 for TSS/360 replacing 709/1401 and got a 360/30 temporarily pending 360/67s. Univ. shutdown datacenter on weekends and I got the whole place (although 48hrs w/o sleep made Monday classes hard). They gave me a pile of hardware and software manuals and I got to design and implement my own monitor, device drivers, interrupt handlers, error recovery/retry, storage management, etc and within a few weeks had 2000 card assembler program). I quickly learned first thing Sat. morning, to clean tape drives and printers, disassemble/clean/reassemble 2540 reader/punch. Sometimes production had finished early and all power was off when I show up. I had to power everything back on ... sometimes wouldn't come back up; lots of manuals and trial&error to learn to get things back powered on. Within year of intro class, the 360/67 arrived and I was hired fulltime responsible for OS/360 (TSS/360 never came to fruition).
Student fortran ran less than second on 709. Initially on 360/67 OS/360, student fortran ran over minute. I install HASP, cutting time in half. Then start redoing SYSGEN STAGE2, carefully placing datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9sec. 360/67 never got better than 709 until I install UofWaterloo WATFOR (360 65&67 clocked WATFOR at 20,000 statements/minute; 333/sec; student fortran tended to run 30-60 cards).
Then CSC came out to install (virtual machine) CP/67 (3rd after CSC itself and MIT Lincoln Labs) and I mostly get to play with it during my weekend 48hr window. I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher/scheduler , (dynamic adaptive resource manager/default fair share scheduling policy), paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial CP/67 install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support and auto-terminal ident,
capable switching terminal type scanner type for each port. Univ. also
had TTY33&35 and I add ASCII support integrated with auto-terminal
type. I then want to have single dial-in number (hunt group) for all
terminals. Didn't quite work, IBM had hard-wired line speed ... so we
start a clone terminal controller. Build a IBM channel interface board
for Interdata/3 programmed to emulate IBM controller with the addition
for auto-baud. Then upgrading with Interdata/4 for channel interface
and cluster of Interdata/3s for port interfaces. Interdata (and later
Perkin-Elmer) sell them as clone controllers.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
... and four of us are written up responsible for (some part of) clone
controller business
Before I graduate, I'm hired fulltime into a small group in the Boeing CFO office to help with the formation of Boeing Computer Services, consolidate all dataprocessing into independent business unit (at the time, 747-3 was flying skies of Seattle getting FAA flt certification). I think Renton datacenter possibly largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in the hallways around the machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing Field for payroll, although they enlarge the room to install a 360/67 for me to play with when I wasn't busy with other stuff. When I graduate, I join CSC instead of staying with the Boeing CFO.
A decade later, I want to show REX (before renamed and released to customers) wasn't just another pretty scripting language and plan to re-implement the large assembler dump/problem analysis, taking less than 3months working half time, with ten times the function and ten times the performance (hack to make interpreted language running faster than assembly). I finish early and so add library of automatic search for common failure/problem signatures. I figured it would be released to customers, but for whatever reason it wasn't, even though it was in use by just about every internal datacenter and IBM PSR. I eventually get permission to give talks on how it was implemented at customer user group meetings ... and before not too long, similar implementations started to appear.
recent comments on some additional work
https://www.garlic.com/~lynn/2026.html#66 IBM CSC, IBM Unbundle, IBM HONE, IBM System/R, SCI, FCS, IBM HA/CMP
https://www.garlic.com/~lynn/2026.html#54 IBM Supercomputer
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
360 clone controller posts
https://www.garlic.com/~lynn/submain.html#360pcm
DUMPRX posts
https://www.garlic.com/~lynn/submain.html#dumprx
recent posts mentioning undergraduate work at univ & boeing
https://www.garlic.com/~lynn/2026.html#28 360 Channel
https://www.garlic.com/~lynn/2025e.html#104 Early Mainframe Work
https://www.garlic.com/~lynn/2025e.html#3 Switching On A VAX
https://www.garlic.com/~lynn/2025d.html#99 IBM Fortran
https://www.garlic.com/~lynn/2025.html#111 Computers, Online, And Internet Long Time Ago
https://www.garlic.com/~lynn/2024d.html#103 IBM 360/40, 360/50, 360/65, 360/67, 360/75
https://www.garlic.com/~lynn/2024b.html#97 IBM 360 Announce 7Apr1964
https://www.garlic.com/~lynn/2024b.html#63 Computers and Boyd
https://www.garlic.com/~lynn/2024b.html#60 Vintage Selectric
https://www.garlic.com/~lynn/2024b.html#44 Mainframe Career
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Adirondack Date: 24 Feb, 2026 Blog: Facebookfrom long ago and far away ...
First half of 70s, the "Future System" effort was completely different
from 370 and was going to completely replace 370. During FS, internal
politics was killing off 370 efforts and lack of new 370 during FS is
credited with giving the clone 370 makers their market foothold.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
when FS finally implodes, there is mad rush to get stuff back into 370 product pipelines, including kicking off quick&dirty 3033&3081 efforts (I had been periodically ridiculing FS, which wasn't exactly career enhancing).
from "Computer Wars: The Post-IBM World"
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
I also get talked into working on 16-CPU 370, and we con the 3033 processor engineers into working on it in their spare time (a lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (existing MVS documentation was that simple 2-CPU support only got 1.2-1.5 times the throughput of 1-CPU; POK doesn't ship a 16-CPU system until after the turn of the century). The head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, heads down and no distractions. Once the 3033 was out the door, the 3033 processor engineers start on trout/3090 (they would have me sneak back into POK for processor engineers periodic bike rides).
I then transfer out to SJR on west coast and got to wander around datacenters in Silicon Valley, including disk bldg14/engineering and bldg15/product testing across the street. They were running 7x24, prescheduled, stand-alone testing, also mentioned that they had recently tried MVS, but it had 15min MTBF (in that environment). I offer to rewrite I/O Supervisor to make it bullet proof and never fail, allowing any amount of on-demand, concurrent testing, greatly improving productivity. Then bldg. 15 gets engineering 3033, 1st outside POK 3033 processor engineering. Product testing was only taking a percent or two of 3033 CPU, so we scrounge up 3830 controller and 3330 string and setup our own private, online service. I then write an internal research report on I/O Integrity and happen to mention MVS 15min MTBF, bringing down the wrath of the MVS organization on my head.
Late 70s and early 80s I had been blamed for online computer
conferencing on the internal network, but it didn't really take-off
until spring of 1981 when I distributed a trip report to see Jim Gray
at Tandem (who had left SJR fall 1980 for Tandem). Only about 300
directly participated but claims that 25,000 were reading. From
IBMJargon:
https://havantcivicsociety.uk/wp-content/uploads/2019/05/ibmjarg.pdf
Tandem Memos - n. Something constructive but hard to control; a fresh
of breath air (sic). That's another Tandem Memos. A phrase to worry
middle management. It refers to the computer-based conference (widely
distributed in 1981) in which many technical personnel expressed
dissatisfaction with the tools available to them at that time, and
also constructively criticized the way products were [are]
developed. The memos are required reading for anyone with a serious
interest in quality products. If you have not seen the memos, try
reading the November 1981 Datamation summary.
... snip ...
--- six copies of 300 page extraction from the memos were printed and
packaged in Tandem 3ring binders, sending to each member of the
executive committee, along with executive summary and executive
summary of the executive summary (folklore was 5of6 corporate
executive committee wanted to fire me). From summary of summary:
• The perception of many technical people in IBM is that the company is
rapidly heading for disaster. Furthermore, people fear that this
movement will not be appreciated until it begins more directly to
affect revenue, at which point recovery may be impossible
• Many technical people are extremely frustrated with their management
and with the way things are going in IBM. To an increasing extent,
people are reacting to this by leaving IBM. Most of the contributors
to the present discussion would prefer to stay with IBM and see the
problems rectified. However, there is increasing skepticism that
correction is possible or likely, given the apparent lack of
commitment by management to take action
• There is a widespread perception that IBM management has failed to
understand how to manage technical people and high-technology
development in an extremely competitive environment
... snip ...
There were IBM task forces to look at online computer conferencing resulting in official IBM forum software and approved, moderated forum discussions. Also a researcher was paid to study how I communicated; sat in the back of my office for nine months taking notes on how I communicated, also got copies of all my incoming and outgoing email and logs of all instant messages. The result was used for IBM research reports, conference talks and papers, books and Stanford Phd (joint with language and computer AI, Winograd was advisor on computer AI side).
Early 80s, I had been introduced to John Boyd and would sponsor his briefings at IBM. 1989/1990, the Marine Corps Commandant leverages John for a corps make-over (at a time when IBM was desperately in need of make-over). After turn of century, we continued to have Boyd conferences at Quantico MCU.
1992, IBM has one of the largest losses in the history of US companies
and was being reorganized into the 13 "baby blues" in preparation for
breaking up the company ("baby blues" take off on "baby bell" breakup
a decade earlier).
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
demise of disk division and communication group stranglehold posts
https://www.garlic.com/~lynn/subnetwork.html#emulation
John Boyd posts and web URLs
https://www.garlic.com/~lynn/subboyd.html
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM System/R, SCI, FCS, IBM HA/CMP Date: 24 Feb, 2026 Blog: Facebook1988, branch office asks if I could help SLAC/Gustavson with SCI standard, various uses including shared memory multiprocessor, up to 64 cache consistency, some efforts Data General and Sequent 64 4-i486 boards (256 processors), Convex 64 2-HP-snake boards (128 processor), etc,
about same time (1988) branch office also asked if I could help LLNL
(national lab) with fibre-channel standard ("FCS", initial 1gbit
transfer, full-duplex, aggregate 200mbyte/sec)
https://en.wikipedia.org/wiki/Fibre_Channel
Then POK announce their stuff in the 90s as ESCON (when it was already
obsolete), initially 10mbytes/sec, upgraded to 17mbytes/sec. Then some
POK engineers become involved with "FCS" and define a heavy-weight FCS
protocol that drastically cuts native throughput, eventually ships as
FICON. Around 2010 was a max configured z196 public "Peak I/O"
benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the
same time, a "FCS" was announced for E5-2600 server blade claiming
over million IOPS (two such FCS with higher throughput than 104 FICON,
running over FCS). Note IBM docs has SAP (system assist processors
that do actual I/O) CPUs be kept to 70% ... or 1.5M IOPS ... also no
CKD DASD have been made for decades (just simulated on industry
fixed-block devices). Industry benchmark, number of program iterations
compared to industry MIPS/BIPS standard platform:
2010 max configured z196: 50BIPS, 80cores, 625MIPS/core
2010 E5-2600 server blade, two 8-core chips, 500BIPS, 31BIPS/core
also 1988, Nick Donofrio approves HA/6000, initially for NYTimes to
move their newspaper system (ATEX) off DEC VAXCluster to RS/6000, I
rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up with
RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster
support in same source base with UNIX. trivia: 2nd half of 70s, when I
transferred to SJR on the west coast, I worked with Jim Gray and Vera
Watson on the original SQL/relational, System/R ... had been developed
on VM/370 ... while corporation was preoccupied with the next great
DBMS, EAGLE ... was able to do tech transfer (under the radar) to
Endicott for SQL/DS ... then when EAGLE implodes was asked how fast
could System/R be ported to MVS, eventually announced as "DB2"
originally for decision-support *ONLY*.
IBM S/88 (relogo'ed Stratus) Product Administrator started taking us around to their customers and also had me write a section for the corporate continuous availability document (it gets pulled when both AS400/Rochester and mainframe/POK complain they couldn't meet requirements). Had coined disaster survivability and geographic survivability (as counter to disaster/recovery) when out marketing HA/CMP. One of the visits to 1-800 bellcore development showed that S/88 would use a century of downtime in one software upgrade, while HA/CMP had a couple extra "nines" (compared to S/88).
One of the first customer installs was new Indian Reservation Casino
in Connecticut, was suppose to have week of testing before opening
... but after 24hrs, they decided to open the doors (based on
projected revenue; at the time was largest in the US, still one of the
largest in the country)
https://en.wikipedia.org/wiki/Foxwoods_Resort_Casino#Debt_default
Early Jan92, there was HA/CMP meeting with Oracle CEO and IBM/AWD
executive Hester tells Ellison that we would have 16-system clusters
by mid92 and 128-system clusters by ye92. Mid-jan92, I update FSD on
HA/CMP work with national labs and FSD decides to go with HA/CMP for
federal supercomputers. By end of Jan, we are told that cluster
scale-up is being transferred to Kingston for announce as IBM
Supercomputer (technical/scientific *ONLY*) and we aren't allowed to
work with anything that has more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS,
... 128-systems: 16BIPS
After leaving IBM, I do some consulting for Steve Chen who was then
CTO at Sequent (before IBM buys Sequent and shuts it down).
An executive we reported to, went over to head up Somerset/AIM (Apple,
IBM, Motorola) doing a single chip processor for Power/PC... and used
Motorola 88K bus&cache (enabling shared memory multiprocessor
configurations). Then mid-90s, i86 makers do hardware layer that
translate i86 instructions into RISC micro-ops for actual execution
(largely negating throughput difference between RISC and i86); 1999
industry benchmark:
IBM PowerPC 440: 1,000MIPS
Pentium3: 2,054MIPS (twice PowerPC 440)
801/risc, iliad, romp, rios, pc/rt, rs/6000, power, power/pc posts
https://www.garlic.com/~lynn/subtopic.html#801
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
original SQL/relational, System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
some past posts mentioning HA/CMP & Foxwoods
https://www.garlic.com/~lynn/2021b.html#31 Indian Casino and HA/CMP
https://www.garlic.com/~lynn/2018c.html#72 Indian Casino and HA/CMP
https://www.garlic.com/~lynn/2010p.html#62 TCM's Moguls documentary series
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Re: Idly Browsing The fortunes/computers file ... Newsgroups: alt.folklore.computers Date: Tue, 24 Feb 2026 15:21:48 -1000Lawrence D'Oliveiro <ldo@nz.invalid> writes:
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
IBM CEO & former AMXEX president
https://www.garlic.com/~lynn/submisc.html#gerstner
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 3033 Date: 26 Feb, 2026 Blog: FacebookAmdahl won the battle to make ACS, 360 compatible ... but then when ACS/360 is killed (folklore it would advance state-of-art too fast and IBM would loose control of the market) and Amdahl leaves IBM to form his own company.
After graduating and joining IBM Cambridge Scientific Center, I was allowed to continue stopping by customers and attending user group meetings ... and one of my hobbies was enhanced production operating systems and one of my 1st and long time customers was the online sales&marketing support HONE systems. Also director of one of the largest east coast financial industry datacenters liked me to stop by and talk technology. At some point the IBM branch manager horribly offended the customer and in retribution, they ordered a single Amdahl machine; up until then Amdahl had been selling into technology, scientific, univ markets and this would be the 1st, true-blue commercial customer. IBM asked me to go live onsite at the customer for 6-12months (to obfuscate the Amdahl customer order). I talk it over with the customer and decide to decline IBM offer. I was then told that the IBM branch manager was good sailing buddy of IBM CEO and if I don't, I can forget career, promotion, raises.
Future System
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
Completely different & was to completely replace 370, during FS internal politics was killing off 370 efforts and the lack of new 370 products during FS is credited with giving clone 370 makers (including Amdahl) their market foothold. One of the last nails in the FS coffin was analysis by the IBM Houston Scientific Center showing that if 370/195 apps were redone for FS machine made out of the fastest technology available, it would have throughput of 370/145 (about 30 times slowdown). I continued to work on 360/370 all during FS, including periodically ridiculing what they were doing, drawing analogy with long playing cult film down at central sq (not exactly career enhancing).
Future System from: Computer Wars: The Post-IBM World
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and
*MAKE NO WAVES* under Opel and Akers. It's claimed that
thereafter, IBM lived in the shadow of defeat ... But because of the
heavy investment of face by the top management, F/S took years to
kill, although its wrong headedness was obvious from the very
outset. "For the first time, during F/S, outspoken criticism became
politically dangerous," recalls a former top executive
... snip ...
When FS finally implodes, there is mad rush to get stuff back into the 370 product pipelines, including quick&dirty 3033&3081 efforts. 3033 started out remapping 168 logic to 20% faster chips. Note 165 microcode took an avg of 2.1 processor cycles per 370 instruction. This was improved for 168 to 1.6 processor cycles per 370 instruction and then improved again for 3033 to avg of one processor cycle per 370 instruction (3033 about 1.5 times MIP rate of 168-3)
The 303x channel director was 158 engine with just the integrated channel microcode (and no 370 microcode). A 3031 was two 158 engines, one with channel microcde and one with 370 microcode. A 3032 was 168 reworked to use channel director for external channels. A 3033 could have up to three channel directors.
With implosion of FS, Endicott talks me into helping with 138/148 microcode assist (ECPS). I was also talked into helping with 16-CPU 370 and we con the 3033 processor engineers into working on it in their spare time (lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-CPU support (IBM docs had MVS 2-CPU only getting 1.2-1.5 times throughput of 1-CPU, POK doesn't ship a 16-CPU system until after turn of century). Then head of POK invite some of us to never visit POK again and instructs 3033 processor engineers, heads down and no distractions.
I then transfer out to SJR and get to wander around datacenters in silicon valley, including disk bldg14/engineers and bldg5/product test, across the street. They were doing prescheduled, 7x24, stand-alone testing and mentioned that they had recently tried MVS, but it had 15min MTBF (in that environment) requiring manual re-ipl. I offer to rewrite I/O supervisor to make it bullet-proof and never fail, allowing any amount of on-demand, concurrent testing, greatly improving productivity. Bldg15 then gets the first engineering 3033 outside POK processor engineering. Testing only took a percent of testing so we scrounge up a 3830 controller and 3330 string and setup our own private online service. trivia: 303x channel directors were (still) periodically hanging, requiring manual reset and discover if I quickly hit all six channel addresses with CLRCH, the channel director would automagically re-IMPL. I then write an (internal) I/O Integrity research report and happen to mention MVS 15min MTBF, bringing the wrath of the MVS organization down on my head.
Note that the head of POK had also convinced corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA. They weren't planning on telling the people until the very last minute (to minimize the numbers that might escape into the Boston area). The information managed to leak early and some number managed to escape and there was search for the leak source (fortunately for me, the source wasn't given up). Endicott eventually manages to acquire the VM370 product mission for the mid-range, but had to recreate a development group from scratch. This was in the very early days of DEC VMS and there was joke that the head of POK was major contributor to VMS. Also IBM was under restrictions that machines had to ship in the same sequence as the orders. There is folklore that the 1st 3033 order was VM370 customer and it would be great loss of face for the head of POK (having convinced corporate to kill VM370, there is folklore that the 3033 moving vans left the shipping dock in the "correct" order, but they managed to fiddle the travel path and the MVS shipment arrived first).
Also once the 3033 was out the door, the 3033 processor engineers start on Trout/3090.
3081 was originally going to be multiprocessor only and the first box
shipped was 3081D 2-CPU and lower aggregate MIPS than Amdahl single
CPU. The processor cache sizes were doubled for the 3081K, bringing
aggregate MIPS about the same as Amdahl 1-CPU. However, 3081K MVS
multiprocessor overhead only got .6-.75 the throughput of MVS Amdahl
1-CPU (even though the same aggregate MIPS). more information
http://www.jfsowa.com/computer/memo125.htm
I eventually got permission to give presentations on how we did 138/148 (also used for 4331/4341) ECPS at user group meetings. Afterwards Amdahl people would grill me for more information. They told me they had done "MACROCODE" (370-like instructions running in microcode mode) to quickly respond to plethora of 3033 microcode features needed by MVS to run ... and they were then using it to implement "HYPERVISOR" (multiple domain). It was giving POK lots of problems because customers were tardy converting from MVS to MVS/XA (Amdahl was having more success because they could run MVS & MVS/XA concurrently on the same machine). IBM doesn't respond with LPAR & PR/SM until nearly decade later for the 3090 (in part because 3081 had limited microcode space and 3081 microcode had to be "paged").
Early last decade, I was asked to track down IBM decision to add virtual memory to all 370s. I found staff member to executive making decision. (basically MVT storage management was so bad that region sizes had to be specified four times larger than used and typical 1mbyte 370/165 only would run four concurrent regions, insufficient to keep 165 busy and justified. going to 16mbyte virtual address space (sort of like running MVT in CP67 16mbyte virtual machine), allowing concurrent regions to be increased by factor of four (capped at 15 because of 4bit storage protect keys) with little or no paging. This then spawned the CP67->VM370, which simplified or deleted many features (including "wheeler scheduler" and multiprocessor support). I start adding bunch of stuff back into VM370R2-base for my internal CSC/VM (including kernel re-org for multiprocessor support, but not the actual support). Then with a VM370R3-base, I add multiprocessor support, originally for HONE so they could move their 158s&168s to 2-CPU (getting twice throughput of 1-CPU, contributing to being asked to help with 16-CPU).
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
360/370 microcode posts
https://www.garlic.com/~lynn/submain.html#360mcode
SMP, tightly-coupled, shared memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 3033 Date: 26 Feb, 2026 Blog: Facebookre:
IBM 23jun1969 unbundling announce started to charge for (application) software, SE services, maint. etc. SE training use to be part of group onsite at customer ... with unbundling they couldn't figure how not to charge for trainee SEs. As a result, several "HONE" CP67 datacenters were created around the US so branch office people could logon and practice with guest operating systems running in virtual machines (after graduating and joining IBM CSC, one of my hobbies was enhanced production operating systems for internal datacenters and HONE was one of my 1st and long time customers).
CSC also redid APL\360 from 16kbyte swapped workspaces to large virtual memory demand paged workspaces and added APIs for system services like file I/O ... enabling lots of real world applications ... for CMS\APL. Then HONE started offering lots of online CMS\APL-based sales&marketing support applications ... which came to dominate all HONE activity (and virtual machine guest operating system practice just withered away). Then as HONE datacenters started to propagate all over the world, it became the largest use of APL in the world.
After head of POK had convinced corporate to kill VM370 ... they were sending executives around internal datacenters to strong arm switching from VM370 to MVS .... and HONE objected strongly, having had a effort that demonstrated that it wasn't possible. Somebody in POK then concluded it wasn't possible because HONE was running my enhanced (CSC/VM) systems
IBM 23jun1969 unbundling announce posts
https://www.garlic.com/~lynn/submain.html#unbundle
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 3033 Date: 27 Feb, 2026 Blog: Facebookre:
bldg15 also gets engineering 4341 summer 1978 (doesn't ship to customers until following summer), branch office finds out about it and jan1979 gets me to do benchmark for national lab that was looking at getting 70 for a compute farm ... sort of the leading edge of the coming cluster supercomputer tsunami. also find that small cluster of five 4341s is much less expensive than 3033, higher aggregate throughput, smaller footprint, less power and cooling.
I was also working with Jim Gray and Vera Watson on original SQL/relational, System/R (precursor to SQL/DS and DB2) ... and BofA had joint study for System/R and was getting 60 VM/4341s for distributed System/R at branches (in 80s, large corporations started ordering hundreds of VM/4341s at a time for distribution to departmental areas; inside IBM, departmental conference rooms became scarce having been converted to VM/4341 rooms, leading edge of the distributed computing tsunami).
National lab benchmark:
158 45.64sec
3031 37.03sec
4341 36.21sec
cdc6600 35.77sec
168-3 8.80sec
158 had some hardware as 3031, but 3031 370 benchmarked better than
straight 158 because 158 system processor was shared for 370 microcode
and integrated channel microcode (aka 3031 was two 158 engines, one
with just 370 microcode and one with just integrated channel
microcode). 4341 processor ran both 370 microcode and its own
integrated channel microcode (tweaking 4341 channel microcode enabled
4341 for testing 3880/3380 3mbyte/sec data streaming channels).
Decade later (1988), Nick Donofrio approves HA/6000, originally for
NYTimes to move their newspaper system (ATEX) off DEC VAXCluster to
RS/6000. I rename it HA/CMP (high-availability, cluster
multiprocessor)
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up with
RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster
support in same source base with UNIX. trivia: 2nd half of 70s, when I
transferred to SJR on the west coast, I worked with Jim Gray and Vera
Watson on the original SQL/relational, System/R ... had been developed
on VM/370 ... then while corporation was preoccupied with the next
great DBMS, EAGLE ... was able to do tech transfer (under the radar)
to Endicott for SQL/DS ... then EAGLE implodes and was asked how fast
could System/R be ported to MVS, eventually announced as "DB2"
originally for decision-support *ONLY*.
IBM S/88 (relogo'ed Stratus) Product Administrator started taking us around to their customers and also had me write a section for the corporate continuous availability document (it gets pulled when both AS400/Rochester and mainframe/POK complain they couldn't meet requirements). Had coined disaster survivability and geographic survivability (as counter to disaster/recovery) when out marketing HA/CMP. One of the visits to 1-800 bellcore development showed that S/88 would use a century of downtime in one software upgrade, while HA/CMP had a couple extra "nines" (compared to S/88).
One of the first customer installs was new Indian Reservation Casino
in Connecticut, was suppose to have week of testing before opening
... but after 24hrs, they decided to open the doors (based on
projected revenue; at the time was largest in the US, still one of the
largest in the country)
https://en.wikipedia.org/wiki/Foxwoods_Resort_Casino#Debt_default
Early Jan92, there was HA/CMP meeting with Oracle CEO and IBM/AWD
executive Hester tells Ellison that we would have 16-system clusters
by mid92 and 128-system clusters by ye92. Mid-jan92, I update FSD on
HA/CMP work with national labs and FSD decides to go with HA/CMP for
federal supercomputers. By end of Jan, we are told that cluster
scale-up is being transferred to Kingston for announce as IBM
Supercomputer (technical/scientific *ONLY*) and we aren't allowed to
work with anything that has more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, 51MIPS/CPU
RS6000/990 : (1-CPU) 126MIPS, 16-systems: 2BIPS,
.... 128-systems: 16BIPS
posts mentioning getting to play disk engineer
https://www.garlic.com/~lynn/subtopic.html#disk
posts mentioning getting to work on original SQL/relational
https://www.garlic.com/~lynn/submain.html#systemr
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 3033 Date: 28 Feb, 2026 Blog: Facebookre:
trivia: SJR did a 5-VM/4341 cluster using 3088 and could do cluster co-ordination operation in less than second elapsed time. The communication group told them they would never approve customer release unless they used SNA/VTAM ... which drove the (same) cluster coordination elapsed to 30sec.
My wife had been in the GBURG JES group and one of the catchers for
ASP/JES3. Then she was con'ed into going to POK responsible for
loosely-coupled architecture where she did Peer-coupled Shared Data
architecture. She didn't remain long because 1) sporadic battles with
communication group trying to force her into using SNA/VTAM, 2) little
uptake (until much later with SYSPLEX and Parallel SYSPLEX) except for
IMS hot-standby, she asked Vern Watts who he would ask to get
permission, he replies nobody, he will just tell them when its all
done
https://www.vcwatts.org/ibm_story.html
She also wanted some enhancements for Trotter/3088 and couldn't get anybody to agree.
other trivia; early 80s, got HSDT, T1 and faster computer links (both terrestrial and satellite) and battles with communication group (60s, IBM had 2701 that supported T1, 70s going into SNA and its various issues capped links at 56kbits/sec). For a time, I reported to same executive as author of AWP164 (which turns into APPN). I badgered him to come over and work on real networking since the SNA group would never appreciate him. When APPN was to be announce, SNA non-concurred and it took some time to rewrite the APPN announcement letter to not imply any relationship between SNA and APPN.
more trivia: HSDT was working with NSF director and was suppose to
get $20M to interconnect the NSF supercomputing centers. Then congress
cuts the budget, some other things happen and eventually an RFP is
released (in part based on what we already had running). NSF 28Mar1986
Preliminary Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
IBM internal politics was not allowing us to bid. The NSF director
tried to help by writing the company a letter (3Apr1986, NSF Director
to IBM Chief Scientist and IBM Senior VP and director of Research,
copying IBM CEO) with support from other gov. agencies ... but that
just made the internal politics worse (as did claims that what we
already had operational was at least 5yrs ahead of the winning bid),
as regional networks connect in, NSFnet becomes the NSFNET backbone,
precursor to modern internet.
Also at the time there was lots of internal network SNA/VTAM
misinformation (including converting the internal network to SNA/VTAM)
and there was similar misinformation about being able to use SNA/VTAM
for NSFNET. Somebody was collecting internal NSFNET SNA/VTAM
misinformation email and forwarded it to us (heavily clipped &
redacted to protect the guilty):
https://www.garlic.com/~lynn/2006w.html#email870109
peer-coupled shared data architecture posts
https://www.garlic.com/~lynn/submain.html#shareddata
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
some recent posts mentioning AWP164/APPN
https://www.garlic.com/~lynn/2026.html#2 43 Years Of TCP/IP
https://www.garlic.com/~lynn/2025e.html#51 IBM VTAM/NCP
https://www.garlic.com/~lynn/2025d.html#78 Virtual Memory
https://www.garlic.com/~lynn/2025d.html#67 SNA & TCP/IP
https://www.garlic.com/~lynn/2025d.html#4 Mainframe Networking and LANs
https://www.garlic.com/~lynn/2025c.html#71 IBM Networking and SNA 1974
https://www.garlic.com/~lynn/2025.html#54 Multics vs Unix
https://www.garlic.com/~lynn/2025.html#0 IBM APPN
https://www.garlic.com/~lynn/2024g.html#73 Early Email
https://www.garlic.com/~lynn/2024g.html#40 We all made IBM 'Great'
https://www.garlic.com/~lynn/2024c.html#53 IBM 3705 & 3725
https://www.garlic.com/~lynn/2024.html#84 SNA/VTAM
https://www.garlic.com/~lynn/2023g.html#18 Vintage X.25
https://www.garlic.com/~lynn/2023e.html#41 Systems Network Architecture
https://www.garlic.com/~lynn/2023c.html#49 Conflicts with IBM Communication Group
https://www.garlic.com/~lynn/2023b.html#54 Ethernet (& CAT5)
https://www.garlic.com/~lynn/2022f.html#4 What is IBM SNA?
https://www.garlic.com/~lynn/2022e.html#34 IBM 37x5 Boxes
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Downfall Date: 01 Mar, 2026 Blog: Facebook1972, Learson tried (& failed) to block the bureaucrats, careerists, and MBAs from destroying Watson culture/legacy, pg160-163, 30yrs of management briefings 1958-1988
Future System disaster, from "Computer Wars: The Post-IBM World"
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and
*MAKE NO WAVES* under Opel and Akers. It's claimed that
thereafter, IBM lived in the shadow of defeat ... But because of the
heavy investment of face by the top management, F/S took years to
kill, although its wrong headedness was obvious from the very
outset. "For the first time, during F/S, outspoken criticism became
politically dangerous," recalls a former top executive
More FS
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
Opel's obit ...
https://www.pcworld.com/article/243311/former_ibm_ceo_john_opel_dies.html
According to the New York Times, it was Opel who met with Bill Gates,
CEO of the then-small software firm Microsoft, to discuss the
possibility of using Microsoft PC-DOS OS for IBM's
about-to-be-released PC. Opel set up the meeting at the request of
Gates' mother, Mary Maxwell Gates. The two had both served on the
National United Way's executive committee.
... before ms/dos
https://en.wikipedia.org/wiki/MS-DOS
there was Seattle computer
https://en.wikipedia.org/wiki/Seattle_Computer_Products
before Seattle computer, there was CP/M
https://en.wikipedia.org/wiki/CP/M
before developing CP/M, Kildall worked on IBM CP/67 (precursor to VM/370) at npg
https://en.wikipedia.org/wiki/Naval_Postgraduate_School
... aka CP/M "Microprocessor" rather than "CP/67"
I was introduced to John Boyd in early 80s and use to sponsor his
briefings at IBM. In 89/90, the Marine Corps Commandant leverages Boyd
for make-over of the Marines (at a time when IBM was desperately in
need of make-over). 1992, 20years after Learson fails to block the
destruction of the Watson culture/legacy, IBM has one of the largest
losses in history of US companies ... and was being reorganized into
the 13 "baby blues" in preparation for breaking up the company ("baby
blues" take-off on "baby bells" breakup a decade earlier)
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
AMEX and KKR were in competition for private-equity,
reverse-IPO(/LBO) buyout of RJR and KKR wins. Barbarians at the Gate
https://en.wikipedia.org/wiki/Barbarians_at_the_Gate:_The_Fall_of_RJR_Nabisco
KKR runs into problems with RJR and hires away AMEX President to help
with RJR.
The year that IBM has one of the largest losses in history of US companies, AMEX spins of its transaction outsourcing businesses and most of its mainframe datacenters in the largest IPO (up until that time) as First Data.
We've left IBM and start doing some contract work for FDC. Turn of the century asked to look at performance of one of their largest datacenters, handles half of all credit card accounts in the US (transactions, call centers, statementing, billing, plastic cards, etc), 40+ max configured IBM mainframes (@$30M, aka >$1B, none older than 18months, constant rolling upgrades, number needed to finish settlement in overnight batch window), all running same 450K Cobol statement application. Used some performance analysis technologies from 70s IBM Cambridge Scientific Center and found 14% improvement (nearly $200M). Then 15yrs after FDC was spun off in the largest IPO (up until that time), KKR does LBO of FDC (in the largest LBO up until that time).
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
John Boyd posts and web URLs
https://www.garlic.com/~lynn/subboyd.html
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
posts mentioning FDC 450K Cobol statement program handling
half of all plastic/credit card accounts in US
https://www.garlic.com/~lynn/2025e.html#98 IBM Downfall
https://www.garlic.com/~lynn/2025e.html#27 Opel
https://www.garlic.com/~lynn/2025c.html#31 IBM Downfall
https://www.garlic.com/~lynn/2024.html#112 IBM User Group SHARE
https://www.garlic.com/~lynn/2021i.html#87 UPS & PDUs
https://www.garlic.com/~lynn/2021d.html#68 How Gerstner Rebuilt IBM
https://www.garlic.com/~lynn/2021c.html#61 MAINFRAME (4341) History
https://www.garlic.com/~lynn/2021c.html#49 IBM CEO
https://www.garlic.com/~lynn/2021.html#7 IBM CEOs
https://www.garlic.com/~lynn/2019e.html#155 Book on monopoly (IBM)
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 3033 Date: 01 Mar, 2026 Blog: Facebookre:
I continued to stay in touch with the 3033 processor engineers after the 16-CPU effort was canceled and after the 3033 was out the door and they started on trout/3090. They did some email of analysis of 3081 ... including 3081 having limited microcode space and had to "page" microcode (severely impacted throughput for both 370 and 370/XA architectures and later virtual machine SIE-instruction; note even though head of POK had convinced corporate to kill VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA, after MVS/XA was released, they found that Amdahl was having much better success migrating customers to MVS/XA since Amdahl could run both MVS & MVS/XA concurrently).
3081D claimed to be two 5MIP processors improved to two 7MIP processors for 3081K ... compared to Amdahl 14MIP single processor (and because MVS&MVS/XA multiprocessor overhead, 3081K was only .6-.75 throughput of Amdahl single processor, even with same aggregate MIPS)
One of the last nails in the Future System coffin was analysis by the
IBM Houston Science Center was that if 370/195 applications was
rewritten for FS machine made out of the fastest available hardware,
they would have throughput of 370/145 (about 30 times slowdown). More
detail
http://www.jfsowa.com/computer/memo125.htm
Shortly after graduating and joining IBM Cambridge Science Center, I did a page-mapped filesystem for CMS ... and for modest filesystem workload, it could have three times the throughput of the standard filesystem. Both IBM's TSS/360 and MIT's MULTICS (CSC was on 4th flr, MIT MULTICS was flr above on the 5th flr) had single-level store architecture (heavily influencing Future System and Rochester derivatives)... and I would claim that I learned what not to do for page-mapped filesystem from TSS/360 & MULTICS.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
paged-mapped filesystem
https://www.garlic.com/~lynn/submain.html#mmap
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Early EMAIL Date: 02 Mar, 2026 Blog: FacebookMIT CTSS/7094 had "email". Then some of the CTSS/7094 people went to the 5th flr for Multics and others went to the the IBM Cambridge Scientific Center on the 4th flr and did virtual machines (wanted 360/50 to add virtual memory, but all extra 50s were going to FAA/ATC and they had to settle for 360/40 and did CP40/CMS which morphs into CP67/CMS when 360/67 standard with virtual memory becomes available), CP67-based science center wide area network (which morphs into the IBM internal corporate network larger than arpanet/internet from the beginning until sometime mid/late 80s, about the time it was forced to convert to SNA/VTAM. technology also used for the corporate sponsored univ BITNET
also invented GML in 1969 (which later morphs into SGML and HTML)
... and various other online apps. One of the GML inventors had been
hired to promote the CP67-based Wide Area network:
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
co-worker responsible for the CP67-based Wide Area Network
https://en.wikipedia.org/wiki/Edson_Hendricks
In June 1975, MIT Professor Jerry Saltzer accompanied Hendricks to
DARPA, where Hendricks described his innovations to the principal
scientist, Dr. Vinton Cerf. Later that year in September 15-19 of 75,
Cerf and Hendricks were the only two delegates from the United States,
to attend a workshop on Data Communications at the International
Institute for Applied Systems Analysis, 2361 Laxenburg Austria where
again, Hendricks spoke publicly about his innovative design which
paved the way to the Internet as we know it today.
... snip ...
newspaper article about some of Edson's Internet & TCP/IP IBM battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed, Internet &
TCP/IP) references from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
PROFS group started collecting command line apps for wrapping 3270 menus around, and very earlier version of VMSG was selected for the email client. Then the VMSG author offered the PROFS group a much enhanced version ... and PROFS group tried to have him separated from IBM. The whole thing quieted down when VMSG author demonstrated his initials in all PROFS email (in non-dispalyed field). After that he only shared his source with me and one other person.
Got HSDT project early 80s, T1 and faster computer links (both
terrestrial and satellite) and battles with SNA group (60s, IBM had
2701 supporting T1, 70s with SNA/VTAM and issues, links were capped at
56kbit ... and had to mostly resort to non-IBM hardware). Also was
working with NSF director and was suppose to get $20M to interconnect
the NSF Supercomputer centers. Then congress cuts the budget, some
other things happened and eventually there was RFP released (in part
based on what we already had running). NSF 28Mar1986 Preliminary
Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
Somebody was collecting internal SNA/VTAM misinformation email about
justification for converting internal network to SNA/VTAM as well as
using SNA/VTAM for NSFNET and forwarded it to us ... old archive post
(email heavily clipped and redacted to protect the guilty)
https://www.garlic.com/~lynn/2006w.html#email870109
trivia: At 1Jan1983 of the great cutover from HOST/IMP to
internetworking, there were about 100 IMPs and 255 host and the
internal corporate network was rapidly approaching 1000 nodes
world-wide ... old archived post with list of world wide corporate
locations that added one or more nodes during 1983
https://www.garlic.com/~lynn/2006k.html#8
and IBM 1983 1000th node globe:
;
IBM Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
BITNET (& EARN) posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM OS Debugging Date: 02 Mar, 2026 Blog: FacebookI had taken two credit hr intro to fortran/computers and at end of semester was hired to rewrite 1401 MPIO in 360 assembler for 360/30. The univ was getting 360/67 for TSS/360 replacing 709/1401 and got a 360/30 temporarily pending 360/67s. Univ. shutdown datacenter on weekends and I got the whole place (although 48hrs w/o sleep made Monday classes hard). They gave me a pile of hardware and software manuals and I got to design and implement my own monitor, device drivers, interrupt handlers, error recovery/retry, storage management, etc and within a few weeks had 2000 card assembler program). I quickly learned first thing Sat. morning, to clean tape drives and printers, disassemble/clean/reassemble 2540 reader/punch. Sometimes production had finished early and all power was off when I show up. I had to power everything back on ... sometimes wouldn't come back up; lots of manuals and trial&error to learn to get things back powered on. Within year of intro class, the 360/67 arrived and I was hired fulltime responsible for OS/360 (TSS/360 never came to fruition).
Student fortran ran less than second on 709. Initially on 360/67 OS/360, student fortran ran over minute. First SYSGEN was R9.5 and I install HASP, cutting time in half. Then start redoing SYSGEN R11 STAGE2, carefully placing datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9sec. 360/67 never got better than 709 until I install UofWaterloo WATFOR (360 65&67 clocked WATFOR at 20,000 statements/minute; 333/sec; student fortran tended to run 30-60 cards).
Then CSC came out to install (virtual machine) CP/67 (3rd after CSC itself and MIT Lincoln Labs) and I mostly get to play with it during my weekend 48hr window. I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher/scheduler , (dynamic adaptive resource manager/default fair share scheduling policy), paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial CP/67 install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support and auto-terminal ident,
capable switching terminal type scanner type for each port. Univ. also
had TTY33&35 and I add ASCII support integrated with auto-terminal
type. I then want to have single dial-in number (hunt group) for all
terminals. Didn't quite work, IBM had hard-wired line speed ... so we
start a clone terminal controller. Build a IBM channel interface board
for Interdata/3 programmed to emulate IBM controller with the addition
for auto-baud. Then upgrading with Interdata/4 for channel interface
and cluster of Interdata/3s for port interfaces. Interdata (and later
Perkin-Elmer) sell them as clone controllers.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
... and four of us are written up responsible for (some part of) clone
controller business
Then do MFT-R14 SYSGEN, followed by MVT-R15/R16 SYSGEN and MVT-R18 SYSGEN (also add CRJE terminal support with CMS-edit syntax to HASP).
Before I graduate, I'm hired fulltime into a small group in the Boeing CFO office to help with the formation of Boeing Computer Services, consolidate all dataprocessing into independent business unit (at the time, 747-3 was flying skies of Seattle getting FAA flt certification). I think Renton datacenter possibly largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in the hallways around the machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing Field for payroll, although they enlarge the room to install a 360/67 for me to play with when I wasn't busy with other stuff. When I graduate, I join CSC instead of staying with the Boeing CFO.
Decade later (at IBM) I wanted to show that REX (before renamed and
provided to customers), wasnt just another pretty scripting
language. I select large assembler dump analysis program to redo in
REX with ten times the function and ten times the performance (lots of
hack to run interpreted REX faster than assembler) with objective of
working half time over three months. I finish early and add library of
automated processes that search for common failure signatures. I
assume that it would replace the assembler version, but for what ever
reason it wasn't, even though it was in use by nearly every internal
datacenter and PSR. I eventually get permissions to give presentations
on how it was implemented. The 3090 service processor (3092) group
eventually asks if they could ship it.
Date: 31 October 1986, 16:32:58 EST
To: wheeler
Re: 3090/3092 Processor Controll and plea for help
The reason I'm sending this note to you is due to your reputation of
never throwing anything away that was once useful (besides the fact
that you wrote a lot of CP code and (bless you) DUMPRX.
I've discussed this with my management and they agreed it would be
okay to fill you in on what the 3090 PC is so I can intelligently ask
for your assistance.
The 3092 (3090 PC) is basically a 4331 running CP SEPP REL 6 PLC29
with quite a few local mods. Since CP is so old it's difficult, if not
impossible to get any support from VM development or the change team.
What I'm looking for is a version of the CP FREE/FRET trap that we
could apply or rework so it would apply to our 3090 PC. I was hoping
you might have the code or know where I could get it from (source
hopefully).
The following is an extract from some notes sent to me from our local
CP development team trying to debug the problem. Any help you can
provide would be greatly appreciated.
... snip ... top of post, old email index
Date: 23 December 1986, 10:38:21 EST
To: wheeler
Re: DUMPRX
Lynn, do you remember some notes or calls about putting DUMPRX into an
IBM product? Well .....
From the last time I asked you for help you know I work in the
3090/3092 development/support group. We use DUMPRX exclusively for
looking at testfloor and field problems (VM and CP dumps). What I
pushed for back aways and what I am pushing for now is to include
DUMPRX as part of our released code for the 3092 Processor Controller.
I think the only things I need are your approval and the source for
RXDMPS.
I'm not sure if I want to go with or without XEDIT support since we do
not have the new XEDIT.
In any case, we (3090/3092 development) would assume full
responsibility for DUMPRX as we release it. Any changes/enhancements
would be communicated back to you.
If you have any questions or concerns please give me a call. I'll be
on vacation from 12/24 through 01/04.
... snip ... top of post, old email index
Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
IBM plug-compatible/clone controllers
https://www.garlic.com/~lynn/submain.html#360pcm
HASP/JES NJE/NJI posts
https://www.garlic.com/~lynn/submain.html#hasp
dumprx posts
https://www.garlic.com/~lynn/submain.html#dumprx
recent posts mentioning 1401 MPIO, student fortran, watfor, boeing
cfo, renton
https://www.garlic.com/~lynn/2026.html#67 Early Mainframe work
https://www.garlic.com/~lynn/2026.html#59 IBM CP67 and VM370
https://www.garlic.com/~lynn/2026.html#28 360 Channel
https://www.garlic.com/~lynn/2026.html#24 IBM 360, Future System
https://www.garlic.com/~lynn/2025e.html#104 Early Mainframe Work
https://www.garlic.com/~lynn/2025e.html#74 IBM 370 Virtual Memory
https://www.garlic.com/~lynn/2025e.html#57 IBM 360/30 and other 360s
https://www.garlic.com/~lynn/2025d.html#112 Mainframe and Cloud
https://www.garlic.com/~lynn/2025d.html#99 IBM Fortran
https://www.garlic.com/~lynn/2025d.html#15 MVT/HASP
https://www.garlic.com/~lynn/2025c.html#115 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#64 IBM Vintage Mainframe
https://www.garlic.com/~lynn/2025c.html#55 Univ, 360/67, OS/360, Boeing, Boyd
https://www.garlic.com/~lynn/2025b.html#59 IBM Retain and other online
https://www.garlic.com/~lynn/2025.html#91 IBM Computers
https://www.garlic.com/~lynn/2024g.html#39 Applications That Survive
https://www.garlic.com/~lynn/2024g.html#17 60s Computers
https://www.garlic.com/~lynn/2024f.html#124 Any interesting PDP/TECO photos out there?
https://www.garlic.com/~lynn/2024f.html#110 360/65 and 360/67
https://www.garlic.com/~lynn/2024f.html#88 SHARE User Group Meeting October 1968 Film Restoration, IBM 360
https://www.garlic.com/~lynn/2024f.html#69 The joy of FORTH (not)
https://www.garlic.com/~lynn/2024f.html#20 IBM 360/30, 360/65, 360/67 Work
https://www.garlic.com/~lynn/2024e.html#136 HASP, JES2, NJE, VNET/RSCS
https://www.garlic.com/~lynn/2024d.html#103 IBM 360/40, 360/50, 360/65, 360/67, 360/75
https://www.garlic.com/~lynn/2024d.html#76 Some work before IBM
https://www.garlic.com/~lynn/2024d.html#22 Early Computer Use
https://www.garlic.com/~lynn/2024c.html#93 ASCII/TTY33 Support
https://www.garlic.com/~lynn/2024c.html#15 360&370 Unix (and other history)
https://www.garlic.com/~lynn/2024b.html#97 IBM 360 Announce 7Apr1964
https://www.garlic.com/~lynn/2024b.html#63 Computers and Boyd
https://www.garlic.com/~lynn/2024b.html#60 Vintage Selectric
https://www.garlic.com/~lynn/2024b.html#44 Mainframe Career
https://www.garlic.com/~lynn/2024.html#87 IBM 360
https://www.garlic.com/~lynn/2024.html#43 Univ, Boeing Renton and "Spook Base"
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Early EMAIL Date: 03 Mar, 2026 Blog: Facebookre:
Ed and I had transferred out to SJR on the west coast. Then SJR
installs 1st corporate gateway to CSNET Oct1982.
https://en.wikipedia.org/wiki/CSNET
Some email about the CSNET install and then CSNET comment about
difficulties with internetworking cut over 1jan1983.
Date: 10/22/82 14:25:57
To: CSNET mailing list
Subject: CSNET PhoneNet connection functional
The IBM San Jose Research Lab is the first IBM site to be registered
on CSNET (node-id is IBM-SJ), and our link to the PhoneNet relay at
University of Delaware has just become operational! For initial
testing of the link, I would like to have traffic from people who
normally use the ARPANET, and who would be understanding about delays,
etc. If you are such a person, please send me your userid (and nodeid
if not on SJRLVM1), and I'll send instructions on how to use the
connection. People outside the department or without prior usage of
of ARPANET may also register at this time if there is a pressing need,
such as being on a conference program committee, etc.
CSNET (Computer Science NETwork) is funded by NSF, and is an attempt
to connect all computer science research institutions in the U.S. It
does not have a physical network of its own, but rather is a set of
common protocols used on top of the ARPANET (Department of Defense),
TeleNet (GTE), and PhoneNet (the regular phone system). The
lowest-cost entry is through PhoneNet, which only requires the
addition of a modem to an existing computer system. PhoneNet offers
only message transfer (off-line, queued, files). TeleNet and ARPANET
in allow higher-speed connections and on-line network capabilities
such as remote file lookup and transfer on-line, and remote login.
... snip ... top of post, old email index
Date: 02/02/83 23:49:45
To: CSNET mailing list
Subject: CSNET headers, CSNET status
You may have noticed that since ARPANET switched to TCP/IP and the new
version of software on top of it, message headers have become
ridiculously long. Some of it is because of tracing information that
has been added to facilitate error isolation and "authentication", and
some of it I think is a bug (the relay adds a 'From' and a 'Date'
header although there already are headers with that information in the
message). This usually doesn't bother people on the ARPANET because
they have smart mail reading programs that understand the headers and
only display the relevant ones. I have proposed a mail reader/sender
program that understands about ARPANET headers (RFC822) as a summer
project, so maybe we will sometime enjoy the same priviledge.
The file CSNET STATUS1 on the CSNET disk (see instructions below for
how to access it) contains some clarification of the problems that
have been experienced with the TCP/IP conversion. Here is a summary:
- Nodes that don't yet talk TCP (but the old NCP) can be accessed
through the UDel-Relay. So if you think you have problems reaching a
node because of this, append @Udel-Relay to the ARPANET
- You can find out about the status of hosts (e.g., if they run TCP or
not) by sending ANY MESSAGE to Status@UDel-Relay (capitalization is
NOT significant).
- If your messages are undeliverable, you get a notice after two days,
and your messages get returned after 4 days.
- Avoid using any of the fancy address forms allowed by the new header
format (RFC822).
- The TCP transition was a lot more trouble than the ARPANET people
had anticipated.
... snip ... top of post, old email index
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Early EMAIL Date: 03 Mar, 2026 Blog: FacebookIBMJargon: "Tandem Memo"; In the late 70s & early 80s, I was blamed for online computer conferencing on the internal network (precursor to modern social media) ... really took off spring 1981 when I distributed trip report to see Jim Gray at Tandem (I had worked with Jim Gray and Vera Watson on original SQL/Relational, System/R, before Jim left fall1980), only 300 actively participated but claim 25,000 were reading. Summer 1981, sent printed copies in Tandem 3-ring binders to each member of the corporate executive committee (folklore was that 5of6 members wanted to fire me). There were then a number of task forces to study the phenomena ... and official sanctioned "forum" software and discussion forums. IBMJargon
Researcher was paid to study how I communicated ... sat in the back of my office for nine months taking notes, also got copies of my incoming and outgoing email, and logs of instant messages. Material was used for IBM research reports, conference talks and papers, books and Stanford Phd (joint between Lanugage and Computer AI, Winograd was advisor on on Computer AI side).
Online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
Original SQL/Relational System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
Some posts mentioning IBMJargon, Tandem Memo, Winograd
https://www.garlic.com/~lynn/2026.html#68 Adirondack
https://www.garlic.com/~lynn/2026.html#47 IBM Internal Network
https://www.garlic.com/~lynn/2026.html#5 PROFS and other CMS applications
https://www.garlic.com/~lynn/2025d.html#101 Stanford WYLBUR, ORVYL, MILTON
https://www.garlic.com/~lynn/2025d.html#31 Public Facebook Mainframe Group
https://www.garlic.com/~lynn/2025.html#92 IBM Suggestion Plan
https://www.garlic.com/~lynn/2021j.html#85 Happy 50th Birthday, EMAIL!
https://www.garlic.com/~lynn/2021h.html#47 Dynamic Adaptive Resource Management
https://www.garlic.com/~lynn/2021e.html#8 Online Computer Conferencing
https://www.garlic.com/~lynn/2021e.html#3 IBM Internal Network
https://www.garlic.com/~lynn/2019e.html#160 Y2K
https://www.garlic.com/~lynn/2017g.html#94 AI Is Inventing Languages Humans Can't Understand. Should We Stop It?
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 60s-90s Date: 04 Mar, 2026 Blog: FacebookUndergraduate I took a two credit hour intro to fortran/computers. At the end of semester, I was hired to rewrite 1401 MPIO in assembler for 360/30. The univ was getting 360/67 for tss/360 replacing 709/1401 (360/30 temporarily replaced 1401 pending arrival of 360/67). The univ. shutdown datacenter on weekends and I would have the place dedicated (although 48hrs w/o sleep made monday classes hard). I was given pile of hardware&software manuals and got to design & implement monitor, device drivers, interrupt handlers, error recovery, storage management, etc. and within a few weeks had 2000 card assembler program. Within a year of taking intro class, 360/67 arrives and I'm hired fulltime responsible for OS/360. 709 took less than second for student fortran, initially OS/360 took over minute. I install HASP cutting time in half. I then start redoing SYSGEN STAGE2 to carefully place datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9secs. 360/67 never got better than 709 until I instal UofWaterloo WATFOR. WATFOR clocked on 360/67/65 20,000 cards/min, 333 cards/sec, student fortran ran 30-60 cards.
Before I graduate, I'm hired fulltime into small group in Boeing CFO office to help with formation of Boeing Computer Services. I think Renton largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing Field for payroll, although they enlarge the room to install 360/67 for me to play with when I wasn't doing other stuff. Boeing & IBM tell story that on 360 announce day, Boeing gives IBM marketing rep a large 360 order, making the rep the highest earning employee that year (still in days of straight commission). For next year, IBM introduces quota and Boeing submits another large order. IBM "adjusts" his quota and he leaves IBM. When I graduate, I join IBM (instead of staying with CFO).
In early 80s, I'm introduced to John Boyd and use to sponsor his
brieifings at IBM. 89/90, Marine Corps Commandant leverages Boyd for a
Corps make-over (at a time when IBM was desperately in need of make
over). 1992, IBM has one of the largest losses in the history of US
companies and was being re-orged into the 13 "baby blues" in
preparation for breakup of the company ("baby blue" take-off on "baby
bell" breakup a decade earlier).
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
Boyd had lots of stories, including being very vocal that the
electronics across the trail wouldn't work. Possibly as punishment,
Boyd is put in command of "spook base" (about the same time I'm at
Boeing), said that it had the largest air conditioned bldg in that
part of the world. Boyd biography claims that "spook base" was a $2.5B
windfall for IBM (possibly ten times Renton). Spook base refs:
https://web.archive.org/web/20030212092342/http://home.att.net/~c.jeppeson/igloo_white.html
https://en.wikipedia.org/wiki/Operation_Igloo_White
also mentioned here: When Big Blue Went to War: A History of the Ibm
Corporation'S Mission in Southeast Asia During the Vietnam War
(1965–1975)
https://www.amazon.com/When-Big-Blue-Went-War-ebook/dp/B07923TFH5/
loc192-99:
We four marketing reps, Mike, Dave, Jeff and me, in Honolulu (1240 Ala
Moana Boulevard) qualified for IBM's prestigious 100 Percent Club
during this period but our attainment was carefully engineered by
mainland management so that we did not achieve much more than the
required 100% of assigned sales quota and did not receive much in
sales commissions. At the 1968 100 Percent Club recognition event at
the Fontainebleau Hotel in Miami Beach, the four of us Hawaiian Reps
sat in the audience and irritably watched as eight other "best of the
best" IBM commercial marketing representatives from all over the
United States receive recognition awards and big bonus money on
stage. The combined sales achievement of the eight winners was
considerably less than what we four had worked hard to achieve in the
one small Honolulu branch office. Clearly, IBM was not interested in
hearing accusations of war profiteering and they maintained that
posture throughout the years of the company's wartime involvement.
... snip ..
other refs:
https://en.wikipedia.org/wiki/Alfred_M._Gray_Jr%2E
https://en.wikipedia.org/wiki/John_Boyd_(military_strategist)
https://en.wikipedia.org/wiki/Energy%E2%80%93maneuverability_theory
https://en.wikipedia.org/wiki/OODA_loop
https://www.usmcu.edu/Outreach/Marine-Corps-University-Press/Books-by-topic/MCUP-Titles-A-Z/A-New-Conception-of-War/
https://thetacticalprofessor.net/2018/04/27/updated-version-of-boyds-aerial-attack-study/
John Boyd - USAF The Fighter Pilot Who Changed the Art of Air Warfare
http://www.aviation-history.com/airmen/boyd.htm
Boyd then used E-M as a design tool. Until E-M came along, fighter
aircraft had been designed to fly fast in a straight line or fly high
to reach enemy bombers. The F-X, which became the F-15, was the first
Air Force fighter ever designed with maneuvering specifications. Boyd
was the father of the F-15, the F-16, and the F-18.
... snip ...
Boyd passed in 1997, but we continued to have Boyd-themed conferences at MCU after turn of the century.
John Boyd posts and URLs
https://www.garlic.com/~lynn/subboyd.html
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
Posts mentioning 709/1401, MPIO, Fortran, OS/360, WATFOR, Boeing CFO,
Renton, BCS
https://www.garlic.com/~lynn/2026.html#78 IBM OS Debugging
https://www.garlic.com/~lynn/2026.html#67 Early Mainframe work
https://www.garlic.com/~lynn/2026.html#59 IBM CP67 and VM370
https://www.garlic.com/~lynn/2026.html#28 360 Channel
https://www.garlic.com/~lynn/2026.html#24 IBM 360, Future System
https://www.garlic.com/~lynn/2025e.html#104 Early Mainframe Work
https://www.garlic.com/~lynn/2025e.html#57 IBM 360/30 and other 360s
https://www.garlic.com/~lynn/2025d.html#112 Mainframe and Cloud
https://www.garlic.com/~lynn/2025d.html#99 IBM Fortran
https://www.garlic.com/~lynn/2025d.html#15 MVT/HASP
https://www.garlic.com/~lynn/2025c.html#115 IBM VNET/RSCS
https://www.garlic.com/~lynn/2025c.html#64 IBM Vintage Mainframe
https://www.garlic.com/~lynn/2025c.html#55 Univ, 360/67, OS/360, Boeing, Boyd
https://www.garlic.com/~lynn/2025b.html#59 IBM Retain and other online
https://www.garlic.com/~lynn/2025.html#91 IBM Computers
https://www.garlic.com/~lynn/2024g.html#39 Applications That Survive
https://www.garlic.com/~lynn/2024g.html#17 60s Computers
https://www.garlic.com/~lynn/2024f.html#124 Any interesting PDP/TECO photos out there?
https://www.garlic.com/~lynn/2024f.html#110 360/65 and 360/67
https://www.garlic.com/~lynn/2024f.html#88 SHARE User Group Meeting October 1968 Film Restoration, IBM 360
https://www.garlic.com/~lynn/2024f.html#69 The joy of FORTH (not)
https://www.garlic.com/~lynn/2024f.html#20 IBM 360/30, 360/65, 360/67 Work
https://www.garlic.com/~lynn/2024e.html#136 HASP, JES2, NJE, VNET/RSCS
https://www.garlic.com/~lynn/2024d.html#103 IBM 360/40, 360/50, 360/65, 360/67, 360/75
https://www.garlic.com/~lynn/2024d.html#76 Some work before IBM
https://www.garlic.com/~lynn/2024d.html#22 Early Computer Use
https://www.garlic.com/~lynn/2024c.html#93 ASCII/TTY33 Support
https://www.garlic.com/~lynn/2024c.html#15 360&370 Unix (and other history)
https://www.garlic.com/~lynn/2024b.html#97 IBM 360 Announce 7Apr1964
https://www.garlic.com/~lynn/2024b.html#63 Computers and Boyd
https://www.garlic.com/~lynn/2024b.html#60 Vintage Selectric
https://www.garlic.com/~lynn/2024b.html#44 Mainframe Career
https://www.garlic.com/~lynn/2024.html#87 IBM 360
https://www.garlic.com/~lynn/2024.html#43 Univ, Boeing Renton and "Spook Base"
https://www.garlic.com/~lynn/2023g.html#80 MVT, MVS, MVS/XA & Posix support
https://www.garlic.com/~lynn/2023g.html#19 OS/360 Bloat
https://www.garlic.com/~lynn/2023f.html#83 360 CARD IPL
https://www.garlic.com/~lynn/2023e.html#64 Computing Career
https://www.garlic.com/~lynn/2023e.html#54 VM370/CMS Shared Segments
https://www.garlic.com/~lynn/2023e.html#34 IBM 360/67
https://www.garlic.com/~lynn/2023d.html#106 DASD, Channel and I/O long winded trivia
https://www.garlic.com/~lynn/2023d.html#88 545tech sq, 3rd, 4th, & 5th flrs
https://www.garlic.com/~lynn/2023d.html#69 Fortran, IBM 1130
https://www.garlic.com/~lynn/2023d.html#32 IBM 370/195
https://www.garlic.com/~lynn/2023c.html#82 Dataprocessing Career
https://www.garlic.com/~lynn/2023c.html#73 Dataprocessing 48hr shift
https://www.garlic.com/~lynn/2023b.html#91 360 Announce Stories
https://www.garlic.com/~lynn/2023b.html#75 IBM Mainframe
https://www.garlic.com/~lynn/2023b.html#15 IBM User Group, SHARE
https://www.garlic.com/~lynn/2023.html#22 IBM Punch Cards
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM DASD, CKD, FBA Date: 07 Mar, 2026 Blog: Facebookno CKD DASD have been made for decades ... all being emulated on industry fixed-block devices. First thin-film heads were used for fixed-block 3370s ... then used for "CKD" 3380s (actually can be seen in 3380 records/track formulas where record lengths had to be rounded up to multiple of fixed "cell" size).
Large companies were ordering humdreds of vm/4341s at a time for placing out in departmental areas (3380s were datacenter ... only midrange non-datacenter was FBA3370). MVS wanted part of the market ... but no new CKD non-datacenter). Eventually they offer 3375 CKD emulation on 3370 ... it didn't do MVS much good ... they were doing scores of distributed VM/4341s per support staff ... while MVS was still scores of support staff per MVS.
1988, branch office asks if I could help LLNL (national lab) standardize some serial stuff they were working with which quickly becomes fibre-channel standard ("FCS", including some stuff I had done in 1980, initially 1gbit transfer, full-duplex, aggregate 200mbyte/sec). Then IBM mainframe release some serial (when it was already obsolete) as ESCON, initially 10mbyte/sec, upgrading to 17mbyte/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight protocol that drastically cuts native throughput, eventually ships as FICON. Around 2010 was a max configured z196 public "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON, running over FCS). Note IBM docs has SAPs (system assist processors that do actual I/O), CPU be kept to 70% ... or 1.5M IOPS
As undergraduate, I had taken two credit hr intro to fortran/computers and at end of semester was hired to rewrite 1401 MPIO in 360 assembler for 360/30. The univ was getting 360/67 for TSS/360 replacing 709/1401 and got a 360/30 temporarily pending 360/67s. Univ. shutdown datacenter on weekends and I got the whole place (although 48hrs w/o sleep made Monday classes hard). They gave me a pile of hardware and software manuals and I got to design and implement my own monitor, device drivers, interrupt handlers, error recovery/retry, storage management, etc and within a few weeks had 2000 card assembler program). I quickly learned first thing Sat. morning, to clean tape drives and printers, disassemble/clean/reassemble 2540 reader/punch. Sometimes production had finished early and all power was off, I had to power everything back on ... sometimes wouldn't come back up and lots of manuals and trial&error to learn to get things o . Within year of intro class, the 360/67 arrived and I was hired fulltime responsible for OS/360 (TSS/360 never came to fruition).
709 ran student jobs in less than second. Initially os/360 on (360/67 as) 360/65, ran over a minute. I install HASP cutting time in half. I then start carefully redo STAGE2 sysgen to place datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9secs. 360 never got better than 709 for student jobs until I install UofWaterloo WATFOR (on 360/65 clocked at 20,000 statements/min, 333/sec, typical student job was 30-60 statements).
Then IBM CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
Then before I graduate, I was hired into small group in Boeing CFO office to help with formation of Boeing Computer Services, consolidating all dataprocessing into an independent business unit. I think Renton was the largest IBM datacenters with 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around the machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing field for payroll (although they enlarge it to install 360/67 for me to play with when I wasn't doing other stuff). When I graduate, I join IBM CSC instead of staying with Boeing CFO.
During Future Systems (completely different than 370 and going to
replace it, 1st half 70s), internal politics was shutting down 370
efforts, claim is that lack of new 370 during FS is credited with
given clone 370 system makers their market foothold. When FS implodes,
there is mad rush to get stuff back into 370 product pipelines,
including kicking off quick&dirty 3033 & 3081 efforts in
parallel. More info:
https://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
With FS implosion, I got asked to help with a 16-CPU 370 and we con the 3033 processor engineers into helping in their spare time (lot more interesting than rempapping 168-logic to 20% faster chips).. Everybody thot it was great until somebody tells the head of POK that it could be decades before POK favorite son operating system ("MVS") had (effective) 16-CPU mutliprocessor support (POK doesn't ship 16-CPU machine until after the turn of the century). At the time MVS documentation had 2-CPU support only getting 1.2-1.5 times the throughput of a 1-CPU (of the same model), aka MVS multiprocessor overhead so large. Then head of POK asks some of us to never visit POK again and directed 3033 processor engineers, heads down and no distractions (once the 3033 was out the door the processor engineers start on trout/3090).
I then transfer out to SJR on the west coast and get to wander around datacenters in silicon valley, including disk bldg14/engineering and bldg15/product test across the street. They were doing prescheduled, 7x24, stand-alone testing and mentioned that they had recently tried MVS, but it had 15min MTBF (in that environment) requiring manual re-ipl. I offer to rewrite I/O supervisor to make it bullet-proof and never fail, allowing any amount of on-demand, concurrent testing, greatly improving productivity. Bldg15 then gets the first engineering 3033 outside POK processor engineering. Testing only took a percent of testing so we scrounge up a 3830 controller and 3330 string and setup our own private online service. trivia: 303x channel directors were (still) periodically hanging, requiring manual reset and discover if I quickly hit all six channel addresses with CLRCH, the channel director would automagically re-IMPL. I then write an (internal) I/O Integrity research report and happen to mention MVS 15min MTBF, bringing the wrath of the MVS organization down on my head.
At the time, air bearing simulation (for thin-film head design) was
only getting a couple turn arounds a month on SJR 370/195. We set it
up on bldg15 3033 (slightly less than half 195 MIPS) and they could
get several turn arounds a day.
https://www.computerhistory.org/storageengine/thin-film-heads-introduced-for-large-disks/
posts mentioning IBM DASD, CKD, FBA, multi-track search
https://www.garlic.com/~lynn/submain.html#dasd
posts mentioning getting to play disk engineer
https://www.garlic.com/~lynn/subtopic.html#disk
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Touch Type, Typewriters, Terminals Date: 07 Mar, 2026 Blog: FacebookFound 30s(?) typewriter in the dump when in middle school and taught myself how to touch type. In high school they were replacing class typewriters and got one (didn't have letters on keycaps). In college took two credit hr intro to fortran/comuters, student keypunch room had 026 keypunches. At the end of the semester, I was hired to re-implement 1401 MPIO in assembler for 360/30. Univ. Univ was getting 360/67 for tss/360 replacing 709/1401 and got 360/30 temporarily until availability of 360/67s. Univ. shutdown datacenter on weekends and I got the whole place dedicated (although 48hrs w/o sleep made Monday classes hard). I was given pile of hardware & software manuals and designed and implemented my own monitor, device drivers, interrupt handlers, error recovery, storage management, etc ... and within a few weeks had 2000 card assembler program
360/67 arrived within year of taking intro class and I was hired fulltime responsible for os/360 (tss/360 never came to fruition). 709 did student fortran in less than second, but 360/67 os/360 took over minute. I install HASP for MFT9.5 cutting time in half. I then start redoing MFT11 SYSGEN STAGE2 carefully placing datasets and PDS members optimizing arm seek and multi-track search cutting another 2/3rds to 12.9secs. 360/67 never got better than 709 until I install UofWaterloo WATFOR, clocked on 360/67 at 20,000 cards/min (333 cards/ssec ... student fortran tended to run 30-60cards/job).
Then CSC came out to install (virtual machine) CP/67 (3rd after CSC itself and MIT Lincoln Labs) and I mostly get to play with it during my weekend 48hr window. I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher/scheduler , (dynamic adaptive resource manager/default fair share scheduling policy), paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial CP/67 install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support and auto-terminal ident,
capable switching terminal type scanner type for each port. Univ. also
had TTY33&35 and I add ASCII support integrated with auto-terminal
type. I then want to have single dial-in number (hunt group) for all
terminals. Didn't quite work, IBM had hard-wired line speed ... so we
start a clone terminal controller. Build a IBM channel interface board
for Interdata/3 programmed to emulate IBM controller with the addition
for auto-baud. Then upgraded with Interdata/4 for channel interface
and cluster of Interdata/3s for port interfaces. Interdata (and later
Perkin-Elmer) sell them as clone controllers.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
... and four of us are written up responsible for (some part of) clone
controller business
I implement CRJE function in HASP for MVTR18 with editor that implements CMS EDIT syntax.
Before I graduate, I'm hired fulltime into small group in Boeing CFO office to help with formation of Boeing Computer Services. I think Renton largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing Field for payroll, although they enlarge the room to install 360/67 for me to play with when I wasn't doing other stuff. When I graduate, I join IBM CSC (instead of staying w/CFO).
Within couple weeks of joining IBM, I get a home (selectric) 2741 terminal and asked to teach CP67 customer classes down in DC ... then IBM gets new CSO (former gov. employee at one time head of presidential detail) and asked to periodically spend time with him talking about computer security.
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Clone (plug-compatible) controller posts
https://www.garlic.com/~lynn/submain.html#360pcm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM DASD, CKD, FBA Date: 08 Mar, 2026 Blog: Facebookre:
Note: 3090 service processor (3092) started out as 4331 running modified version of VM370R6. Before shipping, 3092 is upgraded to a pair of 4361s with 3370 (3090 required two 3370s even for MVS systems that never had FBA support). All 3092 service screens were done in CMS IOS3270
topic drift:
bldg15/disk product test gets engineering 4341 summer 1978 (customer ship isn't until following summer). Jan1979, branch office finds out about it and cons me into doing benchmark for national lab looking at getting 70 for compute farm (sort of the leading edge of the coming cluster supercomputing tsunami). It was sitting next to the engineering 3033 and we find modest cluster of 4341s has higher throughput than the 3033, less aggregate cost, smaller footprint, lower power&cooling.
communication group was fighting off release of mainframe TCP/IP support. When they lost, they changed strategy that since they had corporate responsibility for everything that crossed datacenter walls, it had to be released through them. What shipped got aggregate 44kbytes/sec throughput using nearly whole 3090 processor. I then added RFC1044 support and in some tuning tests at Cray Research between Cray and 4341, got sustained 4341 channel throughput using only modest amount of 4341 processor (something like 500 times increase in bytes moved per instruction executed)
1988, Donofrio approves HA/6000, originally for NYTimes to move their
newspaper system (ATEX) off DEC VAXCluster to RS/6000. I rename HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up with RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster support in same source base with UNIX. trivia: 2nd half of 70s, when I transferred to SJR on the west coast, I worked with Jim Gray and Vera Watson on the original SQL/relational, System/R ... had been developed on VM/370 ... then while corporation was preoccupied with the next great DBMS, EAGLE ... was able to do tech transfer (under the radar) to Endicott for SQL/DS ... then EAGLE implodes and was asked how fast could System/R be ported to MVS, eventually announced as "DB2" originally for decision-support *ONLY*.
IBM S/88 (relogo'ed Stratus) Product Administrator started taking us around to their customers and also had me write a section for the corporate continuous availability document (it gets pulled when both AS400/Rochester and mainframe/POK complain they couldn't meet requirements). Had coined disaster survivability and geographic survivability (as counter to disaster/recovery) when out marketing HA/CMP. One of the visits to 1-800 bellcore development showed that S/88 would use a century of downtime in one software upgrade, while HA/CMP had a couple extra "nines" (compared to S/88).
One of the first customer installs was new Indian Reservation Casino
in Connecticut, was suppose to have week of testing before opening
... but after 24hrs, they decided to open the doors (based on
projected revenue; at the time was largest in the US, still one of the
largest in the country)
https://en.wikipedia.org/wiki/Foxwoods_Resort_Casino#Debt_default
Early Jan92, there was HA/CMP meeting with Oracle CEO and IBM/AWD
executive Hester tells Ellison that we would have 16-system clusters
by mid92 and 128-system clusters by ye92. Mid-jan92, I update FSD on
HA/CMP work with national labs and FSD decides to go with HA/CMP for
federal supercomputers. By end of Jan, we are told that cluster
scale-up is being transferred to Kingston for announce as IBM
Supercomputer (technical/scientific *ONLY*) and we aren't allowed to
work with anything that has more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS,
... 128-systems: 16BIPS
IBM DASD, CKD, FBA, multi-track search posts
https://www.garlic.com/~lynn/submain.html#dasd
RFC1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
Original sql/relational, System/R
https://www.garlic.com/~lynn/submain.html#systemr
posts mentioning availability
https://www.garlic.com/~lynn/submain.html#available
posts mentioning assurance
https://www.garlic.com/~lynn/subintegrity.html#assurance
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Some IBM History Date: 09 Mar, 2026 Blog: FacebookAfter Future System imploded, Endicott talks me into helping with microcode assist for Virgil/Tully (aka 138/148, also used for 4331/4341). Early 80s, got permission to give talks at user group meetings on how ECPS was implemented (old, archived posting)
after some of the meetings, Amdahl people would ask for more detailed information. They said that they had developed MACROCODE (370 like instructions running in microcode mode) to quickly respond to a series of 3033 microcode features required by MVS to run. Amdahl was then in process of using MACROCODE to implement HYPERVISOR (multiple domain), able to run MVS and MVS/XA on the same machine (IBM doesn't respond with LPAR & PR/SM until nearly decade later, very late 80s).
Problem was after FS imploded, head of POK had convinced corporate to
kill the VM370 product, shutdown the development group and transfer
all the people to POK for MVS/XA. Endicott eventually manages to
acquire the VM370 product mission for the mid-range, but had to
recreate VM370 development group from scratch. Endicott then wanted to
pre-install VM370 on every 138/148 shipped ... but POK manages to get
corporate to veto pre-install. Then customers weren't migrating to
MVS/XA as POK planned ... but Amdahl was having more success being
able run MVS & MVS/XA concurrently on same machine (it wasn't several
years before POK manages to recreate a VM product that supported
370/XA mode). Somewhat similar to POK's plans for customers migrating
to MVS
http://www.mxg.com/thebuttonman/boney.asp
Part of IBM 3081 issue was limited microcode space and microcode needed for virtual machines had to be paged (severely impacting throughput). IBM LPAR & PR/SM doesn't appear until late in 3090 product life.
... other VM
Mainframe Hall of Fame ... four new members
https://web.archive.org/web/20110727105535/http://www.mainframezone.com/blog/mainframe-hall-of-fame-four-new-members-added/
and full list
https://www.enterprisesystemsmedia.com/mainframehalloffame
Knights of VM
http://mvmua.org/knights.html
Mar/Apr '05 eserver magazine article ... some history a little garbled
(gone 404, at wayback machine) ... Chief Scientist at FDC (before LBO
by KKR)
https://web.archive.org/web/20200103152517/http://archive.ibmsystemsmag.com/mainframe/stoprun/stop-run/making-history/
Apr2009 Greater IBM Connections Member profile article
https://www.garlic.com/~lynn/ibmconnect.html
May2024 Planetmainframe article
https://planetmainframe.com/influential-mainframers-2024/lynn-wheeler/
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
360/370/etc microcode posts
https://www.garlic.com/~lynn/submain.html#mcode
CSC, virtual machines, internal network, etc posts
https://www.garlic.com/~lynn/subtopic.html#545tech
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 4341 Date: 13 Mar, 2026 Blog: Facebook4341&3370 ... Got engineer 4341 summer 1978, a year before 1st. customer ship. jan1979, branch office finds out and cons me into benchmark for national lab looking at gettng 70 vm4341 for compute farm (sort of leading edge of the coming cluster supercomputer tsunami ... optimized price/performance)
then in 1980 ... started seeing large corporations ordering hundreds of vm4341s at a time for placing out in departmental areas (sort of leading edge of coming departmental computing tsunami ... inside IBM departmental conference becoming scarce so many turned into vm4341 rooms)
mvs looked at and wanted departmental market ... but only non-datacenter was FBA3370. Eventually they simulated 3375 CKD on 3370. Didn't do MVS much good ... distributed was doing scores of VM4341/staff while MVS was still scores of staff/MVS (some of distributed work going back to 60s with VM370 precursor CP67, with lots of work done for dark room, operator free option)
60s CP67, dark room, operator free, commercial online virtual machine
work
https://www.garlic.com/~lynn/submain.html#online
70s 3277/3272 terminal/controller had .086sec hardware response and I had several internal systems that were getting .11sec system response. 1980 studies showing quarter system response showing improved productivity (.086+.11=.196sec showing better than quarter sec). For 3278 lots of electronics moved back into 3274 controller ... reducing manufacturing cost but hardware response increased ... and amount of coax protocol ... getting .3sec-.5sec dependent on amount of data (never could meet hardware+system at least quarter second). Letters to 3278 product administrator got replies that 3278 wasn't intended for interactive computing (of course rare MVS even saw 1sec system response).
1988, branch office asked if I could help LLNL (national lab) with
standardize some serial stuff they were working with that becomes
fibre-channel standard ("FCS", initial 1gbit transfer, full-duplex,
aggregate 200mbyte/sec)
https://en.wikipedia.org/wiki/Fibre_Channel
Then POK announce their stuff in the 90s as ESCON (when it was already obsolete), initially 10mbytes/sec, upgraded to 17mbytes/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight FCS protocol that drastically cuts native throughput, eventually ships as FICON. Around 2010 was a max configured z196 public "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON, running over FCS). Note IBM docs has SAP (system assist processors that do actual I/O) CPUs be kept to 70% ... or 1.5M IOPS ... also no CKD DASD have been made for decades (just simulated on industry fixed-block devices). Industry benchmark, number of program iterations compared to industry MIPS/BIPS standard platform:
2010 max configured z196: 50BIPS, 80cores, 625MIPS/core 2010 E5-2600 server blade, two 8-core chips, 500BIPS, 31BIPS/core
Fibre channel Standard and/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
also 1988, Nick Donofrio approves HA/6000, initially for NYTimes to
move their newspaper system (ATEX) off DEC VAXCluster to RS/6000, I
rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing technical/scientific cluster scale-up with national
labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up with
RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster
support in same source base with UNIX (trivia: 2nd half of 70s, when I
transferred to SJR on the west coast, I worked with Jim Gray and Vera
Watson on the original SQL/relational, System/R ... had been developed
on VM/370 ... while corporation was preoccupied with the next great
DBMS, EAGLE ... was able to do tech transfer (under the radar) to
Endicott for SQL/DS ... then when EAGLE implodes was asked how fast
could System/R be ported to MVS, eventually announced as "DB2"
originally for decision-support *ONLY*).
Early Jan92, there was HA/CMP meeting with Oracle CEO and IBM/AWD
executive Hester tells Ellison that we would have 16-system clusters
by mid92 and 128-system clusters by ye92. Mid-jan92, I update FSD on
HA/CMP work with national labs and FSD decides to go with HA/CMP for
federal supercomputers. By end of Jan, we are told that cluster
scale-up is being transferred to Kingston for announce as IBM
Supercomputer (technical/scientific *ONLY*) and we aren't allowed to
work with anything that has more than four systems (we leave IBM a few
months later). A couple weeks later, 17feb1992, Computerworld news
... IBM establishes laboratory to develop (cluster supercomputing)
parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS,
.... 128-systems: 16BIPS
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
available posts
https://www.garlic.com/~lynn/submain.html#available
assurnace posts
https://www.garlic.com/~lynn/subintegrity.html#assurance
mid-80s the communication group released mainframe TCP/IP support getting aggregate 44kbytes/sec using nearly whole 3090 processor. I then add RFC1044 support and in some tuning tests at Cray Research between Cray and 4341 got sustained 4341 channel throughput using only modest amount of 4341 processor (something like 500 times bytes/instruction moved)
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
RFC1044 posts
https://www.garlic.com/~lynn/subnetwork.html#1044
After FS implodes, Endicott cons me into doing microcode ECPS for
138/148 (6k bytes ... 370 to microcode about one for one at 10:1
speedup of 79.55% of kernel execution)... also 4331&4341. ... For
4361&4381 was to use 801/risc Iliad chip for microcode engine. However
person that cons me into ECPS gets me to help write white paper
showing can directly implement nearly whole 370 in chip circuits (w/o
all the microcode). Archived post with initial ECPS analysis
https://www.garlic.com/~lynn/94.html#21
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
Some recent posts mentioning 4341 benchmark for cluster supercomputing
https://www.garlic.com/~lynn/2026.html#84 IBM DASD, CKD, FBA
https://www.garlic.com/~lynn/2026.html#60 IBM 135/145, 138/148, 4331/4341
https://www.garlic.com/~lynn/2026.html#10 4341, cluster supercomputing, distributed computing
https://www.garlic.com/~lynn/2026.html#7 Cluster Supercomputer Tsunami
https://www.garlic.com/~lynn/2025e.html#112 The Rise Of The Internet
https://www.garlic.com/~lynn/2025e.html#67 Mainframe to PC
https://www.garlic.com/~lynn/2025e.html#50 IBM Disks
https://www.garlic.com/~lynn/2025e.html#44 IBM SQL/Relational
https://www.garlic.com/~lynn/2025e.html#41 IBM 360/85
https://www.garlic.com/~lynn/2025e.html#35 Linux Clusters
https://www.garlic.com/~lynn/2025e.html#29 IBM Thin Film Disk Head
https://www.garlic.com/~lynn/2025e.html#1 Mainframe skills
https://www.garlic.com/~lynn/2025d.html#98 IBM Supercomputer
https://www.garlic.com/~lynn/2025d.html#78 Virtual Memory
https://www.garlic.com/~lynn/2025d.html#68 VM/CMS: Concepts and Facilities
https://www.garlic.com/~lynn/2025d.html#53 Computing Clusters
https://www.garlic.com/~lynn/2025d.html#11 IBM 4341
https://www.garlic.com/~lynn/2025c.html#101 More 4341
https://www.garlic.com/~lynn/2025c.html#98 5-CPU 370/125
https://www.garlic.com/~lynn/2025c.html#77 IBM 4341
https://www.garlic.com/~lynn/2025c.html#66 IBM 370 Workstation
https://www.garlic.com/~lynn/2025c.html#40 IBM & DEC DBMS
https://www.garlic.com/~lynn/2025c.html#15 Cluster Supercomputing
https://www.garlic.com/~lynn/2025c.html#12 IBM 4341
https://www.garlic.com/~lynn/2025b.html#72 Cluster Supercomputing
https://www.garlic.com/~lynn/2025b.html#67 IBM 23Jun1969 Unbundling and HONE
https://www.garlic.com/~lynn/2025b.html#44 IBM 70s & 80s
https://www.garlic.com/~lynn/2025b.html#37 FAA ATC, The Brawl in IBM 1964
https://www.garlic.com/~lynn/2025b.html#32 Forget About Cloud Computing. On-Premises Is All the Rage Again
https://www.garlic.com/~lynn/2025b.html#26 IBM 3880, 3380, Data-streaming
https://www.garlic.com/~lynn/2025b.html#22 IBM San Jose and Santa Teresa Lab
https://www.garlic.com/~lynn/2025b.html#8 The joy of FORTRAN
https://www.garlic.com/~lynn/2025.html#105 Giant Steps for IBM?
https://www.garlic.com/~lynn/2025.html#38 Multics vs Unix
https://www.garlic.com/~lynn/2025.html#26 Virtual Machine History
Some recent posts mentioning 4341 distributed computing posts
https://www.garlic.com/~lynn/2026.html#73 IBM 3033
https://www.garlic.com/~lynn/2026.html#36 IBM, NSC, HSDT, HA/CMP
https://www.garlic.com/~lynn/2026.html#10 4341, cluster supercomputing, distributed computing
https://www.garlic.com/~lynn/2025e.html#14 IBM DASD, CKD and FBA
https://www.garlic.com/~lynn/2025d.html#53 Computing Clusters
https://www.garlic.com/~lynn/2025d.html#11 IBM 4341
https://www.garlic.com/~lynn/2025c.html#101 More 4341
https://www.garlic.com/~lynn/2025c.html#77 IBM 4341
https://www.garlic.com/~lynn/2025c.html#40 IBM & DEC DBMS
https://www.garlic.com/~lynn/2025c.html#12 IBM 4341
https://www.garlic.com/~lynn/2025b.html#67 IBM 23Jun1969 Unbundling and HONE
https://www.garlic.com/~lynn/2025b.html#44 IBM 70s & 80s
https://www.garlic.com/~lynn/2025b.html#8 The joy of FORTRAN
https://www.garlic.com/~lynn/2025.html#105 Giant Steps for IBM?
https://www.garlic.com/~lynn/2025.html#38 Multics vs Unix
https://www.garlic.com/~lynn/2025.html#26 Virtual Machine History
https://www.garlic.com/~lynn/2025.html#7 Dataprocessing Innovation
https://www.garlic.com/~lynn/2024g.html#81 IBM 4300 and 3370FBA
https://www.garlic.com/~lynn/2024g.html#60 Creative Ways To Say How Old You Are
https://www.garlic.com/~lynn/2024g.html#55 Compute Farm and Distributed Computing Tsunami
https://www.garlic.com/~lynn/2024f.html#70 The joy of FORTH (not)
https://www.garlic.com/~lynn/2024f.html#64 Distributed Computing VM4341/FBA3370
https://www.garlic.com/~lynn/2024e.html#46 Netscape
https://www.garlic.com/~lynn/2024e.html#16 50 years ago, CP/M started the microcomputer revolution
https://www.garlic.com/~lynn/2024d.html#15 Mid-Range Market
https://www.garlic.com/~lynn/2024c.html#107 architectural goals, Byte Addressability And Beyond
https://www.garlic.com/~lynn/2024c.html#100 IBM 4300
https://www.garlic.com/~lynn/2024c.html#29 Wondering Why DEC Is The Most Popular
https://www.garlic.com/~lynn/2024b.html#45 Automated Operator
https://www.garlic.com/~lynn/2024b.html#43 Vintage Mainframe
https://www.garlic.com/~lynn/2024b.html#23 HA/CMP
https://www.garlic.com/~lynn/2024.html#65 IBM Mainframes and Education Infrastructure
https://www.garlic.com/~lynn/2024.html#64 IBM 4300s
https://www.garlic.com/~lynn/2024.html#51 VAX MIPS whatever they were, indirection in old architectures
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 4341 Date: 13 Mar, 2026 Blog: Facebookre:
Future System implodes and (besides ECPS) I get asked to help with 16-CPU multiprocessor and we con the 3033 processor engineers in working on it in their spare time (lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS") had (effective) 16-cpu support (MVS documentation had its 2-CPU support only getting 1.2-1.5 times throughput of single CPU system ... POK doesn't ship 16-CPU system until after turn of century). Head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, "heads down, and no distractions" (once 3033 processor is out the door, the processor engineers start on trout/3090).
Then I transfer out to SJR on west coast and gets to wander around datacenters in silicon valley, including disk bldg14/engineer and bldg15/product test across the street. They said they were running prescheduled, 7x24, stand-alone testing and had recently tried "MVS" but it had 15min MTBF (in that environment) requiring manual re-ipl. I offer to rewrite I/O supervisor to make it bullet proof and never fail, allowing any amount of concurrent, ondemand testing ... greatly improving productivity.
I'm also working with Jim Gray and Vera Watson on the original SQL/relational (System/R, all original work one on VM370) and joint study signed with BofA and they order 60 VM4341s for distributed operation. While the company was preoccupied with the next great DBMS, "EAGLE" ... managed to do tech transfer to Endicott for SQL/DS. Then when "EAGLE" implodes, there is request for how fast could System/R be ported to MVS ... which is eventually announced as DB2, originally for decision support only.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
System/R (original SQL/relational) posts
https://www.garlic.com/~lynn/submain.html#systemr
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM HONE Training Date: 14 Mar, 2026 Blog: FacebookAfter graduating and joined the IBM science center, one of my hobbies was enhanced production operating systems for internal datacenters, one of the 1st and long time customer was the sales and marketing support HONE systems. 23jun1969 unbundling included starting to charge for SE services. Up until then novice/trainee SEs were part of group on-site at customers ... but with unbundling, IBM couldn't figure out how to not charge for trainee SE services at the customer. Multiple HONE CP67 (virtual machine) datacenters were setup around the US with online access from branches where SEs would practice with guest operating systems in virtual machines. The science center also had redone APL\360 from 16kbyte swapped workspaces to large virtual memory demand page and APIs for system services (like file I/O), as CMS\APL for real world applications. HONE then started using CMS\APL for delivering sales&marketing support applications, which came to dominate all HONE activity (and SE working w/guest operating systems just withered away). I was then asked to do early non-US HONE CP/67 installs and then started having HONE systems sprouting up all over the world.
Early last decade, I was asked to track down decision to add virtual
memory to all 370s.
https://www.garlic.com/~lynn/2011d.html#73 Multiple Virtual Memory
Basically MVT storage management was so bad, that region sizes had to be specified four times larger than used. As a result, typical 1mbyte, 370/165 was capped at four concurrently executing regions (insufficient to keep 165 busy and justified). Going to MVT in 16mbyte virtual address space (similar to running MVT in a CP67 16mbyte virtual machine) allowed number of concurrent regions to be increased by a factor of four times (capped at 15 because of 4bit storage protect key) with little or no paging (VS2/SVS). Ludlow was doing initial VS2/SVS implementation on 360/67, a little bit of code to build virtual memory table and some simple paging. I would drop into and visit him periodically. Biggest problem was EXCP/SVC0 was now being passed channel programs with virtual addresses and channels required real addresses. He gets CP67 CCWTRANS (that implements making channel program copies, replacing virtual with real addresses, for virtual machines) hacked into EXCP.
trivia: by mid-70s, the US HONE datacenters had been consolidated in Palo Alto. When FACEBOOK 1st moved into Silicon Valley, it was into a new bldg built next door to the former consolidated US HONE datacenter.
Decision was also made to morph CP67->VM370 ... which simplified or dropped lots of features. I then started adding bunch of stuff (including kernel re-org for multiprocessor operation, but not the full SMP support) into VM370R2 for my internal CSC/VM. Then to upgrade CSC/VM to VM370R3-base, I also add SMP support, initially for HONE so they can upgrade their 370 158s and 168s to 2-CPU operation (getting twice throughput of 1-CPU operation).
Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Unbundling posts
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
SMP, tightly-coupled, shared-memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Adirondack Date: 15 Mar, 2026 Blog: Facebookre:
FS was completely different than 370 and was going to completely
replace it (internal politics during FS was killing off 370 efforts
and lack of new IBM 370 during FS is credited with giving the clone
370 system makers their market foothold). All during FS, I would
periodically ridicule FS, drawing analogy with a long playing cult
film down at Central Sq (which wasn't exactly career enhancing)
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
When FS implodes, there is mad rush to get stuff back into 370 product pipelines, including kicking off quick&dirty 3033 & 3081 efforts in parallel. Note: one of the last nails in the FS coffing was study by IBM Houston Scientific Center that if 370/195 apps were redone for FS system made out of the fastest available hardware technology, it would have throughput of 370/145 (about 30 times slowdown).
Also with FS implosion, I got asked to help with a 16-CPU 370 and we con the 3033 processor engineers into helping in their spare time (lot more interesting than rempapping 168-logic to 20% faster chips).. Everybody thot it was great until somebody tells the head of POK that it could be decades before POK favorite son operating system ("MVS") had (effective) 16-CPU mutliprocessor support (POK doesn't ship 16-CPU machine until after the turn of the century). At the time MVS documentation had 2-CPU support only getting 1.2-1.5 times the throughput of a 1-CPU (of the same model), aka MVS multiprocessor overhead so large. Then head of POK asks some of us to never visit POK again and directed 3033 processor engineers, heads down and no distractions (once the 3033 was out the door the processor engineers start on trout/3090).
3081 was going to be multiprocessor only. Initial 2-CPU 3081D had less aggregate MIPS than Amdhal 1-CPU. IBM doubles processor cache size bringing 3081K up to about same ggregate MIPS as Amdahl 1-CPU (although 3081K 2-CPU MVS multiprocessor throughput only about .6-.75 of Amdahl MVS 1-CPU, even with same aggregate MIPS).
Also ACP/TPF airlines/reservation only had support for single CPU systems and IBM was concerned the whole ACP/TPF market would go to the Amdahl 1-CPU. IBM then does some unnatural things to VM370 multiprocessor system tailored specifically for running ACP/TPF (single processor virtual machine) customers ... but it degrades system throughput 10-15% for the rest of VM370 multiprocessor customers. Then IBM tweaks 3270 terminal response partially masking overall multiprocessor throughput degradation. However, 3-letter gov agency CMS installation (back to 60s & CP67/CMS), then had 3081 2-CPU ... but wasn't interactive 3270, but high-speed (ASCII) glass teletype ... so the (3270) masking for ACP/TPF changes, didn't help.
I then get call asking if I could do anything for the gov agency (but not allowed to remove the changes for ACP/TPF). I then tweak CMS terminal support that improves interactive throughput about 30%, regardless of what the real terminal was (reducing Q1 interactive from 60/sec to 40/sec for same interactive). Including fixed a "bug" in VM370 where the scheduling was done based on virtual terminal type ... instead of the real terminal type (mismatch between virtual and real terminals, when the VM370 code was originally written, virtual & real terminals characteristics were similar and it was never fixed when there was huge mismatch between virtual & real).
3090 12Feb1985 (gone 404, but lives on at wayback machine)
https://web.archive.org/web/20230719145910/https://www.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP3090.html
A different 3-letter agency
https://web.archive.org/web/20090117083033/http://www.nsa.gov/research/selinux/list-archive/0409/8362.shtml
... note some of the MIT CTSS/7094 people went to the 5th flr and did MULTICS, others went to IBM Cambridge Science Center on the 4th flr (virtual machines, CP67-based science center wide-area network morphs into corporate internal network, GML morphs into SGML&HTML, etc) ... and IBM Boston Programming Center was on half of the 3rd flr. The other half of the 3rd flr was listed as a law firm on the directory ... but the 3rd flr telco closet was on the IBM side and one panel had "IBM" in large letters, the other panel had 3-letter gov. agency.
... after leaving IBM was doing a lot of stuff in the financial industry, including asked to be a financial industry standards rep ... which included some amount of crypto, and would require meetings with NIST and two 3-letter gov. agencies.
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Early EMAIL Date: 15 Mar, 2026 Blog: Facebookre:
MIT CTSS/7094 had form of email.
https://www.multicians.org/thvv/anhc-34-1-anec.html
Then some of the MIT CTSS/7094 people
went to the 5th flr for MULTICS. Others went to the IBM Cambridge
Scientific Center on 4th flr, virtual machines (wanted 360/50 to add
virtual memory, but all spare 50s were going to FAA/ATC so had to
settle for 360/40 to add virtual memory and do CP40/CMS, morphs into
CP67/CMS when 360/67 standard with virtual memory); CTSS interactive
apps, CTSS RUNOFF redone as CMS SCRIPT; CP67-based scientific center
wide-area network, invent GML in 1969 & GML tag support added to
SCRIPT (decade later morphs into ISO SGML and after another decade
HTML at CERN), etc.
One of the GML inventors hired to promote use of science center
wide-area network
https://web.archive.org/web/20230402212558/http://www.sgmlsource.com/history/jasis.htm
Actually, the law office application was the original motivation for
the project, something I was allowed to do part-time because of my
knowledge of the user requirements. My real job was to encourage the
staffs of the various scientific centers to make use of the
CP-67-based Wide Area Network that was centered in Cambridge.
... snip ...
Science Center wide-area network was larger than arpanet/internet from
the beginning (IBM transition internally from CP67/CMS->VM370/CMS and
morphs into the corporate network until about mid/late 80s when it was
forced into convert to SNA/VTAM); Technology also used for the
corporate sponsored univ BITNET
https://en.wikipedia.org/wiki/BITNET
Co-worker responsible
https://en.wikipedia.org/wiki/Edson_Hendricks
In June 1975, MIT Professor Jerry Saltzer accompanied Hendricks to
DARPA, where Hendricks described his innovations to the principal
scientist, Dr. Vinton Cerf. Later that year in September 15-19 of 75,
Cerf and Hendricks were the only two delegates from the United States,
to attend a workshop on Data Communications at the International
Institute for Applied Systems Analysis, 2361 Laxenburg Austria where
again, Hendricks spoke publicly about his innovative design which
paved the way to the Internet as we know it today.
... snip ...
newspaper article about some of Edson's Internet & TCP/IP IBM battles:
https://web.archive.org/web/20000124004147/http://www1.sjmercury.com/svtech/columns/gillmor/docs/dg092499.htm
Also from wayback machine, some additional (IBM missed, Internet &
TCP/IP) references from Ed's website
https://web.archive.org/web/20000115185349/http://www.edh.net/bungle.htm
History of Electronic Mail
https://www.multicians.org/thvv/mail-history.html
IBM CP/CMS had electronic mail as early as 1966, and was widely used
within IBM in the 1970s. Eventually this facility evolved into the
PROFS product in the 1980s.
Starting in the 60s, multiple different CMS email clients were appearing ... later adapting to 3270 full-screen. The PROFS group started collecting CMS apps for wrapping 3270 menu around and chose a very early version of VMSG as the email client. When the VMSG author tried to offer them a much enhanced version, the PROFS group tried to have him separated from the IBM company. The whole thing quieted down when he showed that his initials were in every PROFS email (in non-displayed field). After that he only shared his source with me and one other person.
Also got HSDT project early 80s, T1 and faster computer links (both
terrestrial and satellite) and battles with SNA group (60s, IBM had
2701 supporting T1, 70s with SNA/VTAM and issues, links were capped at
56kbit ... and had to mostly resort to non-IBM hardware). Also was
working with NSF director and was suppose to get $20M to interconnect
the NSF Supercomputer centers. Then congress cuts the budget, some
other things happened and eventually there was RFP released (in part
based on what we already had running). NSF 28Mar1986 Preliminary
Announcement:
https://www.garlic.com/~lynn/2002k.html#12
The OASC has initiated three programs: The Supercomputer Centers
Program to provide Supercomputer cycles; the New Technologies Program
to foster new supercomputer software and hardware developments; and
the Networking Program to build a National Supercomputer Access
Network - NSFnet.
... snip ...
IBM internal politics was not allowing us to bid. The NSF director tried to help by writing the company a letter (3Apr1986, NSF Director to IBM Chief Scientist and IBM Senior VP and director of Research, copying IBM CEO) with support from other gov. agencies ... but that just made the internal politics worse (as did claims that what we already had operational was at least 5yrs ahead of the winning bid), as regional networks connect in, NSFnet becomes the NSFNET backbone, precursor to modern internet.
Somebody was collecting internal SNA/VTAM misinformation email about
justification for converting internal network to SNA/VTAM as well as
using SNA/VTAM for NSFNET and forwarded it to us ... old archive post
(email heavily clipped and redacted to protect the guilty)
https://www.garlic.com/~lynn/2006w.html#email870109
Edson and I transfer to SJR on the west coast summer 1977 and I get to wander around datacenters in Silicon Valley. Also work with Jim Gray and Vera Watson on the original SQL/Relational, System/R. The corporation was pre-occupied with the next great DBMS, Eagle and was able to do tech transfer to Endicott for SQL/DS. Then when EAGLE implodes there was request for how fast could System/R be ported to MVS (eventually released as DB2, for decision-support *ONLY*).
Fall of 1980, Jim departs for Tandem. I had been blamed for online computer conferencing (via email distribution lists) on the internal network in late 70s and early 80s, but it really took off spring of 1981 when I distributed trip report to Jim and Tandem. Only about 300 were actively participating, but claims upwards of 25,000 were reading. We printed six copies of 300 pages, packaged them in six Tandem 3-ring binders (with executive summary and summary of the summary) and sent them to the corporate executive committee (claim was that 5of6 wanted to fire me).
Also in early 80s, I was introduced to John Boyd and would sponsor his
briefings. In 89/90, the Marine Corps Commandant leverages Boyd for
corps make-over. (at a time when IBM was desperately in need of
make-over) ... '92 IBM has one the largest losses in the history of US
companies and was being reorged into the 13 "baby blues" in
preparation for breakup of the company (take-off on "baby bells"
breakup a decade earlier).
https://web.archive.org/web/20101120231857/http://www.time.com/time/magazine/article/0,9171,977353,00.html
https://content.time.com/time/subscriber/article/0,33009,977353-1,00.html
We had already left IBM but get a call from the bowels of Armonk
asking if we could help with the breakup. Before we get started, the
board brings in the former AMEX president as CEO to try and save the
company, who (somewhat) reverses the breakup and uses some of the same
techniques used at RJR (gone 404, but lives on at wayback)
https://web.archive.org/web/20181019074906/http://www.ibmemployee.com/RetirementHeist.shtml
Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
bitnet posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
HSDT posts
https://www.garlic.com/~lynn/subnetwork.html#hsdt
NSFNET posts
https://www.garlic.com/~lynn/subnetwork.html#nsfnet
internet posts
https://www.garlic.com/~lynn/subnetwork.html#internet
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
John Boyd posts and/or WEB URLs
https://www.garlic.com/~lynn/subboyd.html
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
pension posts
https://www.garlic.com/~lynn/submisc.html#pension
other some recent email related
https://www.garlic.com/~lynn/2026.html#19 IBM Online Apps, Network, Email
https://www.garlic.com/~lynn/2026.html#5 PROFS and other CMS applications
https://www.garlic.com/~lynn/2025c.html#113 IBM VNET/RSCS
https://www.garlic.com/~lynn/2024f.html#44 PROFS & VMSG
https://www.garlic.com/~lynn/2023c.html#5 IBM Downfall
https://www.garlic.com/~lynn/2015h.html#66 IMPI (System/38 / AS/400 historical)
https://www.garlic.com/~lynn/2014b.html#105 Happy 50th Birthday to the IBM Cambridge Scientific Center
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CP/67 and VM/370 Date: 16 Mar, 2026 Blog: FacebookAs undergraduate, I had taken 2 credit hr to fortran/computers. At the end of semester, I was hired to rewrite 1401 MPIO in 360 assembler for 360/30. Univ was getting 360/67 for tss/360, replacing 709/1401 and got 360/30 temporarily replacing 1401 until 360/67 was available. Univ. shutdown datacenter on weekends and I had it dedicated for the weekend (although 48hrs w/o sleep made monday classes hard). I was given pile of software and hardware manuals and got to design and implement my own monitor, device drivers, interrupt handlers, error recovery, storage management, etc and within a few weeks had 2000 card program. Within a year of taking intro class, 360/67 arrives and I was hired fulltime responsible for os/360 (tss/360 didn't come to production).
709 did student fortran in under a second, initially OS/360 took over minute. I install HASP and it cuts time in half. I then start redoing SYSGEN STAGE2, carefully placing datasets and PDS members to optimize arm seek and multi-track search, cutting another 2/3rds to 12.9secs. 360/67 never got better than 709 until I install UofWaterloo WATFOR. WATFOR clocked on 360 65/67 at 20,000 cards/min (333 cards/sec) and student Fortran ran 30-60 cards/job.
IBM CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 CP/67 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
Then before I graduate, I was hired into small group in Boeing CFO office to help with formation of Boeing Computer Services, consolidating all dataprocessing into an independent business unit. I think Renton was the largest IBM datacenters with 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around the machine room. Lots of politics between Renton director and CFO who only had a 360/30 up at Boeing field for payroll (although they enlarge it to install 360/67 for me to play with when I wasn't doing other stuff).
23jun1969 unbundling announce started to charge for (application) software (managed to make the case that kernel software should still be free), SE services, maint, etc.
Then when I graduate, I join IBM CSC (instead of staying with Boeing CFO) and one of my hobbies was enhanced production operating systems for internal datacenters and HONE was one of the first (and long time) customer. SE training used to be part of group onsite at customer. However, IBM couldn't figure out how to NOT charge for trainee SEs onsite at customer. Solution was several CP67 datacenters around US where branch office SEs would logon and practice with guest operating systems running in virtual machines. CSC had also ported APL\360 to CMS as CMS\APL (redoing workspaces from small 16kbyte swapped to large virtual memory demand page and also API for system services like file I/O ... enabling lots of real world applications). HONE then starts doing CMS\APL-based sales&marketing support applications ... which come to dominate all HONE activity (and guest operating system practice fades away).
Early last decade, I was asked to track down decision to add virtual memory to all 370s. Basically MVT storage management was so bad, that region sizes had to be specified four times larger than used. As a result, typical 1mbyte, 370/165 was capped at four concurrently executing regions (insufficient to keep 165 busy and justified). Going to MVT in 16mbyte virtual address space (similar to running MVT in a CP67 16mbyte virtual machine) allowed number of concurrent regions to be increased by a factor of four times (capped at 15 because of 4bit storage protect key) with little or no paging (VS2/SVS). Ludlow was doing initial VS2/SVS implementation on 360/67, a little bit of code to build virtual memory table and some simple paging. I would drop into and visit him periodically. Biggest problem was EXCP/SVC0 was now being passed channel programs with virtual addresses and channels required real addresses. He gets CP67 CCWTRANS (that implements making channel program copies, replacing virtual with real addresses, for virtual machines) hacked into EXCP.
Part of 370 virtual memory was decision to redo CP67/CMS for VM370/CMS and lots of stuff was simplified and/or dropped (including multiprocessor support and "wheeler" scheduler I had done as undergraduate). Then with a VM370R2-base, I start adding lots of stuff back in (including "wheeler" scheduler and kernel re-org needed for multiprocessor) for my internal CSC/VM. Then upgrade CSC/VM to VM370R3-base and add more stuff back in, including multiprocessor support (originally for HONE so they could upgrade their 158s & 168s to 2-CPU, 2-CPU getting twice throughput of single CPU).
This was about the time Future System was imploding and there was decision to do 16-CPU multiprocessor and I got asked to help (in part for having done 2-CPU for HONE getting twice throughput) ... and we ask the 3033 processor engineers into helping in their spare time (lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("MVS", MVS docs had 2-CPU getting 1.2-1.5 throughput of single CPU) for decades (POK doesn't ship 16-CPU systems until after turn of century). Head of POK then tells some of us to never visit POK again and directs the 3033 processor engineers, heads down and no distractions.
Not long later, I transfer out to SJR on the west coast and get to wander around datacenters in Silicon Valley, including disk bldg14/engineering and bldg15/product test across the street.
Cambridge Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Dynamic Adaptive "wheeler" scheduler posts
https://www.garlic.com/~lynn/subtopic.html#fairshare
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
SMP, tightly coupled, shared memory multiprocessor posts
https://www.garlic.com/~lynn/subtopic.html#smp
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CP/67 and VM/370 Date: 16 Mar, 2026 Blog: Facebookre:
FS was completely different than 370 and was going to completely
replace 370, internal politics during FS was killing off 370 efforts,
which is credited the lack of new IBM 370 with giving the clone 370
system makers is given their market foothold.
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
there was mad rush to get stuff back into the 370 product pipelines, including kick off the quick&dirty 3033&3081
The head of POK then was convincing corporate to kill the VM370 product, shutdown the development group and transfer all the people to POK for MVS/XA. They weren't going to tell the people until the very last minute to minimize those that might escape. The information managed to leak early and some managed to escape (DEC VMS was in very early development and joke was that the head of POK was major contributor to VMS). There was hunt for the source of the leak, fortunately for me nobody gave leak up. Endicott eventually managed to acquire the VM370 product mission, but had to recreate a development group from scratch.
When FS imploded, Endicott talks me into working on 138/148 ECPS
microcode assist (also used for 4331/4341) ... needed to identify
highest executed 6kbytes for 370 kernel code ... accounted for 79.55%
and redone for microcode on approx 1:1 basis giving 10:1
speedup. Archived post with initial analysis for ECPS
https://www.garlic.com/~lynn/94.html#21
I was also talked into helping with 16-CPU multiprocessor and we con the 3033 processor engineers into help in their spare time (lot more interesting than remapping 168 logic to 20% faster chips). Everybody thought it was really great until somebody tells head of POK that it could be decade that it would take POK's favorite son operating system ("MVS") had (effective) 16-CPU son multiprocessor support (MVS docs had 2-CPU support only did 1.2-1.5 times throughput of 1-CPU ... ineffective SMP implementation; POK doesn't ship 16-CPU SMP until after the turn of century). Head of POK then invites some of us to never visit POK again and directs 3033 processor engineers, heads down and no distractions (once 3033 was out the door, the processor engineers start on trout/3090).
MVS problems shows up even more with 3081 which was only going to be SMP system and 2-CPU 3081D was lower aggregate MIPs than 1-CPU Amdahl. IBM doubles the 3081 processor caches for the 3081K for about the same aggregate MIPS as 1-CPU Amdahl. However, because MVS inefficient SMP, it would only be about .6-.75 throughput of MVS 1-CPU Amdahl (even though approx. same aggregate MIPS).
Note US 23jun1969 unbundling announce, IBM starts to charge for (application) software (made the case that kernel software should still be free), SE services, maint, etc. SE training had included as part of group on customer site, but with unbundling they couldn't figure out how not to charge for trainee SEs onsite at customer. Eventually they decide to deploy several CP67/CMS "HONE" systems around the US where branch office SEs could login and practice with guest operating systems running in virtual machines.
One of my hobbies after graduating and joining IBM Cambridge Science Center was enhanced production operating systems for internal datacenters and HONE was one of my 1st (and longtime) customers. When decision was made to add virtual memory to all 370s, decision was morph CP67->VM370, but they simplified or dropped lots of stuff (including my dynamic adaptive "wheeler" scheduler and multiprocessor support). I start with VM370R2 for my internal CSC/VM, starting to put a lot of stuff back in, my scheduler, kernel re-org needed for multiprocessor support, etc. I then do VM370R3-base and put back in multiprocessor support ... initially for HONE so they can upgrade their 1-CPU systems to 2-CPU systems (getting twice throughput of their single CPU systems).
After head of POK got the VM370 product killed, development group shutdown, etc ... they sent out POK executives to make rounds of internal datacenters to strong arm internal datacenters to move off VM370 to MVS. HONE created quite an uproar.
posts mentioning unbundling
https://www.garlic.com/~lynn/submain.html#unbundle
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
SMP, tightly-coupled, shared memory multiprocessor
https://www.garlic.com/~lynn/subtopic.html#smp
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CP/67 and VM/370 Date: 16 Mar, 2026 Blog: Facebookre:
Melinda story ... after 16-CPU multiprocessor was torpedoed, transfer
out to SJR on west coast and fall1982, SJR did 1st IBM gateway to
BITNET
https://en.wikipedia.org/wiki/BITNET
Melinda sent me a email request, asking for the original implementation of multi-level source update. For adding virtual memory to all 370s (in parallel with the new VM370 development group), we add CP67L option (running on 360/67) supporting 370 virtual memory virtual machines (as CP67H) and then add support for CP67 running on (virtual) 370 (CP67I). Standard mode on Cambridge real 360/67.
CP67L running on 360/67 CP67H running in CP67L virtual machine CP67I running in CP67H 370 virtual memory virtual machine CMS running in 370 virtual machine
Four levels was in regular production use a year before the 1st
engineering 370 w/virtual memory was operational, the extra layer of
CP67L on the real machine was extra security because profs, staff,
students from Boston area institutions were using Cambridge system and
370 virtual memory wasn't announced (CP67I was in fact used as test
for the 1st virtual memory engineering 370). Then three people from
San Jose came out and add 3330 & 2305 device support to CP67I for
CP67SJ ... which was in production use on real virtual memory 370s
long after VM370 was running. Old archived posts with email:
https://www.garlic.com/~lynn/2006w.html#email850906
https://www.garlic.com/~lynn/2006w.html#email850906b
https://www.garlic.com/~lynn/2006w.html#email850908
Melinda's timing was fortunate. I had half dozen archive tapes from
the 70s in the Almaden tape library and couple weeks later, they had
an operational problem where random tapes were being mounted as
"scratch" and I lost the batch.
I never had pony tail ... but when I 1st joined IBM, I drank the kool-aid wore 3-piece suits. I would get to attend user group meetings and drop by customers. Director of one of the largest customer financial datacenters liked me to stop by and talk technology. At one point the IBM branch manager horribly offended the customer and in retaliation, they ordered an Amdahl machine (lonely Amdahl in vast sea of IBM). This was in early 70s and Amdahl had been selling into science, technology, university market ... and this would be 1st in true-blue commercial market. I was asked to go onsite for 6-12 months (somewhat obfuscate the reason for the Amdahl order). I talk it over with the customer and decline IBM's offer. I was then told that the branch manager was good sailing buddy of IBM CEO and if I didn't, I could forget career, promotions, raises. I gave up 3-piece suits ... and got comments that it was nice to see somebody other than empty suits
Cambridge Science Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CP/67 and VM/370 Date: 16 Mar, 2026 Blog: Facebookre:
Transfer out to SJR on west coast, worked with Jim Gray and Vera Watson on original SQL/Relational, System/R (developed on VM370). While company was preoccupied with next great DBMS ("EAGLE"), was able to do tech transfer to Endicott for SQL/DS. Then when "EAGLE" implodes there is request for how fast could System/R be transferred to MVS which is eventually released as DB2 (for decision-support only).
I also got to wander around datacenters in Silicon Valley, including disk bldg14/engineering and bldg15/product test across the street. They were doing pre-scheduled, 7x24, stand-alone testing and mentioned they had recently tried MVS, but it had 15min MTBF (requiring manual re-ipl) in that environment. I offer to rewrite I/O supervisor to make it bullet proof and never fail, allowing any amount of ondemand, concurrent testing, greatly improving productivity. Downside was they got use to me diagnosing their problems.
Jim leaves IBM for Tandem fall of 1980. I was being blamed for online computer conferencing on the IBM internal network, it didn't really take off until I distribute a trip report to see Jim at Tandem, spring of 1981. Only about 300 actively participated, but claims that 25,000 were reading. We print six copies of 300 pages and packaged in Tandem 3-ring binders sent to the corporate executive committee (supposedly 5of6 wanted to fire me).
Bldg15 get 1st engineering 3033 outside POK processor engineering. Testing only took percent or two of CPU so we scavenge up 3830 controller and 3330 string, setting up our own private online service. Then summer 1978, get engineering 4341 (year before first customer ship). Branch office hears about it and cons me into doing benchmark for national lab that was looking at getting 70 for compute farm (sort of leading edge of the coming cluster supercomputing tsunami). BofA signs joint study for System/R and when VM/4341s become available, orders 60 for distributed deployment. Then early 80s, large corporations start ordering hundreds of VM/4341s at a time for distribution out in departmental areas (sort of leading edge of the coming departmental distributed computing tsunami). Inside IBM, departmental conference rooms became in short supply because so many had been converted to VM/4341 rooms. Also showed, small cluster of VM/4341s had much better price/performance, much smaller aggregate footprint, power, cooling (besides much larger cluster supercomputing and price/performance drops below threshold)
MVS looked at the explosion with departmental computing and wanted part of the market. Only new CKD was datacenter 3380 and the only non-datacenter was FBA3370. Eventually they come out with CKD emulation on 3370 as 3375. However it didn't do them much good, distributed computing was doing scores of VM/4341s per support staff while MVS was still scores of staff per MVS.
trivia: 1988, Nick Donofrio approves HA/6000, originally for NYTimes
to migrate their newspaper system (ATEX) off DEC VAXCluster to
RS/6000. I rename it HA/CMP
https://en.wikipedia.org/wiki/IBM_High_Availability_Cluster_Multiprocessing
when I start doing (technical/scientific) cluster scale-up with
national labs (LANL, LLNL, NCAR, etc) and commercial cluster scale-up
with RDBMS vendors (Oracle, Sybase, Ingres, Informix) with VAXCluster
support in same source base with UNIX
Early Jan92, there was meeting with Oracle CEO and IBM/AWD executive
Hester tells Ellison that we would have 16-system clusters by mid92
and 128-system clusters by ye92. Mid-jan92, I update FSD on HA/CMP
work with national labs and FSD decides to go with HA/CMP for federal
supercomputers. By end of Jan, we are told that cluster scale-up is
being transferred to Kingston for announce as IBM Supercomputer
(technical/scientific *ONLY*) and we aren't allowed to work with
anything that has more than four systems (we leave IBM a few months
later). A couple weeks later, 17feb1992, Computerworld news ... IBM
establishes laboratory to develop parallel systems (pg8)
https://archive.org/details/sim_computerworld_1992-02-17_26_7
Some speculation that it would have eaten the mainframe in the
commercial market. 1993 industry benchmarks (number of program
iterations compared to the industry MIPS/BIPS reference platform):
ES/9000-982 : 8CPU 408MIPS, (51MIPS/CPU)
RS6000/990 (RIOS chipset) : (1-CPU) 126MIPS, 16-systems: 2BIPS,
.... 128-systems: 16BIPS
Executive we reported to goes over to head of Somerset/AIM (Apple,
IBM, Motorola) to do single chip 801/RISC (Power/PC) and uses Motorola
88k bus/cache enabling multiprocessor implementations (and large
clusters of multiprocessor systems).
System/R posts
https://www.garlic.com/~lynn/submain.html#systemr
getting to play disk engineer posts
https://www.garlic.com/~lynn/subtopic.html#disk
online computer conferencing posts
https://www.garlic.com/~lynn/subnetwork.html#cmc
internal network posts
https://www.garlic.com/~lynn/subnetwork.html#internalnet
HA/CMP posts
https://www.garlic.com/~lynn/subtopic.html#hacmp
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: CP67/CMS, CMS\APL, HONE, VM370/CMS Date: 18 Mar, 2026 Blog: FacebookAfter taking two credit hr intro to fortran/computers, i was hired fulltime responsible for OS/360 after 360/67 arrived replacing 709/1401 for tss/360 but tss never came to production. 709 student fortran ran in under second, initially ran over minute on 360. I install HASP and it cuts time in half. Then I start redoing MFT11 STAGE2 SYSGEN to carefully place datasets and PDS members to optimize arm seek and multi-track search cutting another 2/3rds to 12.9secs. 360 never got better than 709 until I install UofWaterloo WATFOR. WATFOR clocked at 20,000 cards/min on 360/65(67), 333 cards/sec ... student fortran tended to run 30-60 cards.
Then IBM CSC came out to install (virtual machine) CP/67 (3rd installation after CSC itself and MIT Lincoln Labs). I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher, (dynamic adaptive resource manager/default fair share policy) scheduler, paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP67 arrived with 1052&2741 (selectric) terminal support (and able to
switch standard typeball with APL typeball) and could dynamically
change port terminal type scanner. Univ. had (ASCII) TTY33&TTY35
terminals and I added support including being able to dynamically
change port terminal type. I then wanted to have single dial-up number
for all terminal types ("hunt group"), but didn't quite work (IBM had
hard-wired each port line-speed). This starts out project to do clone
telecommunication controller, build a channel interface board for
Interdata/3 programmed to emulate IBM controller with the addition of
dynamic baud. It was then upgraded with Interdata/4 with channel
interface and clusters of Interdata3s for port interfaces. Interdata
(and then Perkin-Elmer) was selling it as clone controller
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
... and four of us are written up responsible for (some part of) IBM
clone controller business
Before I graduate, I was hired fulltime into small group in Boeing CFO office to help with formation of Boeing Computing Services (consolidate all dataprocessing into independent business unit). I think Renton datacenter is largest in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Lots of politics between Renton director and CFO who only had 360/30 up at Boeing field for payroll (although they enlarge the room to install 360/67 for me to play with when I wasn't doing other stuff).
When I graduate, I join IBM CSC (instead of staying with CFO) and one of my hobbies was enhanced production operating systems for internal datacenters (& HONE was one of my first and long time customers)
US IBM 23Jun1969 unbundling announce started to charge for (application) software (manage to make case that kernel software should still be free), SE services, maint, etc. SE training had been part of group at customer datacenter ... but IBM couldn't figure out how *NOT* to charge for trainee SEs at customer location. Eventually it was decided on several US "HONE" CP67 datacenters so branch office SEs can login and practice with guest operating systems running in virtual machines. CSC had also ported APL\360 to CP67/CMS as CMS\APL, redoing storage management from 16kbyte swapped workspaces to large virtual memory demand paged workspaces and API for system services (like file I/O) enabling real-world applications. Then HONE started deploying CMS\APL-based sales&marketing support applications which came to dominate all HONE activity (and guest operating system practice just withered away). As HONE (initially CP67/CMS moving to VM370/CMS) datacenters propagated around the world, easily became the largest use of APL.
Cambridge Scientific Center posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Plug-compatible, clone controller posts
https://www.garlic.com/~lynn/submain.html#360pcm
IBM 23Jun1969 unbundling posts
https://www.garlic.com/~lynn/submain.html#unbundle
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: Work at 55 Water St. Date: 22 Mar, 2026 Blog: Facebooknot exactly, after leaving IBM early 90s, for decade starting mid-90s, was rep to the financial industry standards body along with a rep from NSCC (before merger with DTC forming DTCC, both located at 55 Water).
The NSCC rep asked me if I would look at improving the integrity of trading transactions. I work on it for awhile and then get a call saying the work is being suspended because a side effect of the improved integrity would have greatly increased transaction visibility and transparency (which was antithetical to wallstreet culture).
a few posts posts referencing NSCC integrity work
https://www.garlic.com/~lynn/2017f.html#26 [CM] What was your first home computer?
https://www.garlic.com/~lynn/2016f.html#40 Misc. Success of Failure
https://www.garlic.com/~lynn/2015h.html#29 Ernst & Young Confronts Madoff's Specter in Trial Over Audits
https://www.garlic.com/~lynn/2015g.html#16 Federal Deficits
https://www.garlic.com/~lynn/2015e.html#47 Do we REALLY NEED all this regulatory oversight?
https://www.garlic.com/~lynn/2015d.html#31 Bernie Sanders Proposes A Bill To Break Up The 'Too Big To Exist' Banks
https://www.garlic.com/~lynn/2015.html#58 IBM Data Processing Center and Pi
https://www.garlic.com/~lynn/2015.html#54 How do we take political considerations into account in the OODA-Loop?
https://www.garlic.com/~lynn/2015.html#17 Cromnibus cartoon
https://www.garlic.com/~lynn/2014l.html#84 Uncovering insider trading with big data
https://www.garlic.com/~lynn/2014f.html#20 HFT, computer trading
https://www.garlic.com/~lynn/2014e.html#72 Three Expensive Milliseconds
https://www.garlic.com/~lynn/2014d.html#7 N.Y. Barclays Libor Traders Said to Face U.K. Charges
https://www.garlic.com/~lynn/2013h.html#30 'Big four' accountants 'use knowledge of Treasury to help rich avoid tax'
https://www.garlic.com/~lynn/2012o.html#63 Is it possible to hack mainframe system??
https://www.garlic.com/~lynn/2012e.html#57 speculation
https://www.garlic.com/~lynn/2012e.html#23 Are mothers naturally better at OODA because they always have the Win in mind?
https://www.garlic.com/~lynn/2012.html#5 We are on the brink of a historic decision [referring to defence cuts]
https://www.garlic.com/~lynn/2011n.html#49 The men who crashed the world
https://www.garlic.com/~lynn/2011n.html#30 Have you ever wondered why some people seem to get rich easily
https://www.garlic.com/~lynn/2011n.html#24 AMERICA IS BROKEN, WHAT NOW?
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM Downfall Date: 23 Mar, 2026 Blog: Facebookre:
After leaving IBM, we got email from a number of IBMers complaining that top executives weren't paying attention to running the business, but were spending all their time moving expenses from the following year to the current year. We ask our contact in the bowels of Armonk about it. Reply was that no matter how far into the red, there would be no executive bonuses for the current year ... but if they could just nudge the following year into the black ... the way the executive bonus was written, they would get bonus more than twice as large as any previous bonus (in effect reward for taking the company into the red).
IBM downturn/downfall/breakup posts
https://www.garlic.com/~lynn/submisc.html#ibmdownfall
Past references to that executive bonus
https://www.garlic.com/~lynn/2023c.html#84 Dataprocessing Career
https://www.garlic.com/~lynn/2023c.html#16 IBM Downfall
https://www.garlic.com/~lynn/2023b.html#74 IBM Breakup
https://www.garlic.com/~lynn/2022g.html#57 IBM changes to retirement benefits
https://www.garlic.com/~lynn/2022f.html#106 IBM Downfall
https://www.garlic.com/~lynn/2022f.html#84 Demolition of Iconic IBM Country Club Complex "Imminent"
https://www.garlic.com/~lynn/2022f.html#11 9 Mainframe Statistics That May Surprise You
https://www.garlic.com/~lynn/2022d.html#54 Another IBM Down Fall thread
https://www.garlic.com/~lynn/2021j.html#70 IBM Wild Ducks
https://www.garlic.com/~lynn/2021f.html#47 Martial Arts "OODA-loop"
https://www.garlic.com/~lynn/2021f.html#24 IBM Remains Big Tech's Disaster
https://www.garlic.com/~lynn/2021b.html#7 IBM & Apple
https://www.garlic.com/~lynn/2019d.html#70 Decline of IBM
https://www.garlic.com/~lynn/2017g.html#105 Why IBM Should -- and Shouldn't -- Break Itself Up
https://www.garlic.com/~lynn/2017b.html#43 when to get out???
https://www.garlic.com/~lynn/2015.html#81 Ginni gets bonus, plus raise, and extra incentives
https://www.garlic.com/~lynn/2014c.html#69 IBM layoffs strike first in India; workers describe cuts as 'slaughter' and 'massive'
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 360&370 Experience Date: 26 Mar, 2026 Blog: Facebook60s took two credit hr college intro to fortran/comuters. At the end of the semester, I was hired to re-implement 1401 MPIO in assembler for 360/30. Univ. was getting 360/67 for TSS/360 replacing 709/1401 and got 360/30 temporarily until availability of 360/67s. Univ. shutdown datacenter on weekends and I got the whole place dedicated (although 48hrs w/o sleep made Monday classes hard). I was given pile of hardware & software manuals and got to design and implement my own monitor, device drivers, interrupt handlers, error recovery, storage management, etc ... and within a few weeks had 2000 card 360/30 assembler program
360/67 arrived within year of taking intro class and I was hired fulltime responsible for os/360 (tss/360 never came to fruition). 709 did student fortran in less than second, but 360/67 os/360 took over minute. I install HASP for MFT9.5 cutting time in half. I then start redoing MFT11 SYSGEN STAGE2 carefully placing datasets and PDS members optimizing arm seek and multi-track search cutting another 2/3rds to 12.9secs. 360/67 never got better than 709 until I install UofWaterloo WATFOR, clocked on 360/67 at 20,000 cards/min (333 cards/sec ... student fortran tended to run 30-60cards/job).
Then CSC came out to install (virtual machine) CP/67 (3rd after CSC itself and MIT Lincoln Labs) and I mostly get to play with it during my weekend 48hr window. I then spend a few months rewriting pathlengths for running OS/360 in virtual machine. Bare machine test ran 322secs ... initially 856secs (CP67 CPU 534secs). After a few months I had CP67 CPU down from 534secs to 113secs. I then start rewriting the dispatcher/scheduler , (dynamic adaptive resource manager/default fair share scheduling policy), paging, adding ordered seek queuing (from FIFO) and mutli-page transfer channel programs (from FIFO and optimized for transfers/revolution, getting 2301 paging drum from 70-80 4k transfers/sec to channel transfer peak of 270). Six months after univ initial CP/67 install, CSC was giving one week class in LA. I arrive on Sunday afternoon and asked to teach the class, it turns out that the people that were going to teach it had resigned the Friday before to join one of the 60s CSC CP67 commercial online spin-offs.
CP/67 arrived with 1052&2741 terminal support and auto-terminal ident,
capable switching terminal type scanner type for each port. Univ. also
had TTY33&35 and I add ASCII support integrated with auto-terminal
type. I then want to have single dial-in number (hunt group) for all
terminals. Didn't quite work, IBM had hard-wired line speed ... so we
start a clone terminal controller. Build a IBM channel interface board
for Interdata/3 programmed to emulate IBM controller with the addition
for auto-baud. Then upgraded with Interdata/4 for channel interface
and cluster of Interdata/3s for port interfaces. Interdata (and later
Perkin-Elmer) sell them as clone controllers.
https://en.wikipedia.org/wiki/Interdata
https://en.wikipedia.org/wiki/Perkin-Elmer#Computer_Systems_Division
... and four of us are written up responsible for (some part of) clone
controller business
I implement CRJE function in HASP for MVTR18 with editor that implements CMS EDIT syntax.
Before I graduate, I'm hired fulltime into small group in Boeing CFO office to help with formation of Boeing Computer Services (consolidate all dataprocessing into independent business unit). I think Renton largest datacenter in the world, 360/65s arriving faster than they could be installed, boxes constantly staged in hallways around machine room. Lots of politics between Renton director and CFO, who only had a 360/30 up at Boeing Field for payroll, although they enlarge the room to install 360/67 for me to play with when I wasn't doing other stuff. 747-3 was flying skies of Seattle getting FAA flt certification. Mock-up of 747 cabin just south of Boeing field and tours would claim 747s had so many people they would never have fewer than four jetways.
Boeing Huntsville had got a 2-CPU 360/67 with several 2250 graphic displays for TSS/360 CAD/CAM (but tss/360 wasn't production), so configured as two MVTR13 systems. They ran into same problems that resulted in decision to add virtual memory to all 370s and modified MVTR13 to run in virtual memory mode (but w/o paging).
Early last decade I was asked to track down decision to add virtual memory to all 370s. Basically MVT storage management was so bad that region sizes had to be specified four times larger than used, limit standard 1mbyte, 370/165 to four concurrent running regions, insufficient to keep system busy and justified. Running MVT in 16mbyte virtual address space (similar to running MVT in a 360/67, CP/67 16mbyte virtual machine) allowed number of concurrent regions to be increased by factor of four times (capped at 15 concurrent regions because of 4bit storage protect key) with little or no paging.
When I graduate, I joined the IBM Cambridge Scientific Center (instead of staying w/CFO) and one of my hobbies was enhanced production operating systems for internal datacenters. Online sales&marketing support HONE system was one of the 1st (and long time) customers. Ludlow was doing the initial implementation of MVT->VS2/SVS on 360/67 (until engineering 370 with virtual memory) and I would drop by periodically. He had a little bit of code for the 16mbyte virtual address space tables and some simple paging. Biggest task was channel programs passed to EXCP/SVC0 now had virtual addresses and channels required real addresses and he borrows CP67's CCWTRANS for integrating into EXCP (creating channel program copies, replacing virtual with real addresses).
Some of CSC went to 3rd flr, taking over IBM Boston Programming Center
for the VM370 development center. In parallel some of us still in CSC
modified CP67 to simulate 370 virtual machines as CP67H. We then
modified CP67H for CP67I running on 370 architecture. For a year
before virtual memory engineering 370 machine was operational, CSC ran
CP67L on real machine
CP67H in CP67L 360/67 virtual machine
CP67I in CP67H 370 virtual machine
The extra use of CP67L on the CSC 360/67 was because the system also
had Boston area education institution staff, professors, and students
(and before 370 virtual memory was even announced). Then three
engineers from San Jose came out and added 3330&2305 device support to
CP67I for CP67SJ. CP67SJ was wide-spread production internally well
after VM370R1 was available.
Some of the MIT CTSS/7094 people had gone to the 5th flr to do
Multics, other go to the 4th flr initially forming IBM CSC doing
virtual machines (initially wanted 360/50 adding hardware virtual
memory but all the spare 360/50s were going to FAA/ATC project and so
had to settle for 360/40 to add virtual memory and doing CP40/CMS;
then when 360/67 standard with virtual memory is available, CP40/CMS
morphs into CP67/CMS, precursor to VM370/CMS). CTSS RUNOFF is redone
for CMS as SCRIPT. After GML (precursor to SGML & HTML) is invented at
CSC in 1969, GML tag processing is added to SCRIPT. One of the 1st
mainstream IBM pubs done in script is the 370 architecture REDBOOK for
distribution in RED 3-ring binder (command line option generates
either the full REDBOOK or the 370 principles of operation
subset). Also the science center wide-area network (morphs into the
internal coporate network, larger than arpanet/internet from the
beginning until sometime mid/late 80s about the time it was forced
into converting to SNA/VTAM); also used for the corporate sponsored
univ BITNET
https://en.wikipedia.org/wiki/BITNET
HASP/JES2, ASP/JES3, NJI/NJE posts
https://www.garlic.com/~lynn/submain.html#hasp
Clone, plug-compatible telecommunication controller
https://www.garlic.com/~lynn/submain.html#360pcm
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
HONE posts
https://www.garlic.com/~lynn/subtopic.html#hone
internal network
https://www.garlic.com/~lynn/subnetwork.html#internalnet
GML, SGML, HTML posts
https://www.garlic.com/~lynn/submain.html#sgml
BITNET posts
https://www.garlic.com/~lynn/subnetwork.html#bitnet
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 360&370 Experience Date: 26 Mar, 2026 Blog: Facebookre:
Machines & systems were getting larger and needed to move past (4bit storage protect key) 15 concurrent region limit and started giving each region its own 16mbyte virtual address space (VS2/MVS), however OS/360 ancestry was heavily pointer-passing API, and so mapped an 8mbyte image of the VS2/MVS kernel into every address space (leaving 8mbytes). Then every subsystem went to their own 16mbyte virtual address space and for passing info to/from subsystem calls, mapped a one mbyte "Common Segment Area" into every address space, leaving 7mbytes. Common Area requirement somewhat proportional to number of concurrent regions and subsystems ... and by 3033, common area exploded to 5-6mbytes as Common System Area leaving 3-2mbytes (and threatening to become 8mbyte CSA, leaving zero) .... part of VS2/MVS desperate need getting to 370/XA and MVS/XA.
Overlapping the start of VS2/MVS, was the "Future System" totally
different than 370 and going to completely replace (including single
level store, similar to MULTICS and TSS/360). Internal politics was
killing off 370 efforts (lack of new 370 products during FS is
credited with giving the 370 clone system makers their market
foothold). When FS finally implodes there was mad rush to get stuff
back into the 370 product pipelines, including kicking off the quick
dirty 3033&3081 projects in parallel. Future System disaster, from
"Computer Wars: The Post-IBM World"
https://www.amazon.com/Computer-Wars-The-Post-IBM-World/dp/1587981394/
... and perhaps most damaging, the old culture under Watson Snr and Jr
of free and vigorous debate was replaced with *SYNCOPHANCY* and *MAKE
NO WAVES* under Opel and Akers. It's claimed that thereafter, IBM
lived in the shadow of defeat ... But because of the heavy investment
of face by the top management, F/S took years to kill, although its
wrong headedness was obvious from the very outset. "For the first
time, during F/S, outspoken criticism became politically dangerous,"
recalls a former top executive
... snip ...
One of the last nails in the FS coffin was study by the IBM Houston
Scientific Center; redo 370/195 applications for a FS machine made out
of the fastest available hardware technology, would have throughput of
370/145 (slowdown something like 30 times). Also claims that any other
company with loss/failure the magnitude of FS would have gone
bankrupt; more FS:
http://www.jfsowa.com/computer/memo125.htm
https://en.wikipedia.org/wiki/IBM_Future_Systems_project
https://people.computing.clemson.edu/~mark/fs.html
The VM370 development group in morph of CP67->VM370 simplified or dropped lots of stuff (including "wheeler" scheduler and multiprocessor support). I start adding a bunch of stuff back into a VM370R2-base for my internal CSC/VM (including kernel re-org needed for multiprocessor support). Then upgrade to internal VM370R3-base CSC/VM, add multiprocessor back in, initially for online sales&marketing HONE systems so they can upgrade 158s&168s to 2-CPU systems (getting twice throughput of 1-CPU systems).
Also after FS implodes, Endicott talks me into doing analysis for the 6kbytes highest executed kernel code for translation to microcode for ECPS, about 1:1 ratio for 10 times speedup. I was also asked to help with 16-CPU 370 machine and we con the 3033 processor engineers into working on it in their spare time. Everybody thought it was great until somebody tells the head of POK that it could be decades before POK's favorite son operating system ("VS2/MVS") has (effective) 16-CPU support (MVS docs had 2-CPU only 1.2-1.5 times the throughput of 1-CPU, with overhead increasing non-linear as CPUs increase, POK doesn't ship 16-CPU system until after turn of century). Head of POK then invites some of us to never visit POK again and directs the 3033 processor engineers heads down and no distractions.
I then transfer out to SJR on west coast and get to wander around silicon valley datacenters, including disk bldg14/engineering and bldg15/product test across the street. They were running 7x24, pre-scheduled, stand-alone test and had mentioned they tried MVS, but had 15min MTBF (in that environment). I offer to rewrite I/O supervisor making it bullet proof and never fail, allowing any amount of ondemand, concurrent testing ... greatly improving productivity.
Bldg15 gets the 1st engineering 3033 outside POK processor engineering. Testing only took percent of two CPU, so we scrounge up a 3830 disk controller and string of 3330 drives and put up our own private online service.
CSC posts
https://www.garlic.com/~lynn/subtopic.html#545tech
Future System posts
https://www.garlic.com/~lynn/submain.html#futuresys
CP67L, CSC/VM, SJR/VM posts
https://www.garlic.com/~lynn/submisc.html#cscvm
getting to play disk engineer in bldgs 14&15 posts
https://www.garlic.com/~lynn/subtopic.html#disk
--
virtualization experience starting Jan1968, online at home since Mar1970
From: Lynn Wheeler <lynn@garlic.com> Subject: IBM 360&370 Experience Date: 27 Mar, 2026 Blog: Facebookre:
1980, IBM STL (since renamed SVL) was bursting at the seams and 300 people from IMS group were moving to offsite bldg with dataprocessing back to STL datacenter. They had tried "remote" 3270 support and found the human factors totally unacceptable. I got con'ed into doing channel-extender support so channel-attached 3270 controllers could be placed at the off-site bldg ... resulting in no perceptible human factors difference between off-site and inside STL. An unintended consequence was mainframe system throughput increased 10-15%. STL system configurations had large number of 3270 controllers spread all across channels shared with 3830/3330 disks ... and significant 3270 controller channel busy overhead was effectively (for same amount 3270 I/O) being masked by the channel extender (resulting in improved disk throughput). Then there was consideration to use channel extenders for all 3270 controllers (even those located inside STL).
This was about the same time studies published that quarter second response improved productivity. 70s 3272/3277 had .086secs hardware response and my operating systems for internal datacenters were getting .11sec interactive response (.196sec response seen by humans). Introduction of 3278 moved a lot of electronics back into 3274 (reducing 3278 manufacturing costs) but driving up coax protocol latency for .3-.5sec hardware response. Letters to the 3278 product administrator complaining, got response that 3278 wasn't intended for interactive computing, but data entry (MVS/TSO didn't see the difference since rare MVS/TSO had even 1sec system interactive response).
1988, branch office asked if I could help LLNL (national lab) with
standardize some serial stuff they were working with that becomes
fibre-channel standard ("FCS", including some stuff I had done in
1980, initial 1gbit transfer, full-duplex, aggregate 200mbyte/sec)
https://en.wikipedia.org/wiki/Fibre_Channel
Then POK finally announces their serial stuff in the 90s as ESCON (when it was already obsolete), initially 10mbytes/sec, upgraded to 17mbytes/sec. Then some POK engineers become involved with "FCS" and define a heavy-weight FCS protocol that drastically cuts native throughput, eventually ships as FICON.
Around 2010 was a max configured z196 published "Peak I/O" benchmark getting 2M IOPS using 104 FICON (20K IOPS/FICON). About the same time, a "FCS" was announced for E5-2600 server blade claiming over million IOPS (two such FCS with higher throughput than 104 FICON, running over FCS). Note IBM docs has SAP (system assist processors that do actual I/O) CPUs be kept to 70% ... or 1.5M IOPS ... also no CKD DASD have been made for decades (just simulated on industry fixed-block devices). Industry benchmark, number of program iterations compared to industry MIPS/BIPS standard platform:
2010 max configured z196: 50BIPS, 80cores, 625MIPS/core 2010 E5-2600 server blade, two 8-core chips, 500BIPS, 31BIPS/core
channel extender posts
https://www.garlic.com/~lynn/submisc.html#channel.extender
FCS &/or FICON posts
https://www.garlic.com/~lynn/submisc.html#ficon
--
virtualization experience starting Jan1968, online at home since Mar1970
--
previous, next, index - home